qt
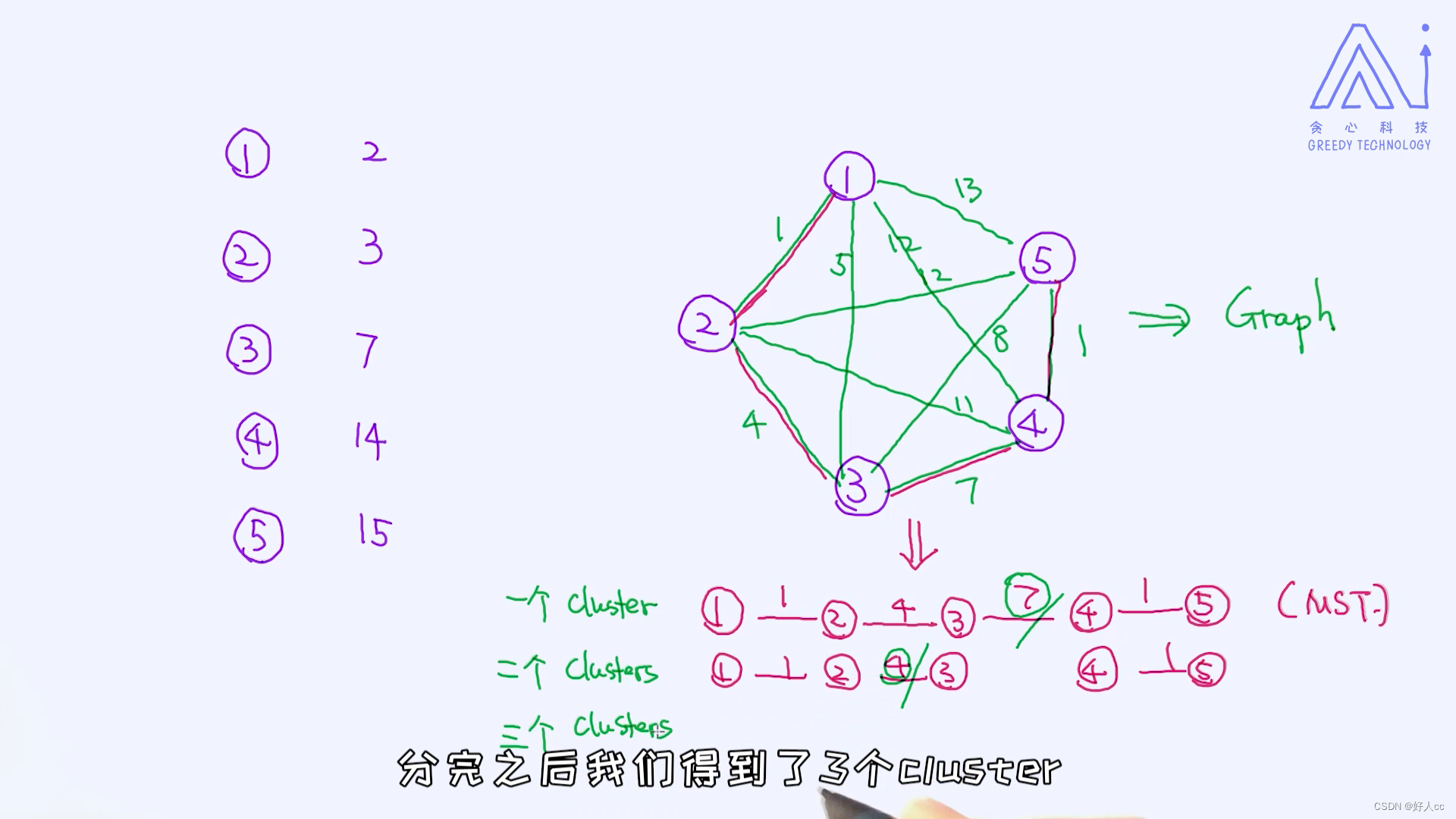
最近点对问题
机制与策略
emmc
目标检测
RDF三元组
最优假彩色合成
hbase调优
labview
matlab入门案例
volatile
微信授权功能
repalce
katz中心性
能源
寄生-捕食算法
天气App
memory
cron
antdb数据库
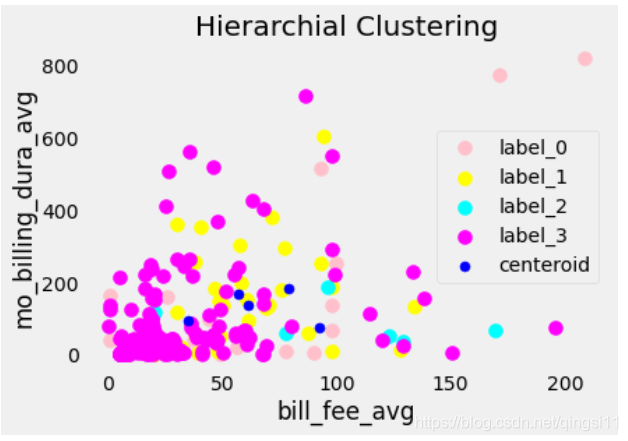
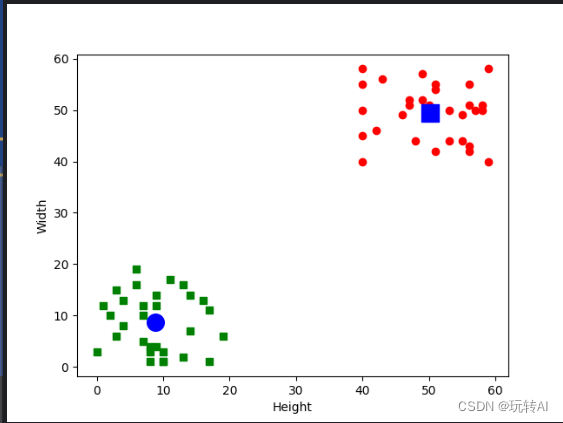
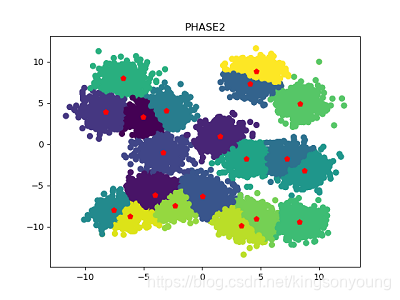
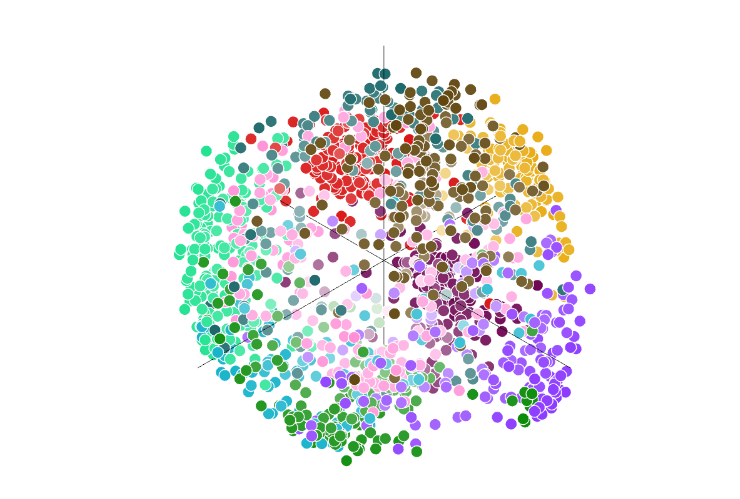
聚类
2024/4/11 15:13:39
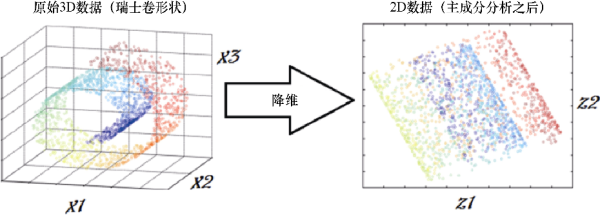
统计学补充概念10-PCA主成分分析
概念
主成分分析(Principal Component Analysis,PCA)是一种常用的降维技术,用于减少数据集的维度并提取数据中的主要信息。它通过线性变换将原始数据投影到新的坐标系中,使得新坐标系的方差最大化,从而捕捉…
聚类算法评价指标——基于DBI指数的k-means算法(python代码)
文章目录1 DBI指数介绍2 优点3 定义值3.1 SiS_iSi:表示第i类中,数据点的分散程度3.2 MijM_{ij}Mij:表示第i类与第j类的距离3.3 RijR_{ij}Rij:表示第i类和第j类的相似度3.4 R‾\overline{R}R:DBI指数,…
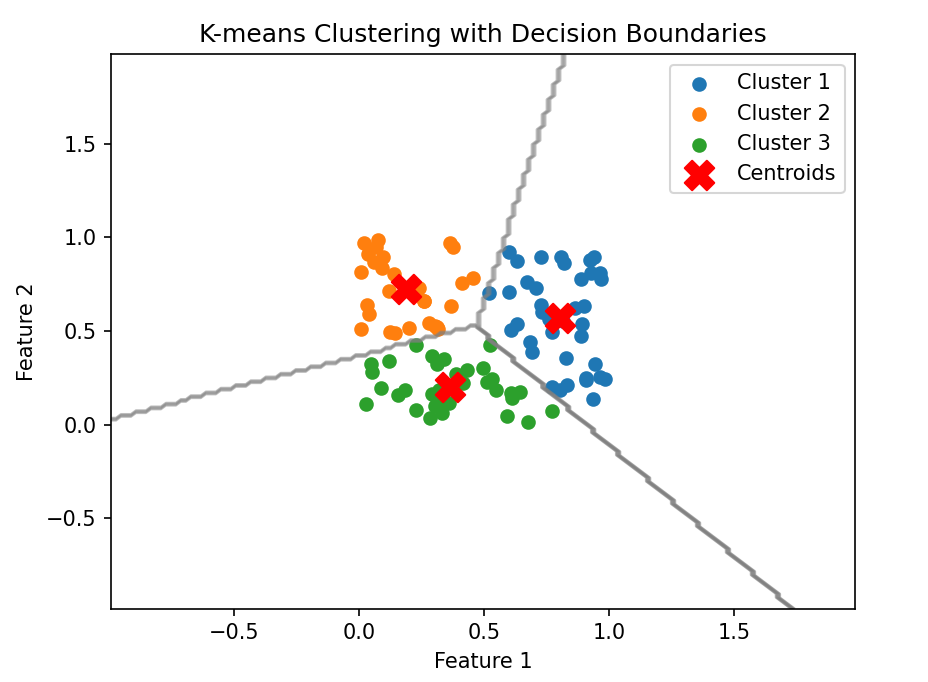
机器学习第12天:聚类
文章目录
机器学习专栏
无监督学习介绍
聚类
K-Means
使用方法
实例演示
代码解析
绘制决策边界
本章总结 机器学习专栏 机器学习_Nowl的博客-CSDN博客 无监督学习介绍
某位著名计算机科学家有句话:“如果智能是蛋糕,无监督学习将是蛋糕本体&a…

Python用 tslearn 进行时间序列聚类可视化
全文链接:https://tecdat.cn/?p33484 我们最近在完成一些时间序列聚类任务,偶然发现了 tslearn 库。我很想看看启动和运行 tslearn 已内置的聚类有多简单,结果发现非常简单直接(点击文末“阅读原文”获取完整代码数据)…
文本聚类算法之K-means算法的python实现
一、算法简介 算法接受参数k,然后将事先输入的n个数据对象划分为k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高;而不同聚类中的对象相似度较小。聚类相似度是利用各聚类中对象的均值所获得的一个“中心对象”来进行计算的。 基…
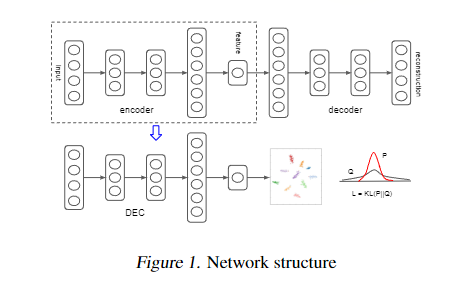
【数据聚类|深度聚类】Unsupervised Deep Embedding for Clustering Analysis(DEC)论文研读
DEC算法由两部分组成 第一部分会预训练一个SDAE模型;第二部分选取SDAE模型中的Encoder部分,加入聚类层,然后最小化KL散度进行训练聚类Absratct
提出了一种利用深度神经网络同时进行表征学习和聚类分配的方法,称之为深度嵌入聚类。该方法学习从数据空间到低纬空间的映射,并…
【Python机器学习】零基础掌握SpectralCoclustering聚类
否曾经面临过需要将大量信息或数据进行有意义分组的问题?
在我们日常生活和工作中,经常会遇到需要将大量的信息或数据进行分类或分组的需求。比如说你是一名教育机构的数据分析师,每年都有大量的学生评价和课程反馈需要处理。想找到一个方式能够同时考虑到学生和课程的特性…

多视图聚类的论文阅读
当聚类的方式使用的是某一类预定义好的相似性度量时, 会出现如下情况:
数据聚类方面取得了成功,但它们通常依赖于预定义的相似性度量,而这些度量受原始方法的影响:当输入维数相对较高时,往往是无效的。
1. Deep Mult…

【模式识别】探秘聚类奥秘:K-均值聚类算法解密与实战
🌈个人主页:Sarapines Programmer🔥 系列专栏:《模式之谜 | 数据奇迹解码》⏰诗赋清音:云生高巅梦远游, 星光点缀碧海愁。 山川深邃情难晤, 剑气凌云志自修。 目录
🌌1 初识模式识…
模糊C均值聚类(FCM)python
目录
一、模糊C均值聚类的原理
二、不使用skfuzzy的python代码
三、 使用skfuzzy的python代码 一、模糊C均值聚类的原理 二、不使用skfuzzy的python代码
import numpy as np
import random
import matplotlib.pyplot as plt
plt.rcParams[font.sans-serif][SimHei]
plt.r…
计及源荷不确定性的综合能源生产单元运行调度与容量配置优化研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…

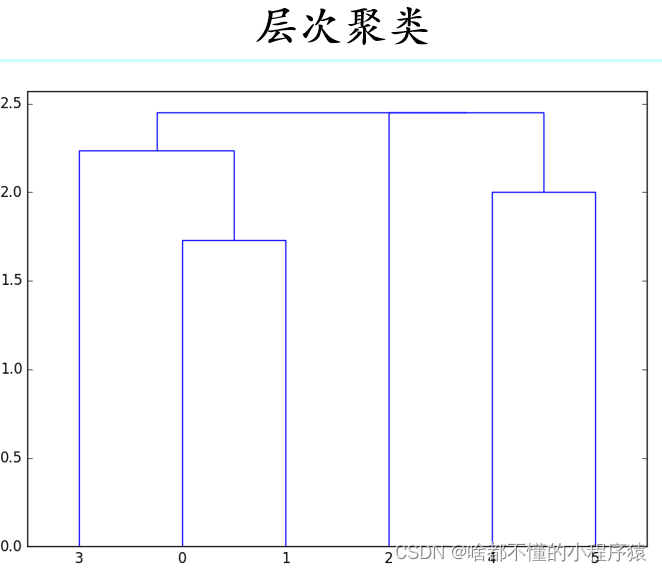
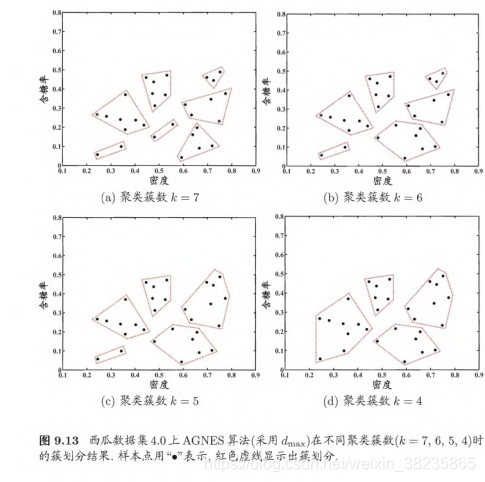
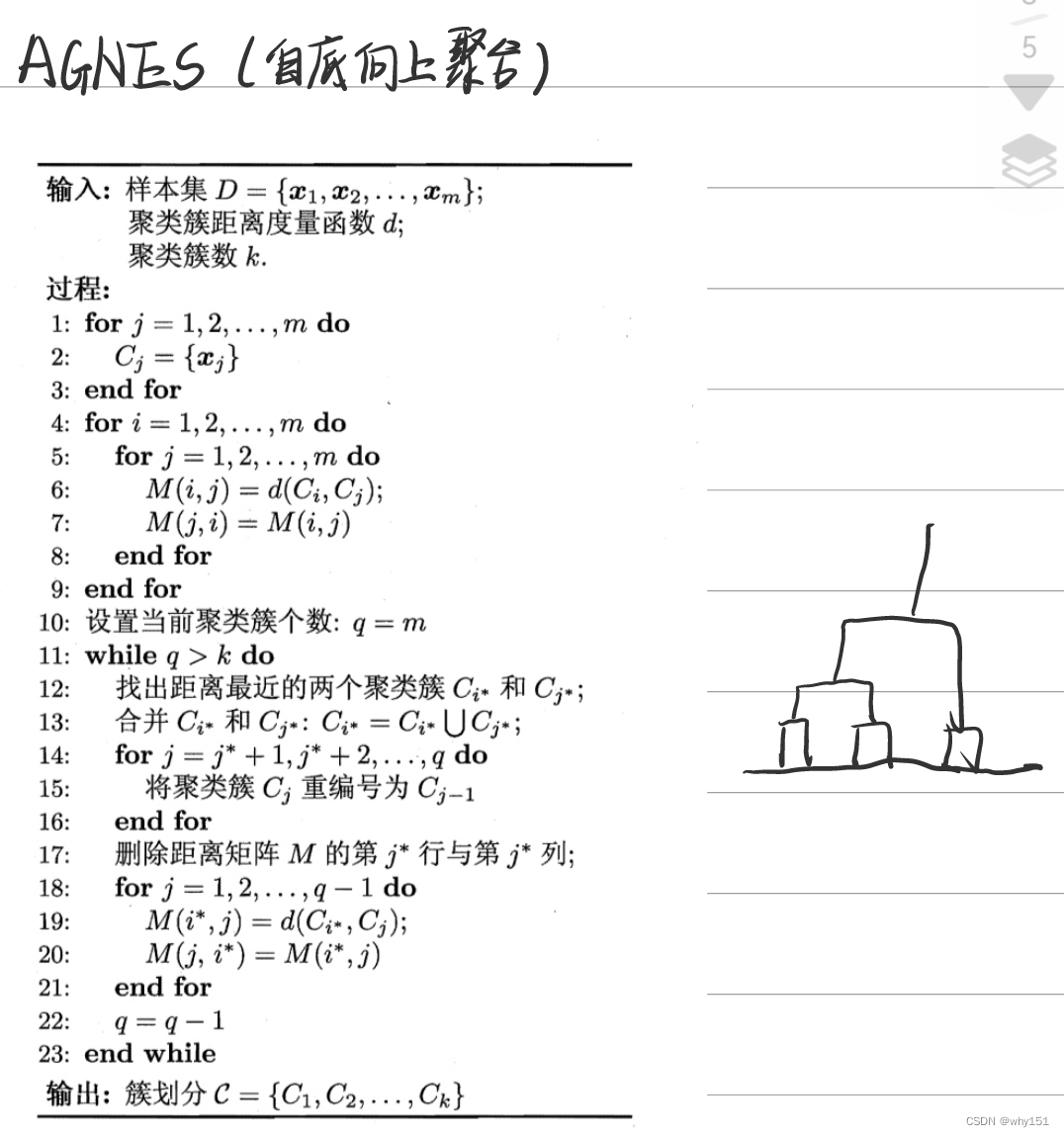
机器学习:图文详解层次聚类AGNES算法(附Python实现)
目录0 写在前面1 层次聚类2 簇间距离度量3 AGNES算法4 Python实现4.1 初始化4.2 合并最近的两个簇4.3 更新距离矩阵4.4 可视化0 写在前面
机器学习强基计划聚焦深度和广度,加深对机器学习模型的理解与应用。“深”在详细推导算法模型背后的数学原理;“广…
文本聚类——文本相似度(聚类算法基本概念)
一、文本相似度
1. 度量指标:
两个文本对象之间的相似度两个文本集合之间的相似度文本对象与集合之间的相似度
2. 样本间的相似度
基于距离的度量:
欧氏距离 曼哈顿距离 切比雪夫距离 闵可夫斯基距离 马氏距离 杰卡德距离
基于夹角余弦的度量
公式…
文本聚类算法之一趟聚类(One-pass Cluster)算法的python实现
一、算法简介 一趟聚类算法是由蒋盛益教授提出的无监督聚类算法,该算法具有高效、简单的特点。数据集只需要遍历一遍即可完成聚类。算法对超球状分布的数据有良好的识别,对凸型数据分布识别较差。一趟聚类可以在大规模数据,或者二次聚类中&am…
ESDA in PySal (1) 利用 A-DBSCAN 聚类点并探索边界模糊性
ESDA in PySAL (1) 利用 A-DBSCAN 聚类点并探索边界模糊性
在本例中,我们将以柏林的 AirBnb 房源样本为例,说明如何使用 A-DBSCAN (Arribas-Bel et al., 2019)。A-DBSCAN 可以让我们做两件事: 识别高密度 AirBnb 房源集群并划定其边界探索这些边界的稳定性%matplotlib inli…
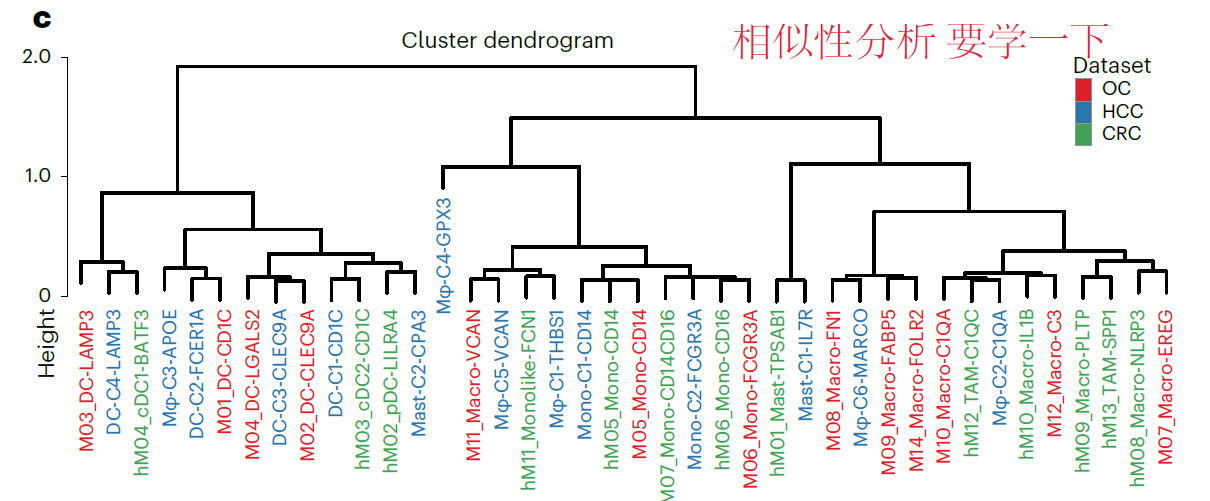
专栏十:10X单细胞的聚类树绘图
经常在文章中看到对细胞群进行聚类,以证明两个cluster之间的相关性,这里总结两种绘制这种图的方式和代码,当然我觉得这些五颜六色的颜色可能是后期加的,本帖子只总结画树状图的方法
例一
文章Single-cell analyses implicate ascites in remodeling the ecosystems of pr…
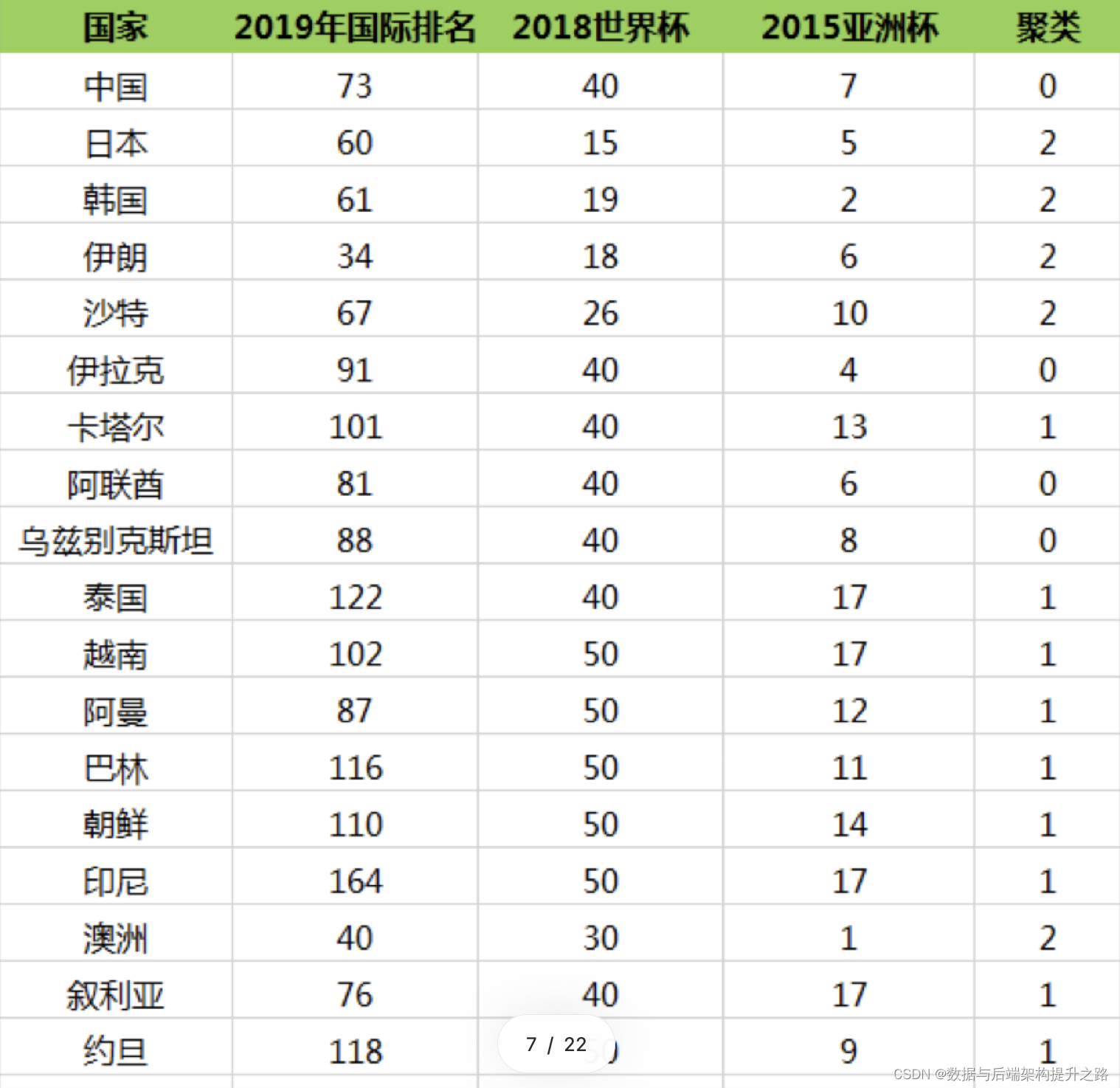
K-Means(K-均值)聚类算法理论和实战
目录
K-Means 算法
K-Means 术语
K 值如何确定
K-Means 场景
美国总统大选摇争取摆选民
电商平台用户分层
给亚洲球队做聚类
编辑
其他场景
K-Means 工作流程
K-Means 开发流程
K-Means的底层代码实现
K-Means 的评价标准 K-Means 算法
对于 n 个样本点来说&am…
《统计学习方法》 第十四章 聚类方法
聚类方法
1.聚类是针对给定的样本,依据它们属性的相似度或距离,将其归并到若干个“类”或“簇”的数据分析问题。一个类是样本的一个子集。直观上,相似的样本聚集在同类,不相似的样本分散在不同类。
2.距离或相似度度量在聚类中…

结合PCA降维的DBSCAN聚类方法(附Python代码)
目录
前言介绍:
1、PCA降维:
(1)概念解释:
(2)实现步骤:
(3)优劣相关:
2、DBSCAN聚类:
(1)概念解释&a…

python机器学习——机器学习相关概念 特征工程
目录 机器学习特征工程1.特征抽取2.特征处理2.1 归一化:传统精确小数据2.2 标准化:大多数情况 3.数据降维3.1特征选择3.2主成分分析PCA 案例:超市订单分析 机器学习 监督学习:输入数据有特征有标签,即有标准答案 分类&…
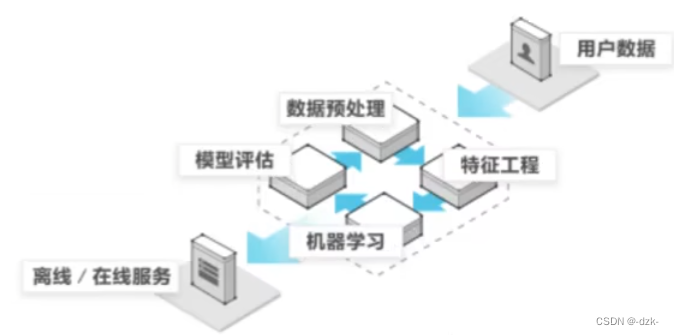
【机器学习-黑马程序员】人工智能、机器学习概述
文章目录 前言一、人工智能概述二、什么是机器学习二、机器学习算法分类三、机器学习开发流程 前言 本专栏文章为观看黑马程序员《python机器学习》所做笔记,课程地址在这。如有侵权,立即删除。 一、人工智能概述 机器学习和人工智能、深度学习的关系 机…

SPASS-聚类和判别分析
聚类与判别分析概述
基本概念
聚类分析 聚类分析的基本思想是找出一些能够度量样本或指标之间相似程度的统计量,以这些统计量为划分类型的依据,把一些相似程度较大的样本(或指标)聚合为一类,把另外一些彼此之间相似程度较大的样本又聚合为一类。根据分类对象的不同,聚类…
聚类笔记:HDBSCAN
1 算法介绍
DBSCAN/OPTICS层次聚类主要由以下几步组成 空间变换构建最小生成树构建聚类层次结构(聚类树)压缩聚类树提取簇
2 空间变换
用互达距离来表示两个样本点之间的距离 ——>密集区域的样本距离不受影响——>稀疏区域的样本点与其他样本点的距离被放大——>…

Matlab进阶绘图第8期—聚类/分类散点图
聚类/分类散点图是一种特殊的特征渲染散点图。
聚类/分类散点图通过一定的聚类、分类方法,将特征相近的离散点划分到同一个类别中,进而将每个离散点赋予类别标签,并利用不同的颜色对不同的类别进行区分。
本文使用Matlab自带的gscatter函数…
图聚类算法(Graph clustering)
综述: A Survey of Deep Graph Clustering: Taxonomy, Challenge, Application, and Open Resource A Comprehensive Survey on Community Detection with Deep Learning An Overview of Advanced Deep Graph Node Clustering
无需指定簇大小:Reinforce…
【Python机器学习】零基础掌握AgglomerativeClustering聚类
如何解决城市规划问题?
城市规划者们面临一个复杂问题:如何合理地规划土地,使商业、居民、公园和其他设施互相便利,同时又不互相干扰?解决这个问题不仅需要对土地进行精准的分类,还要考虑到土地之间的相互关系。
借助层次聚类算法(Agglomerative Clustering),规划者…
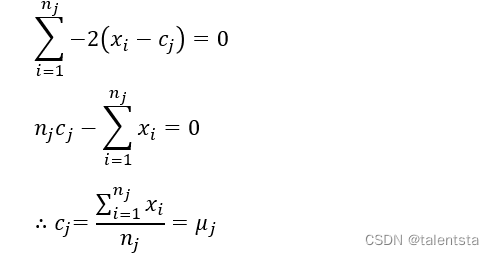
K-means聚类方法
K-means聚类的思想和原理
模型介绍
对于有监督的数据挖掘算法而言,数据集中需要包含标签变量(即因变量y的值)。但在有些场景下,并没有给定的y值,对于这类数据的建模,一般称为无监督的数据挖掘算法&#x…
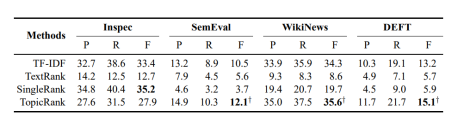
关键词抽取算法TopicRank
1、文本预处理,分词,POS
2、筛选候选词,保留最长的名词和形容词序列;
3、采用HAC(层次凝聚聚类算法)聚类;(在超过25%重叠词的情况下,认为两个候选序列是相似的…

机器学习笔记:层次聚类
1 原理
1.1 主体思路
通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。创建聚类树有自下而上合并(凝聚层次分类,agglomerative&…
【高性能计算】无监督学习之层次聚类实验
【高性能计算】基于K均值的划分聚类实验 实验目的实验内容实验步骤1、层次聚类算法1.1 层次聚类算法的基本思想1.2 层次聚类的聚类过程 2、使用Python语言编写层次聚类的源程序代码并分析其分类原理2.1 层次聚类 Python代码2.1.1 计算欧式距离函数euler_distance2.1.2 层次聚类…
【聚类】之浅谈(对比K-means跟DB-scan)
K-means需要做多组(取平均,设置k值)
DBSCAN 寻找核心对象:某个点以r(人为给予)为邻域半径画圈,如果该领域内点的数量不小于Min-pts(人为给予)则认为该点为核心对象半径选择:计算K距离找到突变点Minist:尽可能让它小(4 or 5)-1簇内即为离群点以某实际小型数据集为…

基于聚类的推荐算法笔记——以豆瓣电影为例(一)(附源代码)
基于聚类的推荐算法笔记——以豆瓣电影为例(一)(附源代码)
第一章 聚类算法介绍 基于聚类的推荐算法笔记一
第二章 数据介绍 基于聚类的推荐算法笔记二
第三章 实现推荐算法 基于聚类的推荐算法笔记三
第四章 评价推荐算法 基于聚类的推荐…

基于聚类的推荐算法笔记——以豆瓣电影为例(二)(附源代码)
基于聚类的推荐算法笔记——以豆瓣电影为例(二)(附源代码)
第一章 聚类算法介绍 基于聚类的推荐算法笔记一
第二章 数据介绍 基于聚类的推荐算法笔记二
第三章 实现推荐算法 基于聚类的推荐算法笔记三
第四章 评价推荐算法 基于聚类的推荐…

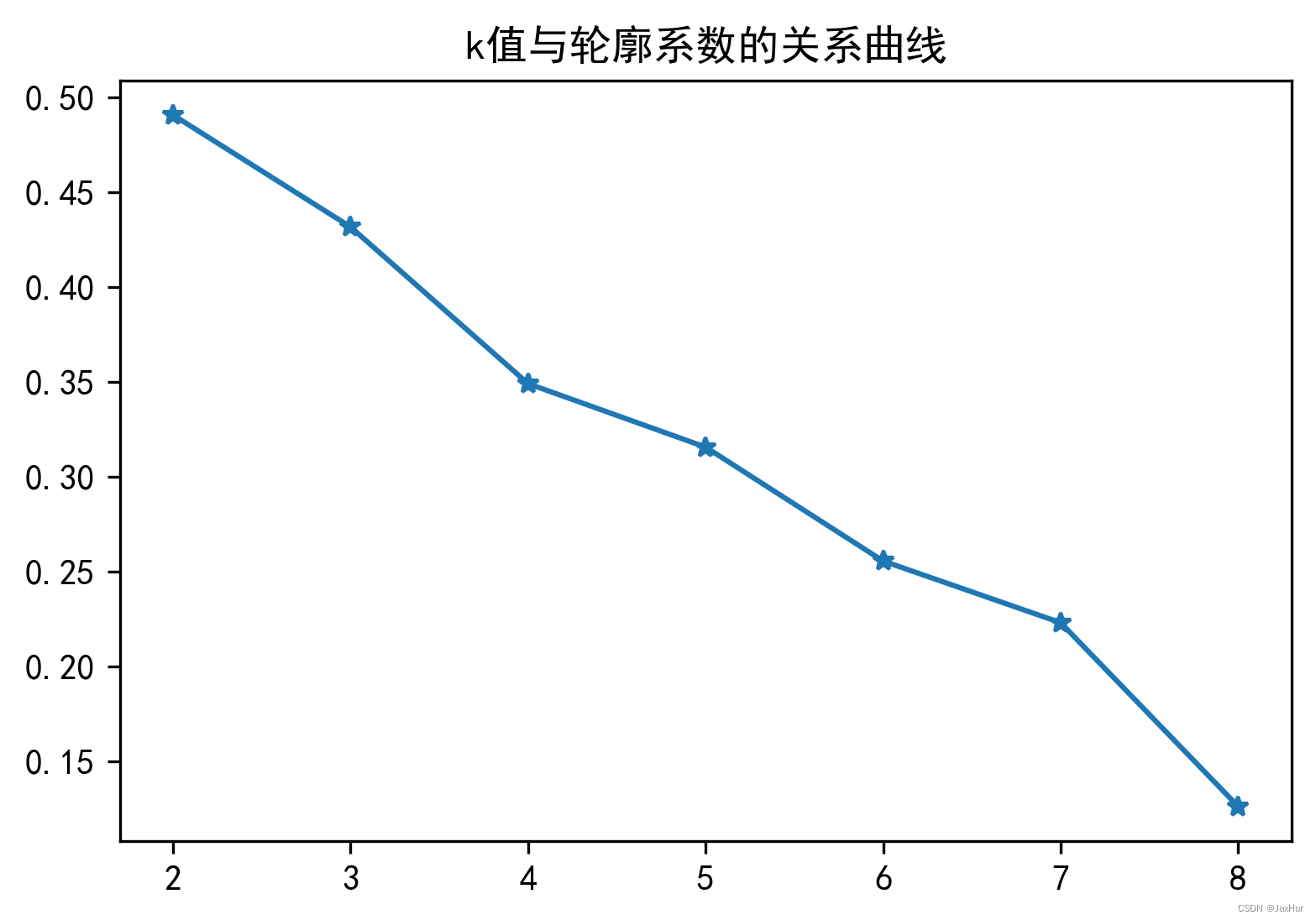
K-Means和轮廓系数
K-Means和轮廓系数
K-means(K均值)是机器学习中一种常见的无监督算法,它能够将未知标签的数据,根据它们的特征分成不同组,每一组数据又称为“簇”,每一簇的中心点称为“质心”。其基本原理过程如下&#x…

机器学习 复习四 聚类
无监督学习 衡量:处理不规则形状,噪音点
相似的物品成一类,不相似的物品不成一类
K-Means
步骤: 随机选K个聚集点 每个数据被赋值最近聚集点类别 使用每个聚集中心点更新 重复直到聚点不再移动 返回K个中心点坐标
优点&#x…

机器学习-监督性学习 2021-11-20
人工智能基础总目录 监督性学习人工智能基础总目录一、 内容介绍二、 线性回归多分类的时候-Softmax函数多分类的交叉商 cross_entrory三、 模型的评价值一、 内容介绍
线性回归 linear regression逻辑回归 logistic regressionsoftmax, cross-entropy模型评价指标
二、 线性…
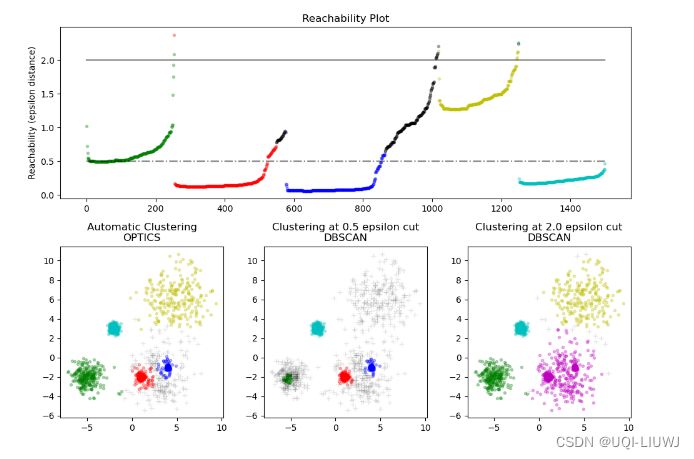
算法笔记:OPTICS 聚类
1 基本介绍
OPTICS(Ordering points to identify the clustering structure)是一基于密度的聚类算法 OPTICS算法是DBSCAN的改进版本 在DBCSAN算法中需要输入两个参数: ϵ 和 MinPts ,选择不同的参数会导致最终聚类的结果千差万别,因此DBCSAN…
机器学习中聚类算法-简单介绍
聚类算法
聚类算法: 将数据分成不同的组,如K均值(K-Means)和层次聚类(Hierarchical Clustering)。 聚类是机器学习中一类重要的无监督学习问题,其目标是将数据集中的样本划分为不同的组&#x…

scanpy 单细胞分析使用案例
参考:https://zhuanlan.zhihu.com/p/537206999 https://scanpy.readthedocs.io/en/stable/api.html
scanpy python包主要分四个模块: 1)read 读写模块、 https://scanpy.readthedocs.io/en/stable/api.html#reading 2)pp Prepr…
机器学习知识总结 —— 17.什么是聚类
文章目录什么是聚类聚类与SVM算法的区别是什么聚类算法的重要知识点常见聚类算法K-Means聚类层次聚类 (Hierarchical Clustering)DBSCAN聚类基于密度的HDBSCAN聚类的评价方式欧几里得距离曼哈顿距离余弦距离轮廓系数Calinski-Harabasz系数什么是聚类
在前面的章节,…
聚类笔记/sklearn笔记:Affinity Propagation亲和力传播
1 算法原理
1.1 基本思想
将全部数据点都当作潜在的聚类中心(称之为 exemplar )然后数据点两两之间连线构成一个网络( 相似度矩阵 )再通过网络中各条边的消息( responsibility 和 availability )传递计算出各样本的聚类中心。 1.2 主要概念
Examplar聚类中心similarity S(i…
数据分析系列 之python语言中的聚类分析
1 基础算法 (1) K-means算法:对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。 (2) K-means算法是局部最优解,初始聚类中心一般是随机选择&…

使用K-means把人群分类
1.前言
K-mean 是无监督的聚类算法 算法分类: 2.实现步骤
1.数据加工:把数据转为全数字(比如性别男女,转换为0 和 1)
2.模型训练 fit
3.预测
3.代码
原数据类似这样(source:http:img-blog.csdnimg.cn…

模式识别 4.无监督学习与聚类
主要讲啥?: 模式识别的两种方法: 我们这节课讲无监督的 数学描述是什么?: mj是第j类样本的中心,nj是第j类样本的总数,Cj代表第j类样本,m代表所有样本的中心 tr就是矩阵的意思 \
这个很复杂,一般…

模式识别 5.聚类 2
就是说,一开始先选择几个初始聚类均值,然后拿样本一个一个比较,哪个聚类离自己近就选哪个,选完一轮后更新新均值,然后继续。 模糊c均值: 聚类检验: Dunn: D-B: 一个是聚类与聚类的距…

sklearn中的聚类算法K-Means
1 概述
1.1 无监督学习与聚类算法
决策树、随机森林、逻辑回归虽然有着不同的功能,但却都属于“有监督学习”的一部分,即是说,模型在训练的时候,既需要特征矩阵XXX,也需要真实标签yyy。在机器学习中,还有…
传统机器学习聚类算法——总集篇
工作需要,涉及到一些聚类算法相关的知识。工作中需要综合考虑数据量、算法效果、性能之间的平衡,所以开启新的篇章——机器学习聚类算法篇。 传统机器学习中聚类算法主要分为以下几类:
1. 层次聚类算法 层次聚类算法是一种无监督学习算法&am…

PCL—点云数据分割
PCL—车辆点云数据分割一.算法原理二.代码实现三.结果展示一.算法原理
欧式聚类是一种基于欧氏距离度量的聚类算法,过程如下:
1.首先选取种子点,利用kd-tree对种子点进行半径r邻域搜索,若邻域内存在点,则与种子点归为…
机器学习|数学建模|数据挖掘|Data Mining|无监督分类算法|聚类分析
2022-12-20 14:43:58 什么是聚类分析?
聚类分析中的数据类型
主要聚类分析方法分类
划分方法(Partitioning Methods)
分层方法
基于密度的方法
基于表格的方法
基于模型的方法
异常分析
总结 目录
一、预备知识
二、聚…
【Python代码】K-means聚类模型
一、简介
K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有…
【Python机器学习】零基础掌握AffinityPropagation聚类
如何解决社交媒体上的好友推荐问题?
想象一下,一个社交媒体平台希望提供更加精准的好友推荐功能,让用户能更容易地找到可能成为好友的人。这个问题看似简单,但当面对数百万甚至数千万的用户时,手动进行好友推荐就变得几乎不可能。
解决这个问题的一个方案就是使用机器学…

搜索引擎点击日志聚类实现相关搜索
组里经常招实习生, 在技术问题问得差不多的时候, 我经常会问他们一个问题:‘百度的相关搜索,你会如何设计实现?’ 主要想看下实习生会有哪些思路,看看思路是否广,方法是否多, 没有…
Machine Learning - Coursera 吴恩达机器学习教程 Week8 学习笔记(Unsupervised Learning)
无监督学习
本周课程开始进入无监督学习。
一个重要应用是聚类问题:
K-Means算法
随机找K个中心点(红和蓝),将样本标记为最近的中心点: 计算每个类别里样本的平均值(mean),作为…
利用自编码器(AutoEncoder, AE),对图像或信号进行降维和聚类,并将隐空间在2D空间中可视化,通过Matlab编程实现
自编码器(AutoEncoder)是一种无监督学习方法,用于对数据进行降维和聚类。它通过学习输入数据的低维表示来重构输入数据,同时保持数据的分布不变。在图像或信号处理中,自编码器可以用于提取特征、压缩数据以及可视化隐藏空间。
首先,我们需要构建一个自编码器模型。自编码…
标准误与聚类稳健标准误的理解
1 标准误
1.1 定义
标准误(Standard Error)是用来衡量统计样本估计量(如均值、回归系数等)与总体参数之间的差异的一种统计量。标准误衡量了样本估计量的变异程度,提供了对总体参数的估计的不确定性的度量。标准误越…

无监督学习-聚类算法(k-means)
无监督学习-聚类算法
1、聚类介绍
1.1、聚类作用
知识发现异常值检测特征提取 数据压缩的例子 1.2、有监督与无监督学习
有监督:
给定训练集X和标签Y选择模型 学习(目标函数的最优化)生成模型(本质上是一组参数、方程&#x…
机器学习读书笔记之8 - 聚类
聚类(Cluster) 是无监督学习的一种,与分类相区别的地方在于: 1. 分类的目的在于将数据进行明确的归属划分,聚类 的目的只是使同一类对象的相似度尽可能大; 2. 聚类 作为非监督学习,不需要训练和…
MATLAB索引超出矩阵维度,求大神指点错误!
MATLAB索引超出矩阵维度,求大神指点错误!
MATLAB索引超出矩阵维度,求大神指点错误!
最近在做k均值动态聚类的时候,matlab提示索引超出矩阵维度,不知道问题出在哪了。
代码
N1 50; N2 N1; N3N1; % 设置…

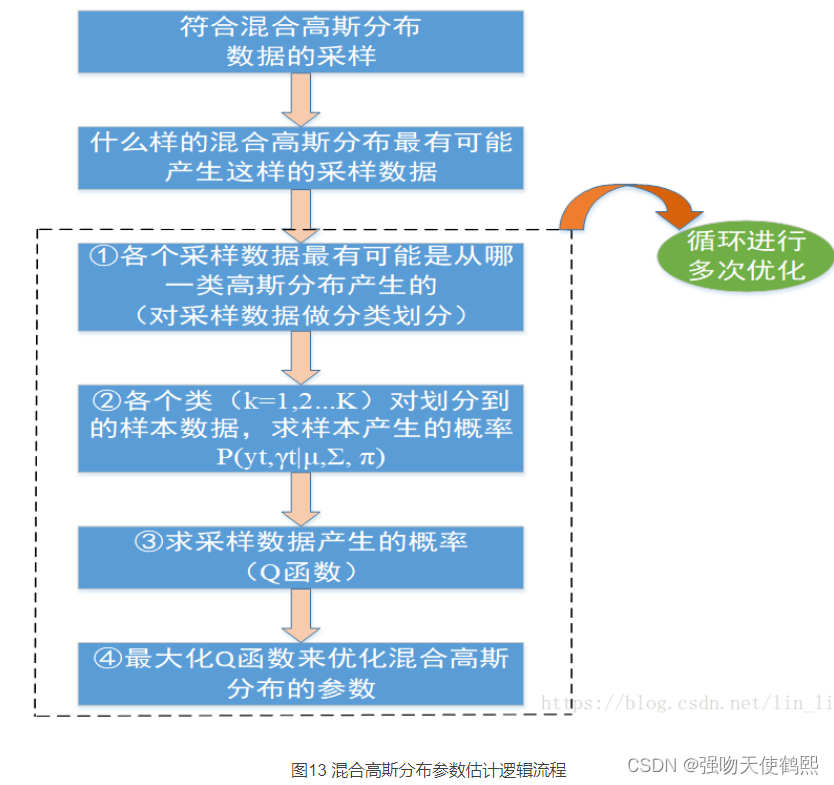
EM 算法与 GMM 模型
EM算法与GMM模型 – 潘登同学的Machine Learning笔记 文章目录EM算法与GMM模型 -- 潘登同学的Machine Learning笔记GMM模型单高斯模型 GM的参数估计(本质是最大似然估计)混合高斯分布 GMM 的参数估计举个栗子GMM 混合高斯分布分两步求解 GMM算法总结EM算…

Data Mining_聚类分析分类器关联规则回归分析 (Python)
Data mining
一种从大量数据中提取知识的过程,它涉及到统计学、机器学习和人工智能等多个领域。 它通常使用计算机程序来分析数据,发现潜在的关系或规则,并产生有用的信息。
常见技术
包括:
聚类分析、分类器、关联规则挖掘回…

聚类系列(一)——什么是聚类?
目前在做聚类方面的科研工作, 看了很多相关的论文, 也做了一些工作, 于是想出个聚类系列记录一下, 主要包括聚类的概念和相关定义、现有常用聚类算法、聚类相似性度量指标、聚类评价指标、 聚类的应用场景以及共享一些聚类的开源代码 下面正式进入该系列的第一个部分ÿ…

机器学习练习之k均值
k-means属于聚类分析的其中一种算法,聚类分析在机器学习、数据挖掘、模式识别、决策支持和图像分割中有广泛的应用。聚类是无监督的分类方法,所谓无监督就是没有给定训练数据的标签信息,所以聚类出来的结果的类别是未定义的,而分类…
《统计学习方法》聚类代码实现
层次聚类假设类别之间存在层次结构,将样本聚到层次化的类中层次聚类又有聚合或自下而上、分裂或自上而下两种方法。
聚合聚类开始将每个样本各自分到一个类;之后将相距最近的两类合并,建立一个新的类,重复此操作直到满足停止条件…

贝叶斯滤波计算4d毫米波聚类目标动静属性
机器人学中有些问题是二值问题,对于这种二值问题的概率评估问题可以用二值贝叶斯滤波器binary Bayes filter来解决的。比如机器人前方有一个门,机器人想判断这个门是开是关。这个二值状态是固定的,并不会随着测量数据变量的改变而改变。就像门…

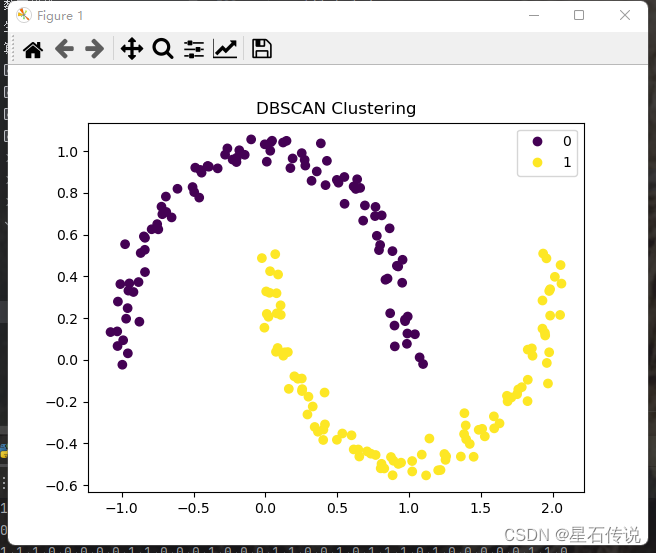
利用鸢尾花数据集复现DBSCAN密度聚类算法
生成数据集
from sklearn import datasets
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
data datasets.load_iris()[:,:2].tolist()
data为了后续可视化方便,故此处选择生成二维数据集,毕竟画二维散点图不…

12 聚类模型 -- 机器学习基础理论入门
12 聚类模型 – 机器学习基础理论入门
4.1 聚类问题介绍
定义
聚类分析又称群分析,目标时将样本划分为紧密关系的子集或簇 应用
聚类分析在实际中应用非常广泛,如:市场细分、社交圈分析、天体数据分析等
聚类要求
聚类分析的目标时将样…

机器学习技术-k均值划分聚类算法
1.聚类分析: 聚类(Clustering)是将数据划分成群组(簇)的过程,根据数据本身的自然分布性质,数据变量之间存在着程度不同的相似性(亲疏关系),按照一定的准则将相似的数据聚集成簇(Cluster)。很多机器学习算法可以分为有监督学习和无…
机器学习技术-层次聚类算法(组平均)-综合层次聚类方法(BIRCH、CURE)
基于层次的聚类方法,是对给定的数据进行层次的分解,直到某种条件满足为止。首先将数据点组成一颗聚类树,根据层次,自底向上或是自顶向下分解。层次的方法可以分为凝聚的方法和分裂的方法。 凝聚的方法,也称为自底向上的…
数据挖掘(4.1)--分类和预测
目录
前言
一、分类和预测
分类
预测
二、关于分类和预测的问题
准备分类和预测的数据
评价分类和预测方法
混淆矩阵
评估准确率
参考资料 前言 分类:离散型、分类新数据 预测:连续型、预测未知值 描述属性:连续、离散 类别属性&am…

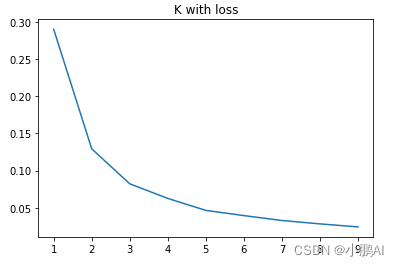
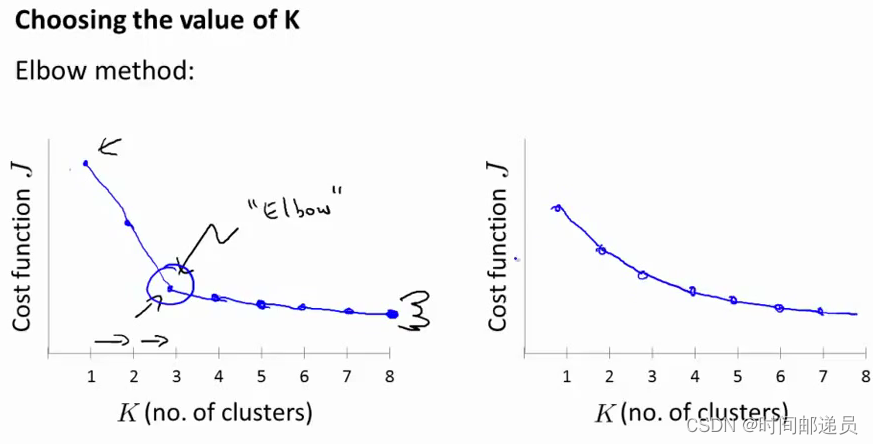
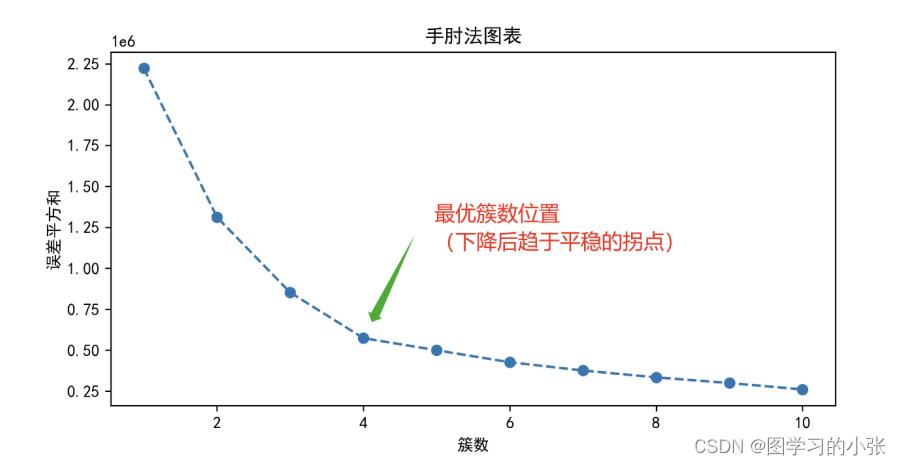
python机器学习——Kmeans之K值选取实现(肘部观察法)
Kmeans之K值选取实现# 导入必要的工具包。
import numpy as np
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
import matplotlib.pyplot as plt
# 使用均匀分布函数随机三个簇,每个簇周围10个数据样本。
cluster1 np.random.unif…

凝聚层次聚类及DBscan算法详解与Python实例
凝聚层次聚类及DBscan算法详解与Python实例 凝聚层次聚类DBscan算法实例演示 在本篇博客中,我们将深入探讨凝聚层次聚类(Agglomerative Hierarchical Clustering)和DBscan算法,并通过Python实例演示它们的应用。这两种算法都属于聚…

熵,线性规划,半监督自监督聚类打标签
1.熵 信息熵是消除不确定性所需信息量的度量。 信息熵就是信息的不确定程度,信息熵越小,信息越确定。 对象的信息熵是正比于它的概率的负对数的,也就是 I©−log(pc) 其中n为事件的所有可能性。 为什么使用交叉熵?在机器学习…
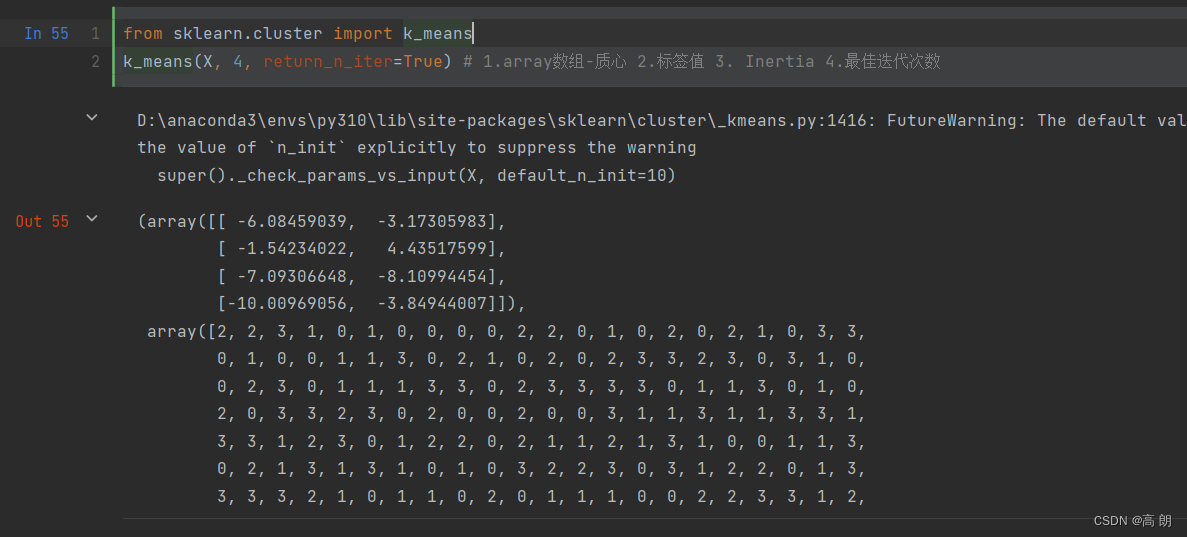
【机器学习】聚类算法Kmeans
文章目录 聚类Kmeans时间复杂度 sklearn.cluster.KMeansn_clusters模型评估指标轮廓系数卡林斯基-哈拉巴斯指数 init & random_state & n_init:初始质心max_iter & tolk_means函数 聚类 聚类就是按照某个特定标准(如距离准则)把一个数据集分割成不同的类…
使用 Numpy 实现 K-Means 聚类算法
K-Means 算法原理链接. 使用时,实例化类后,只需关注 fit(), predict(),传入数据类型为np.array,形状为 N x M。 class MyKMeans:labels_ [] # fit 后每类数据的标签cluster_centers_ None # N x M, 聚类中心个数__cluster_cen…
聚类效果评价指标:MI, NMI, AMI(互信息,标准化互信息,调整互信息)
聚类效果评价指标:MI, NMI, AMI(互信息,标准化互信息,调整互信息)
简介
在无监督学习中,常见的两种任务为聚类与降维。这里给出三个聚类效果评价指标:互信息,标准化互信息…

传统机器学习(四)聚类算法DBSCAN
传统机器学习(四)聚类算法DBSCAN
1.1 算法概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。
该算法将具有足够密度的区域划分为簇,并在…

读论文——“时间序列预测方法综述”
文章目录1 什么是时间序列?2 时间预测方法的核心3 时间序列数据的特点4 相关的时间序列参数模型4.1 移动平均模型(Moving Average, MA)4.2 自回归模型(Autoregressive Models, AP)4.3 自回归移动平均模型5 传统的时间序列预测方法6 基于机器学习的时间序列预测方法6…
机器学习 K-Means 实现文本聚类 2021-10-30
人工智能总目录 新闻头条数据进行聚类分析人工智能总目录1. 数据集信息2. 数据预处理2.1 为向量化表示进行前处理2.2 TF-IDF2.3 Stemming2.4 Tokenizing2.5 使用停用词、stemming 和自定义的 tokenizing 进行 TFIDF 向量化3 K-Means 聚类3.1 使用手肘法选择聚类簇的数量3.2 Clu…
08无监督学习——聚类
1.什么是聚类任务?
类别:无监督学习 目的:通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。
1.1K均值聚类
步骤:
随机选取样本作为初始均值向量(初始值:k的值【即几个簇】)分别…
15. 机器学习——聚类
机器学习面试题汇总与解析——聚类
本章讲解知识点 什么是聚类K-means 聚类算法均值偏移聚类算法DBSCAN 聚类算法高斯混合模型(GMM)的期望最大化(EM)聚类层次聚类算法本专栏适合于Python已经入门的学生或人士,有一定的编程基础。 本专栏适合于算法工程师、机器学习、图像…
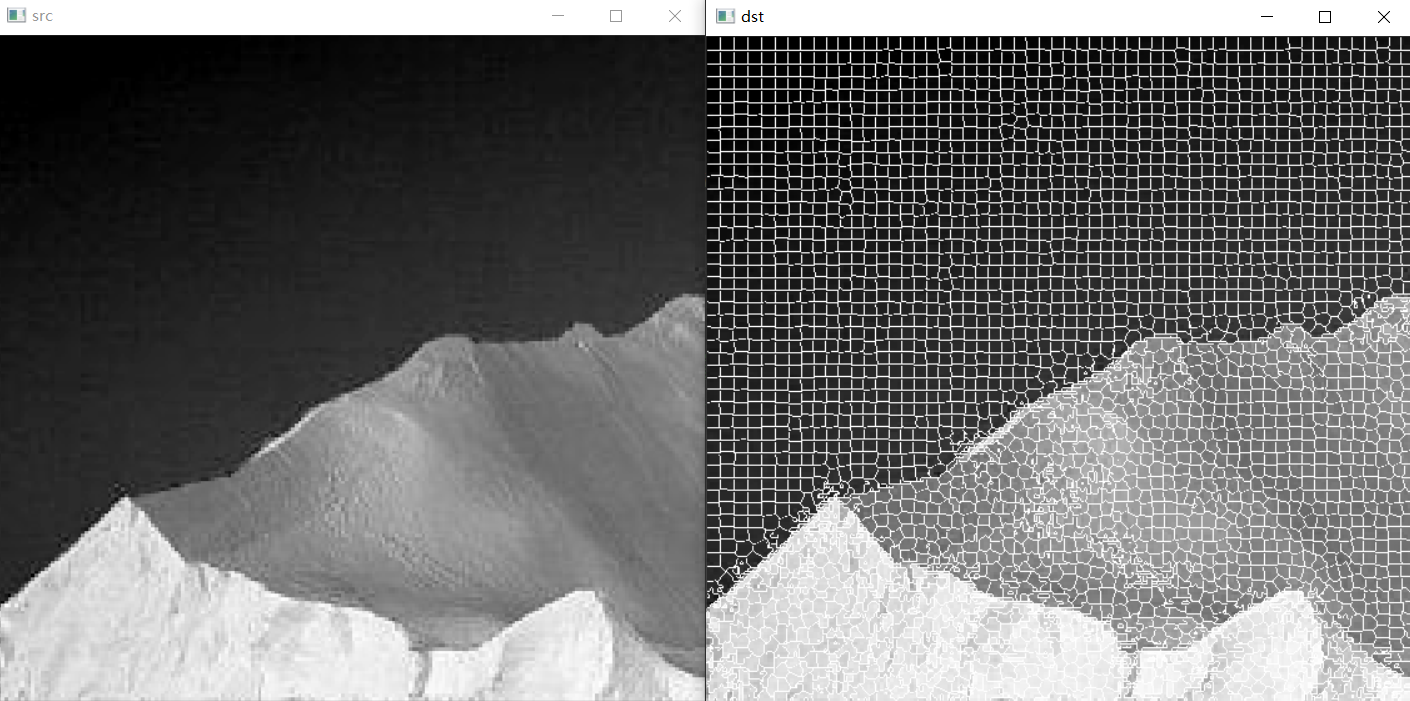
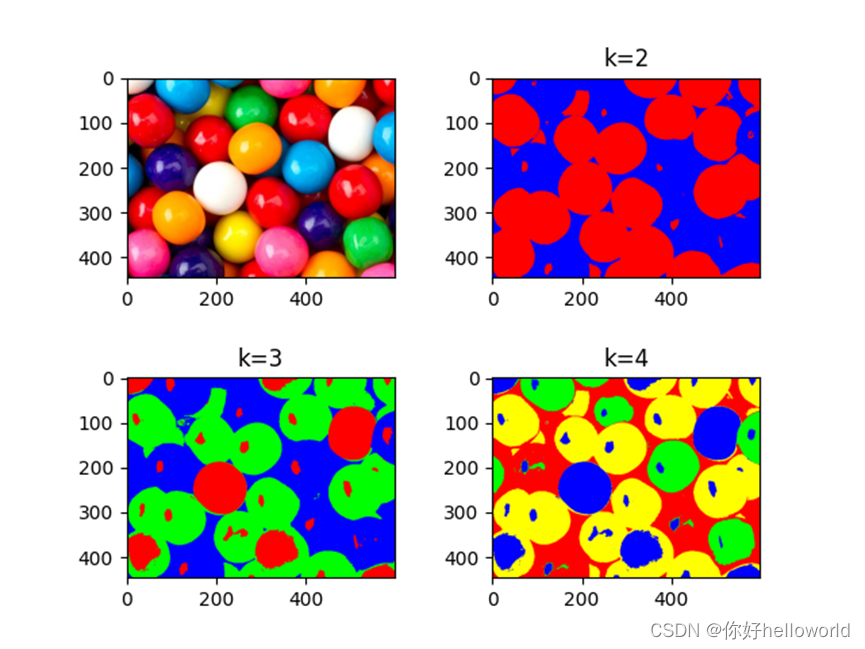
【图像处理笔记】图像分割之聚类和超像素
🚀 优质资源分享 🚀
学习路线指引(点击解锁)知识定位人群定位🧡 Python实战微信订餐小程序 🧡进阶级本课程是python flask微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一…

Open3D聚类算法
按照官网的例子使用聚类,发现结果是全黑的。 经过多次测试发现 eps3.3, min_points1这里是关键 min_points必须等于1否则无效果 import time
import open3d as o3d;
import numpy as np;
import matplotlib.pyplot as plt#坐标
mesh_coord_frame o3d.geometry.Tria…

数据算法之层次聚类——(待完善)
1.数据挖掘入门笔记——层次聚类 ( 浮光掠影)
2.聚类算法:Hierarchical Clustering层次聚类
3.一文读懂层次聚类(Python代码) 4.层次聚类 5.聚类分析(三) 层次聚类及matlab程序 5.聚类算法之层次聚类(…
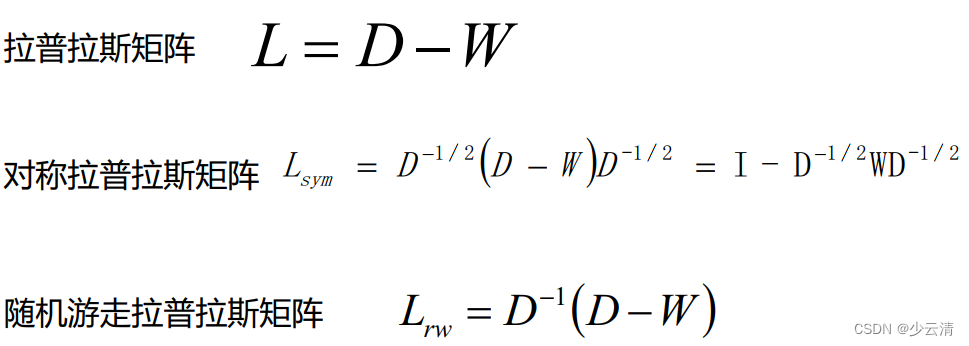

聚类算法——kmeansDbscan
1、聚类概念 两种算法如下: k指定多少就会得到多少簇,比如上图若k3,就会把这图上的点聚成三堆。 质心是为了迭代。 标准化:使x,y上的数据都在比较小的范围浮动 优化:对于每一簇,样本上的点到中心…
机器学习之聚类算法一
文章目录 一、简述1. 有监督和无监督的区别,以及应用实例2. 为什么是聚类3. 聚类都有哪些 二、k-means1.k-means,核心思想是什么1. 同一个簇内的样本点相似度较高,这里的相似度高,具体指什么2.问题来了:同一簇之间相似…
DEC 深度编码聚类函数
2. 辅助目标函数
要使用输入 (bt, groups, embed_dim) 计算 DEC 模型的目标分布,关键部分是使用软分配 q ,其形状为 (bt, groups, max_cluster) 。这里, max_cluster 是您要定位的集群数量。当您沿该维度执行聚类时,需要跨 group…
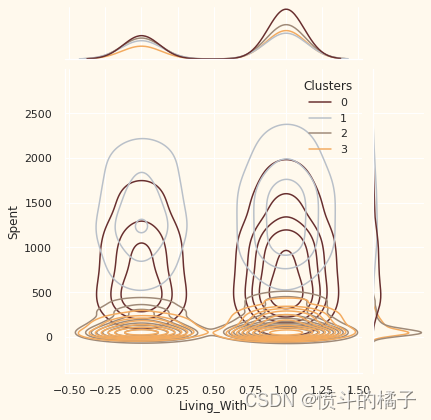
案例系列:营销模型_客户细分_无监督聚类
案例系列:营销模型_客户细分_无监督聚类
import numpy as np # 线性代数库
import pandas as pd # 数据处理库,CSV文件的输入输出(例如pd.read_csv)/kaggle/input/customer-personality-analysis/marketing_campaign.csv在这个项…
机器学习---使用 EM 算法来进行高斯混合模型的聚类
1. 指定k个高斯分布參数
导包
import math
import copy
import numpy as np
import matplotlib.pyplot as pltisdebug False
全局变量 isdebug可以用来控制是否打印调试信息。当 isdebug 为 True 时,代码中的一些调试信
息将被打印出来,方便进行调试…
基于决策树、随机森林和层次聚类对帕尔默企鹅数据分析
作者:i阿极 作者简介:数据分析领域优质创作者、多项比赛获奖者:博主个人首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒关注哦&#x…
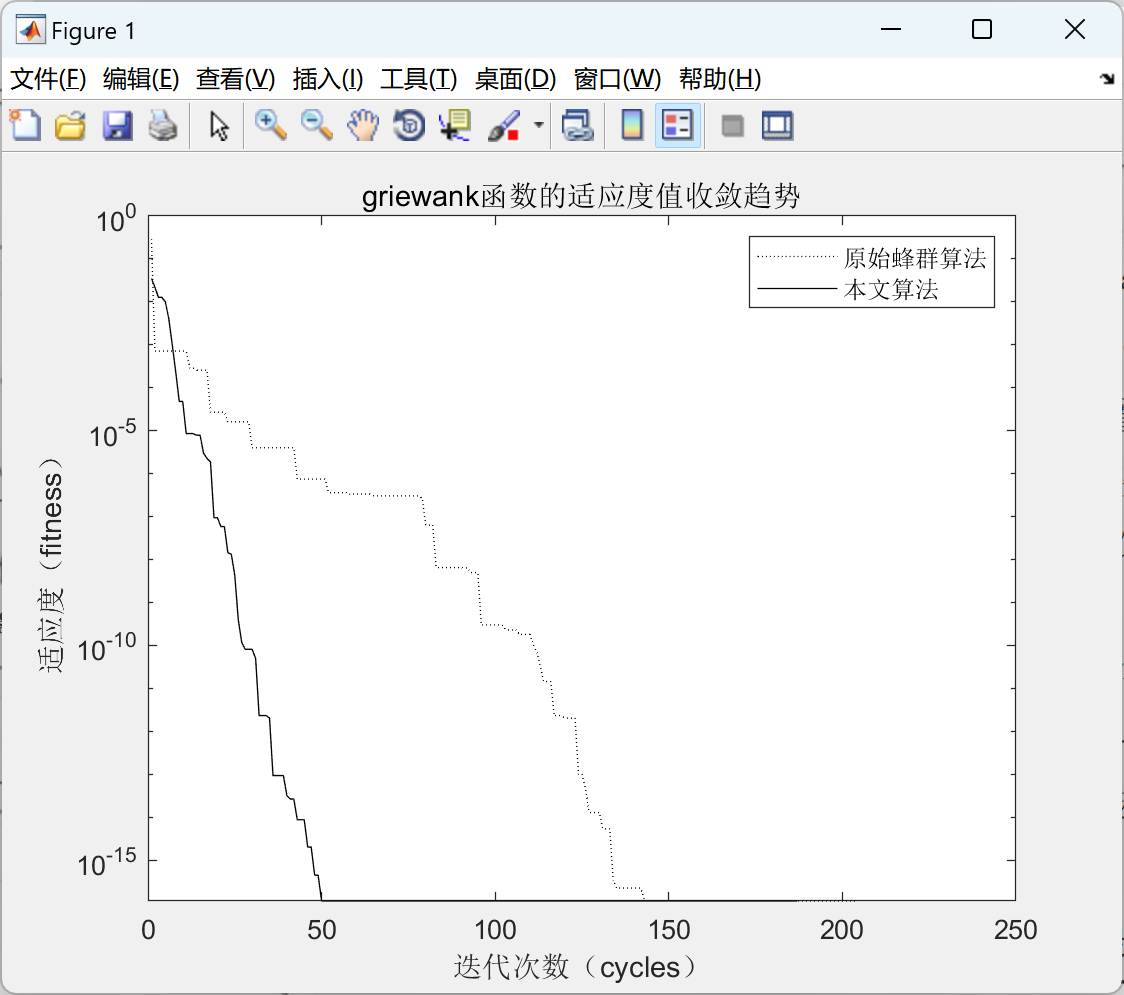
基于改进人工蜂群算法的 K 均值聚类算法(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…
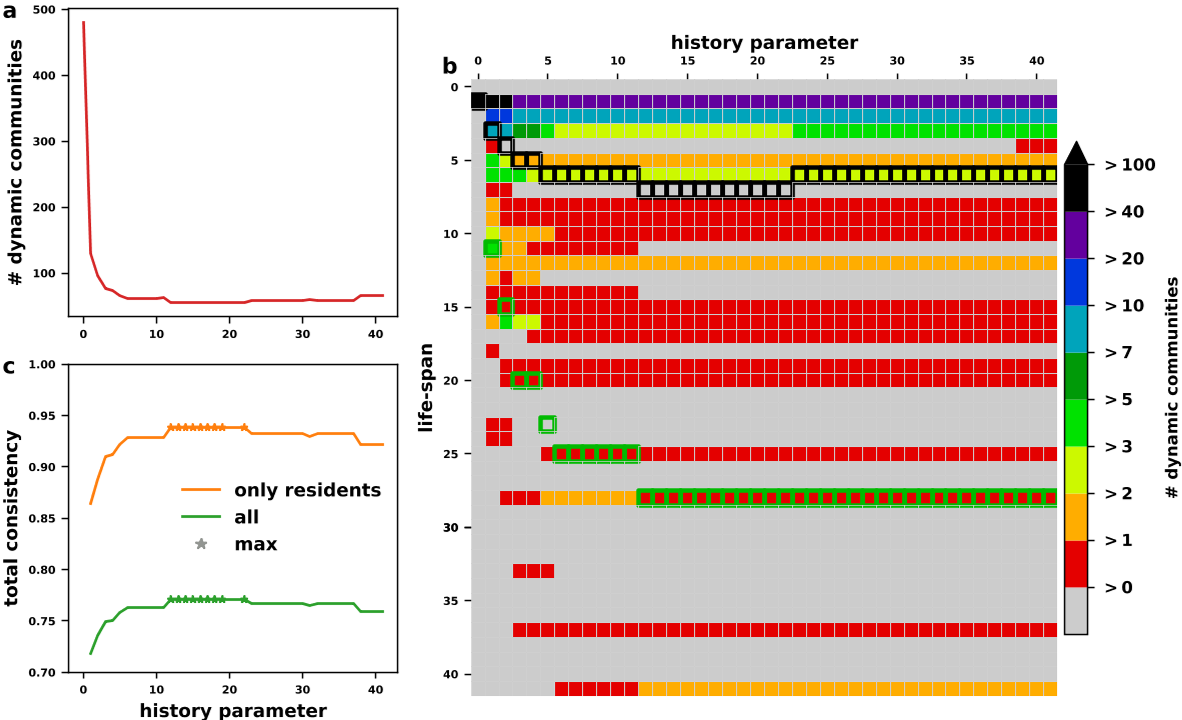
GPT学习笔记-聚类(clustering)
1. 什么是clustering
聚类是一种非常有用的无监督学习技术,它的主要目的是发现数据的内在结构和模式。在许多实际应用中,我们可能没有明确的目标变量或预测目标,但我们仍希望了解数据的组织方式,或者找出数据中的特定模式或组。这…
![[机器学习]K-means——聚类算法](https://img-blog.csdnimg.cn/direct/cfe264aecec147118f4418f5794bff14.png)
[机器学习]K-means——聚类算法
一.K-means算法概念 二.代码实现
# 0. 引入依赖
import numpy as np
import matplotlib.pyplot as plt # 画图依赖
from sklearn.datasets import make_blobs # 从sklearn中直接生成聚类数据# 1. 数据加载
# 生成(n_samples:样本点,centers&…
【聚类】K-modes和K-prototypes——适合离散数据的聚类方法
应用场景:
假设一批数据,每一个样本中,有唯一标识(id)、品类(cate_id)、受众(users, 小孩、老人、中年等)等属性,希望从其中找出一些样本,使得这…

MIT 6.S965 韩松课程 05
Lecture 05: Quantization (Part 1) 文章目录Lecture 05: Quantization (Part 1)动机数字的数据类型整数定点数浮点数量化基于 K-Means 的量化 [[Han et al., ICLR 2016]](https://arxiv.org/pdf/1510.00149v5.pdf)线性量化 [[Jacob et al. CVPR 2018]](https://arxiv.org/pdf/…

【Matlab】基于改进的 Hausdorf 距离的DBSCAN船舶航迹聚类
【Matlab】基于改进的 Hausdorff 距离的DBSCAN船舶航迹聚类 一、模型简介1.1问题背景1.2具体内容AIS数据的预处理船舶轨迹分割船舶轨迹相似度度量船舶轨迹表达方式船舶轨迹相似度量方法改进的 Hausdorff 距离船舶轨迹聚类及轨迹提取基于改进DBSCAN算法轨迹聚类船舶典型轨迹的提…
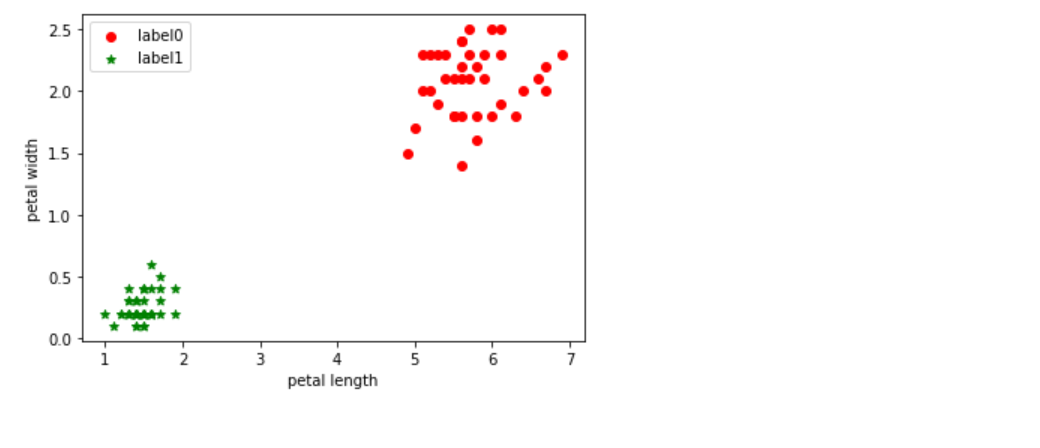
【K-means聚类算法】实现鸢尾花聚类
文章目录 前言一、数据集介绍二、使用步骤1.导包1.2加载数据集1.3绘制二维数据分布图1.4实例化K-means类,并且定义训练函数1.5训练1.6可视化展示2.聚类算法2.1.可视化生成3其他聚类算法进行鸢尾花分类 前言
例如:随着人工智能的不断发展,机器…

ggplot2 | line plot 分组及均值线:聚类后的表达变化趋势图
1. 效果图 2. 预处理及绘图
# 输入数据
> head(dat)Species cid variable value
1 setosa 1 Sepal.Length 5.1
2 setosa 2 Sepal.Length 4.9
3 setosa 3 Sepal.Length 4.7
4 setosa 4 Sepal.Length 4.6
5 setosa 5 Sepal.Length 5.0
6 setos…
“华为杯”研究生数学建模竞赛2019年-【华为杯】D题:基于改进 K-means 聚类和隐马尔可夫链的汽车行驶工况构建(附获奖论文和MATLAB代码实现)
目录 摘要: 一、问题重述 1.1 研究背景 1.2 问题重述 二、模型假设
(完全解决)如何输入一个图的邻接矩阵(每两个点的亲密度矩阵affinity),然后使用sklearn进行谱聚类
文章目录 背景输入点直接输入邻接矩阵 背景
网上倒是有一些关于使用sklearn进行谱聚类的教程,但是这些教程的输入都是一些点的集合,然后根据谱聚类的原理,其会每两个点计算一次亲密度(可以认为两个点距离越大,亲密度越…

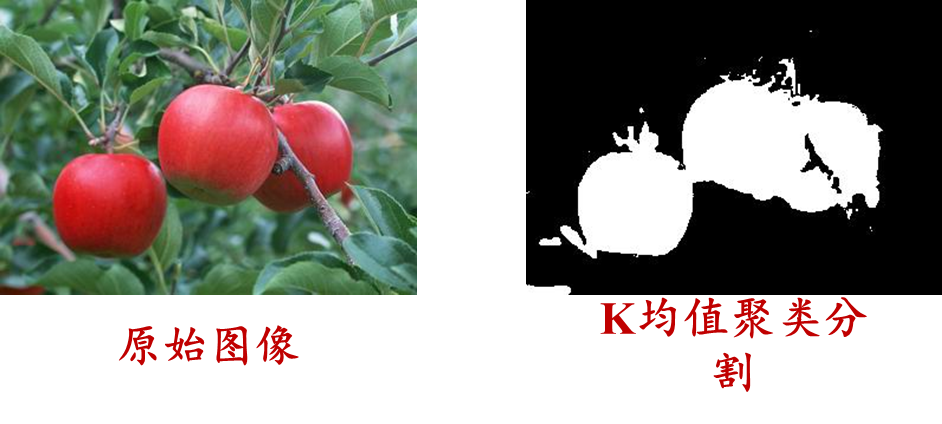
使用 K 均值聚类进行颜色分割
介绍 颜色分割是计算机视觉中使用的一种技术,用于根据颜色识别和区分图像中的不同对象或区域。聚类算法可以自动将相似的颜色分组在一起,而不需要为每种颜色指定阈值。当处理具有大范围颜色的图像时,或者当事先不知道确切的阈值时,这非常有用。
在本教程中,我们将探讨如何…
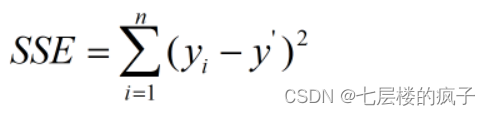
十五、机器学习进阶知识:K-Means聚类算法
文章目录 1、聚类概述2、K-Means聚类算法原理3、K-Means聚类实现3.1 基于SKlearn实现K-Means聚类3.2 自编写方式实现K-Means聚类 4、算法不足与解决思路4.1 存在的问题4.2 常见K值确定方法4.3 算法评估优化思路 1、聚类概述
聚类(Clustering)是指将不同…
PCL 点云组件聚类
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 该算法与欧式聚类、DBSCAN聚类很是类似,聚类过程如下所述: 1. 首先,我们需要提供一个种子点集合,对种子点集合进行初始的聚类操作,聚类的评估器(即聚类条件),可以指定为法向评估,也可以是距离评估,以此我…
基于Word2vec词聚类的关键词实现
一.基于Word2vec词聚类的关键词步骤
基于Word2Vec的词聚类关键词提取包括以下步骤:
1.准备文本数据:收集或准备文本数据,可以是单一文档或文档集合,涵盖关键词提取的领域。2.文本预处理:清洗文本数据,去除…

python机器学习——聚类评估方法 K-Means聚类 神经网络模型基础
目录 聚类模型的评价方法(1)轮廓系数:(2)评价分类模型 【聚类】K-Means聚类模型(1)聚类步骤:(2)sklearn参数解析(3)k-means算法特点 神…

python 机器学习——Kmeans之K值的选取原理
Kmeans之K值的选取参考一般而言,没有所谓最好的选择聚类数的方法,通常情况下是需要根据不同的问题,人工进行选择的。选择的时候思考我们运用 K-means 算法聚类的动机是什么,然后选择能最好服务于该目的标聚类数。当人们在讨论选择…

机器学习—python 实现网格聚类算法,子空间聚类 CLIQUE算法(pyclustering)
文章目录机器学习—python 实现网格聚类算法,子空间聚类 CLIQUE算法(pyclustering)一、基于网格聚类原理二、算法实现(一) CLIQUE 算法1. 前言2. 算法过程3. 示例代码参考资料机器学习—python 实现网格聚类算法,子空间聚类 CLIQU…
【GeoDa实用技巧100例】024:geoda计算全局(局部)莫兰指数Moran‘s I,LISA聚类地图,显著性地图
严重声明:本文及专栏《GeoDa空间计量案例教程100例》为CSDN博客专家刘一哥GIS原创,原文及专栏地址为:https://blog.csdn.net/lucky51222/category_12373659.html,谢绝转载或爬取!!! 文章目录 一、计算全局(或局部)单变量莫兰指数I1. 加载实验数据2. 加载权重矩阵3. 创建…

人工智能系列 之机器学习DBSCAN聚类算法
1 介绍 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个出现得比较早(1996年),比较有代表性的基于密度的聚类算法。DBSCAN能够将足够高密度的区域划分成簇,并能在具有噪声的空…
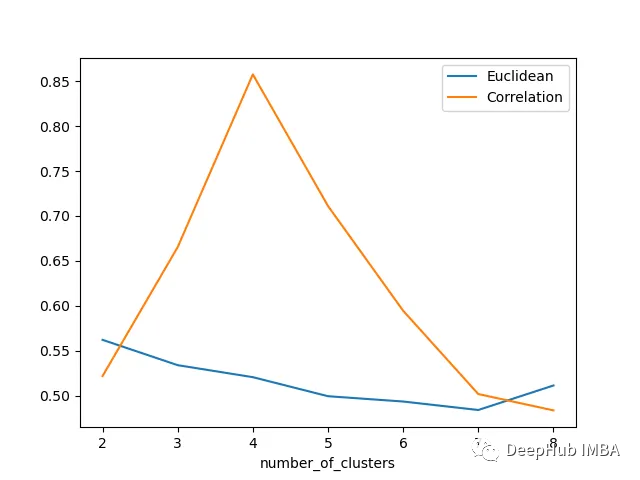
使用轮廓分数提升时间序列聚类的表现
我们将使用轮廓分数和一些距离指标来执行时间序列聚类实验,并且进行可视化
让我们看看下面的时间序列: 如果沿着y轴移动序列添加随机噪声,并随机化这些序列,那么它们几乎无法分辨,如下图所示-现在很难将时间序列列分组为簇: 上面…
利用R语言进行聚类分析实战(数据+代码+可视化+详细分析)
🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972 个人介绍: 研一|统计学|干货分享 擅长Python、Matlab、R等主流编程软件 累计十余项国家级比赛奖项,参与研究经费10w、40w级横向 文…
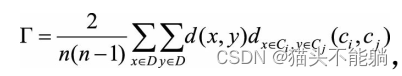
【机器学习5】无监督学习聚类
相比于监督学习, 非监督学习的输入数据没有标签信息, 需要通过算法模型来挖掘数据内在的结构和模式。 非监督学习主要包含两大类学习方法: 数据聚类和特征变量关联。
1 K均值聚类及优化及改进模型
1.1 K-means
聚类是在事先并不知道任何样…

菜菜的深度学习笔记 | 基于Python的理论与实现(六)—>简单两层网络的实现
系列索引:菜菜的深度学习笔记 | 基于Python的理论与实现 文章目录一、学习算法的实现(1)神经网络的学习步骤(2)神经网络的类(3)mini-batch的实现(4)基于测试数据的评价一…

模糊C均值聚类(Fuzzy C-means)算法(FCM)
本文的代码与数据地址已上传至github:https://github.com/helloWorldchn/MachineLearning
一、FCM算法简介
1、模糊集理论
L.A.Zadeh在1965年最早提出模糊集理论,在该理论中,针对传统的硬聚类算法其隶属度值非0即1的严格隶属关系ÿ…

【PCL】(二十六)自定义条件的欧几里得聚类分割点云
(二十六)自定义条件的欧几里得聚类分割点云
以下代码实现自定义条件对点进行欧几里得聚类分割。
conditional_euclidean_clustering.cpp
#include <pcl/point_types.h>
#include <pcl/io/pcd_io.h>
#include <pcl/console/time.h>#…
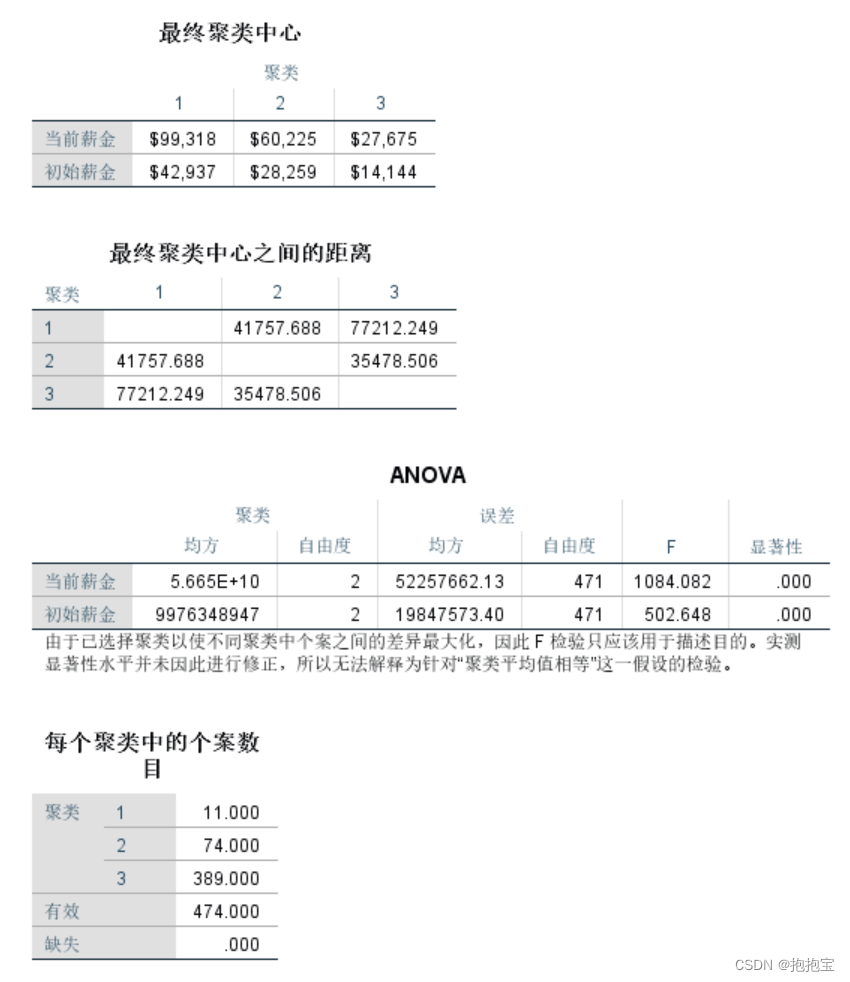
SPSS k-均值聚类的 anova分析表解读
from:SPSS K均值聚类(k-means)和可视化方法 - CollinsLi - 博客园 (cnblogs.com)
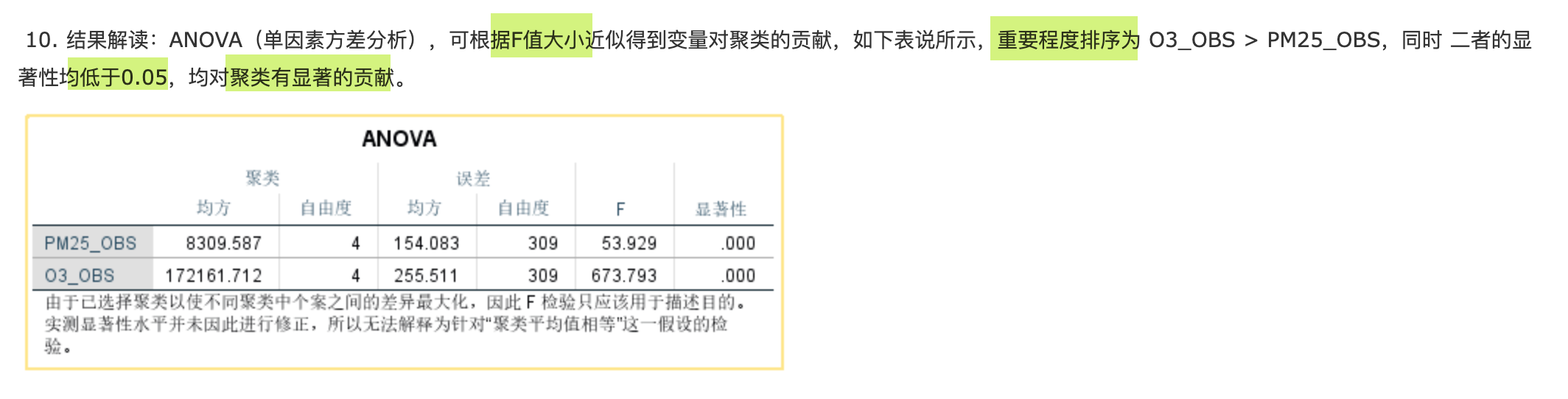
F值:变量对聚类的贡献
显著性水平:<0.05 则因子显著
创新应用2:nnmf+DBO+K-Medoids聚类,蜣螂优化算法DBO优化K-Medoids,适合学习和发paper。
创新应用2:nnmfDBOK-Medoids聚类,蜣螂优化算法DBO优化K-Medoids,适合学习和发paper。
一、蜣螂优化算法
摘要:受蜣螂滚球、跳舞、觅食、偷窃和繁殖等行为的启发,提出了一种新的基于种群的优化算法(Dung Beetle Optim…

【PCL】(二十八)点云超体素分割
(二十九)点云超体素分割
论文:Voxel Cloud Connectivity Segmentation - Supervoxels for Point Clouds
supervoxel_clustering.cpp
#include <pcl/console/parse.h>
#include <pcl/point_cloud.h>
#include <pcl/point_ty…

k均值聚类算法python_K均值和其他聚类算法:Python快速入门
k均值聚类算法pythonThis post was originally published here 这篇文章最初发表在这里 Clustering is the grouping of objects together so that objects belonging in the same group (cluster) are more similar to each other than those in other groups (clusters). In…
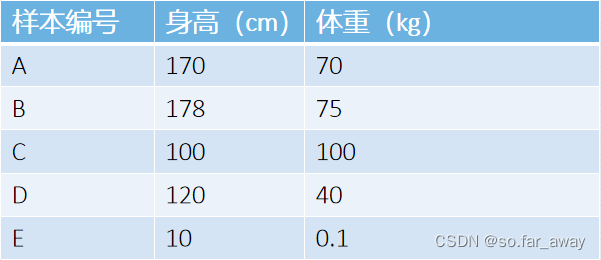
机器学习-10 聚类算法
聚类算法 算法概括聚类(clustering)聚类的概念聚类的要求聚类与分类的区别 常见算法分类聚类算法中存在的问题 距离度量闵可夫斯基距离欧式距离(欧几里得距离)曼哈顿距离切比雪夫距离皮尔逊相关系数余弦相似度杰卡德相似系数 划分…

六、回归与聚类算法 - K-means算法
目录
1、K-means 聚类步骤
2、API
3、案例
4、性能评估指标
5、总结 线性回归欠拟合与过拟合线性回归的改进 - 岭回归分类算法:逻辑回归模型保存与加载无监督学习:K-means算法 1、K-means 聚类步骤 2、API 3、案例 4、性能评估指标 5、总结
机器学习:基于Kmeans聚类算法对银行客户进行分类
机器学习:基于Kmeans聚类算法对银行客户进行分类 作者:i阿极 作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页 😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞&#x…

六、回归与聚类算法 - 线性回归
目录
1、线性回归的原理
1.1 应用场景
1.2 什么是线性回归
1.2.1 定义
1.2.2 线性回归的特征与目标的关系分析
2、线性回归的损失和优化原理
2.1 损失函数
2.2 优化算法
2.2.1 正规方程
2.2.2 梯度下降
3、线性回归API
4、回归性能评估
5、波士顿房价预测
5.1 流…
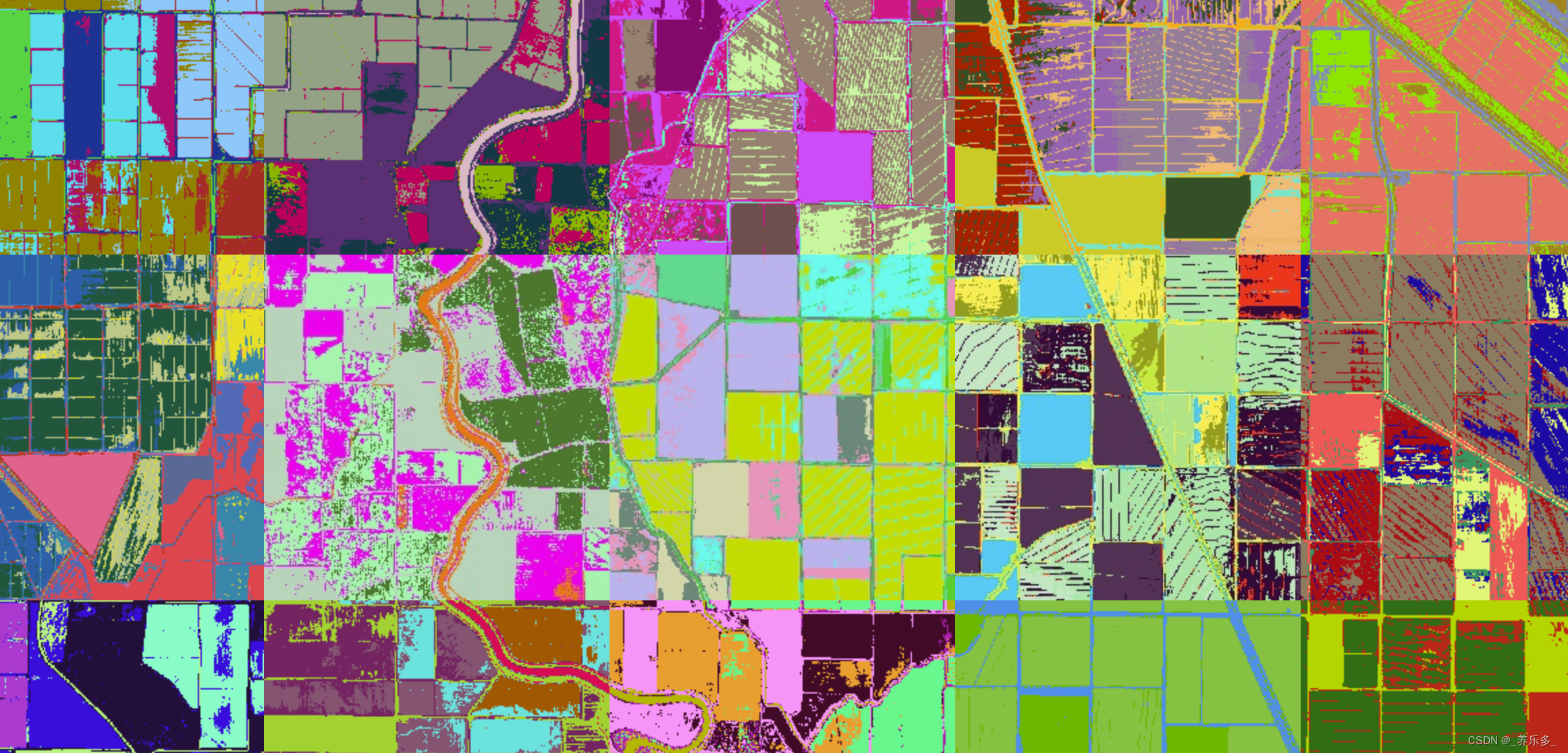
GEE:Gmeans图像分割
G-means是一种聚类算法,它是基于K-means算法的改进版本。K-means算法的一个主要缺点是需要事先指定聚类的数量,而G-means算法则可以自动确定聚类的数量。
G-means算法使用了类似于K-means的迭代过程,但在每次迭代时,它会检查每个聚类是否可以继续细分为两个子聚类。这个检…
机器学习-无监督学习之聚类
文章目录 K均值聚类密度聚类(DBSCAN)层次聚类AGNES 算法DIANA算法 高斯混合模型聚类聚类效果的衡量指标小结 K均值聚类
步骤: Step1:随机选取样本作为初始均值向量。 Step2:计算样本点到各均值向量的距离,…
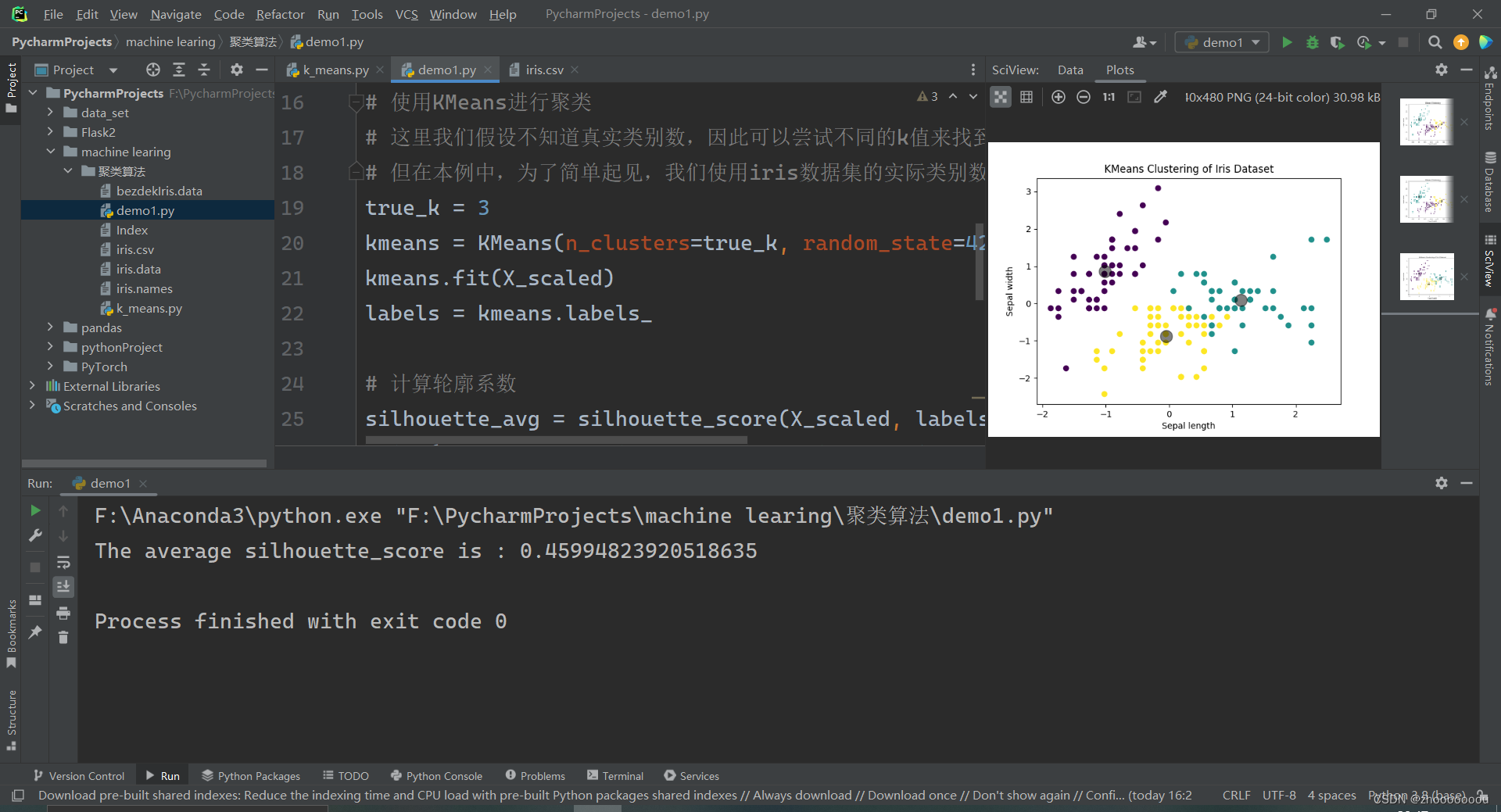
机器学习 - 聚类 - k_means
一、下载数据集
https://archive.ics.uci.edu/ml/datasets/ 这个库提供了大量的机器学习数据集 Iris数据集:这是一个经典的小型数据集,包含了150个样本,分为三类,每类50个样本。每个样本有四个特征,分别是花萼长度、花…
机器学习-聚类算法详解
K-maens & DBSCAN 与分类、回归任务不同,聚类任务事先并不知道任何样本标签,通过数据之间的内在关系把样本划分为若干类别,使得同类别之间的相似度高,不同类别之间的样本相似度低。 K-means 基本思想 K-means算法的基本思想是…

【机器学习基础】DBSCAN
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!相对完整的机器学习基础教学! ⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战…
葫芦书笔记----非监督学习
非监督学习
K均值聚类
聚类是在事先并不知道任何样本类别标签的情况下,通过数据之间的内在 关系把样本划分为若干类别,使得同类别样本之间的相似度高,不同类别之间的样本相似度低。
简述K均值算法的具体步骤
速记:预处理. 1.随…
主题建模-corpora语料库-PCA进行降维
https://colab.research.google.com/drive/1F-1Ej7T2xnUKXSmDPjjOChNbBTvQlpnM?uspsharing 考试
https://colab.research.google.com/drive/1hSRxzFL9cx7PYrHYZeEnT3jRSn8LmQcx?uspsharing 第一题要求
聚类选定的新闻数据。此时,请考虑以下事项。(2分…
基于聚类的点云背景分离算法python代码
点云背景分离是一个常用的计算机视觉任务,它旨在从点云数据中分离出感兴趣的物体。聚类是一种常用的方法,可以通过将相似的点聚集在一起来完成背景分离。下面是一个简单的基于K-Means聚类的点云背景分离的Python代码示例,使用的是scikit-lear…

Python | 实现 K-means 聚类——多维数据聚类散点图绘制
文章目录 吐槽正题本文背景文章目的K-means 聚类步骤:K-means分类Python代码上述代码结果可视化展示不入流的小期待 吐槽
客观吐槽:CSDN的富文本编辑器真是超级无敌难用。首先要吐槽一下CSDN的富文本编辑器,好难用,好难用&#x…

kmeans++聚类生成anchors
kmeans聚类生成anchors
说明
使用yolo系列通常需要通过kmeans聚类算法生成anchors,
但kmeans算法本身具有一定的局限性,聚类结果容易受初始值选取影响。
因此通过改进原kmeans_for_anchors.py实现 kmeans聚类生成anchors。具体实现如下:
i…
吴恩达机器学习笔记 三十 什么是聚类 K-means
聚类(clustering)是一种无监督学习算法,关注多个数据点并自动找到相似的数据点,在数据中找到一种特定的结构。无监督学习算法的数据集中没有标签 y ,所以不能说哪个是“正确的 y ”。 K-means算法
K-means算法就是在重复做两件事:…

深度学习与文本聚类:一篇全面的介绍与实践指南
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博…

机器学习系列——(二十)密度聚类
引言
在机器学习的无监督学习领域,聚类算法是一种关键的技术,用于发现数据集中的内在结构和模式。与传统的基于距离的聚类方法(如K-Means)不同,密度聚类关注于数据分布的密度,旨在识别被低密度区域分隔的高…
Phenograph聚类方法
Phenograph是一种用于深度分析的算法,主要评估单细胞RNA测序数据的深度。该算法的特点是能够在需要预先设定深度的情况下,自动地识别和分离出潜在的可能的细胞亚群。
Phenograph 的工作原理基于图论和社区发现的原理。具体步骤如下: 相似性计…
【Python机器学习】零基础掌握DBSCAN聚类
是否能通过一种只能的分析工具解决城市交通拥堵的问题?
想象一下,你正开车行驶在城市的街道上,但由于交通拥堵,几乎每走一步都要停下来,怎么有那么多车?有没有什么办法通过一些简单的操作来疏导交通?你可能会想:“这些交通瓶颈到底是怎么形成的?有没有办法解决它们?…
超图聚类论文阅读2:Last-step算法
超图聚类论文阅读2:Last-step算法 《使用超图模块化的社区检测算法》 《Community Detection Algorithm Using Hypergraph Modularity》 COMPLEX NETWORKS 2021, SCI 3区 具体实现源码见HyperNetX库 工作:提出了一种用于超图的社区检测算法。该算法的主要…

基于K-Means的图片聚类算法实战
一. 场景说明
我们通常遇到一个问题,当很多图片放在一个文件夹中,要把这些文件夹中的图片按规律分为几类。当图片比较少时,我们可以手动完成,但是当图片的数量是几千甚至几万时,手动挑选图片的工作量就太大了。 因此&…

什么是软阈值,硬阈值,软聚类,硬聚类!!软和硬指的是什么呢?详细解释看这里!!!
文章目录 一、软阈值和硬阈值的基本概念和区别二、软聚类和硬聚类的详细概念和区别 一、软阈值和硬阈值的基本概念和区别
在我所研究的领域中,经常出现小波降噪,就拿小波降噪举例子吧!!
在信号处理中,小波降噪是一种…
【无监督学习之聚类】
聚类 0.简介距离 和 相似度1. K均值聚类(kmeans)模型算法特点 2. 谱聚类(Spectral clustering)算法思想特点谱聚类的具体步骤:算法步骤: 3.小结参考资料 0.简介
聚类:针对给定的样本,依据他们的属性的相似度或距离,将…
入门机器学习(西瓜书+南瓜书)聚类总结(python代码实现)
入门机器学习(西瓜书南瓜书)聚类总结(python代码实现)
一、聚类
1.1 通俗理解
聚类,顾名思义就是把数据特征相似的数据聚为一类。属于无监督学习的范畴。没有标签值的监督,因此不同的聚类算法࿰…
(数字图像处理MATLAB+Python)第十章图像分割-第三,四节:区域分割和基于聚类的图像分割
文章目录 一:区域分割(1)区域生长A:原理B:示例C:程序 (2)区域合并A:原理B:示例C:程序 (3)区域分裂A:原理B&…
<聚类算法(Clustering)>——《机器学习算法初识》
目录 一、聚类算法简介
1 认识聚类算法
1.1 聚类算法在现实中的应用
1.2 聚类算法的概念
1.3 聚类算法与分类算法最大的区别
2 小结
二、聚类算法api初步使用
1 api介绍
2 案例
2.1流程分析
2.2 代码实现
3 小结
三、聚类算法实现流程
1 k-means聚类步骤
2 小结…

【一起啃书】《机器学习》第九章 聚类
文章目录 第九章 聚类9.1 聚类任务9.2 性能度量9.2.1 外部指标9.2.2 内部指标 9.3 距离计算9.3.1 欧氏距离9.3.2 曼哈顿距离9.3.3 切比雪夫距离9.3.4 闵可夫斯基距离9.3.5 标准化的欧几里得距离9.3.6 马氏距离9.3.7 兰氏距离9.3.8 余弦距离9.3.9 汉明距离9.3.10 编辑距离 9.4 原…
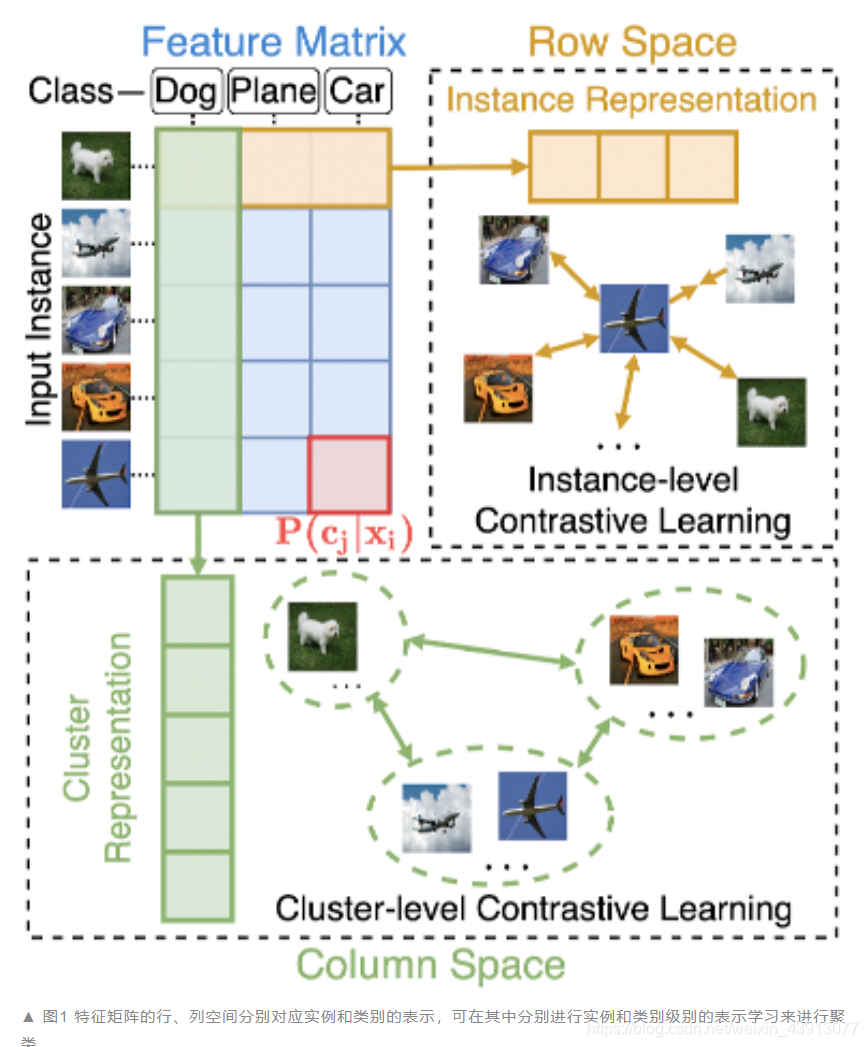
Contrastive Clustering
文章目录121
论文链接:AAAI 2021 博客链接:基于对比学习的聚类工作 现有的大部分深度聚类(Deep Clustering)需要迭代进行表示学习和聚类这两个过程。
算法过程:
对样本进行表示对样本进行聚类重复1和2
缺点&#x…


DBSCAN算法详解
Density-based Clustering
第二种类型的聚类算法叫做“密度聚类”,即基于密度的聚类。这一类模型是根据样本之间的紧密程度进行聚类,通过样本的密度来考虑样本之间的可连接性。其中,DBSCAN是最为著名的密度聚类模型。DBSCAN基于一组“邻域”…
改进的 K-Means 聚类方法介绍
引言
数据科学的一个中心假设是,紧密度表明相关性。彼此“接近”的数据点是相似的。如果将年龄、头发数量和体重绘制在空间中,很可能许多人会聚集在一起。这就是 k 均值聚类背后的直觉。
我们随机生成 K 个质心,每个簇一个,并将…

机器学习 | 解析聚类算法在数据检测中的应用
目录
初识聚类算法
聚类算法实现流程
模型评估
算法优化
特征降维
探究用户对物品类别的喜好细分(实操) 初识聚类算法
聚类算法是一种无监督学习方法,用于将数据集中的对象按照相似性分组。它旨在发现数据中的内在结构和模式,将具有相似特征的数据…
初步认识--物联网数据分析与挖掘
数据预处理与知识发现
为什么要进行数据预处理? 因为在现实生活中存在着大量的“脏”数据
数据不完整的性数据有噪音数据数据不一致性
技术主要四种:数据清理,数据集成,数据变换,数据归约
数据清洗:
主…

python机器学习——Kmeans聚类
Kmeans聚类聚类基本思想Kmeans 介绍python 实现参考聚类基本思想
背景: 由于获取带有标签的数据成本比较高(因为需要人工标记),而没有标签的数据却很容易获得。如果我们可以根据样本自身的属性或者说特征,给这写样本进…
机器学习:什么是分类/回归/聚类/降维/决策
目录
学习模式分为三大类:监督,无监督,强化学习
监督学习基本问题
分类问题
回归问题
无监督学习基本问题
聚类问题
降维问题
强化学习基本问题
决策问题
如何选择合适的算法 我们将涵盖目前「五大」最常见机器学习任务:…
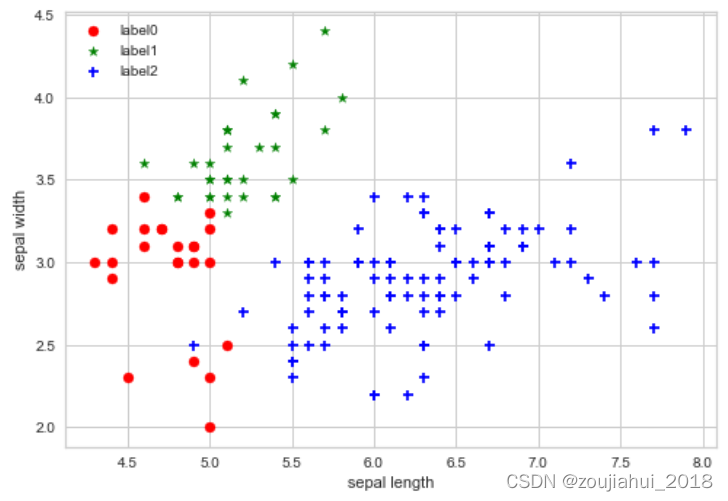
K-center聚类的python实现
文章目录介绍函数介绍实例作者:张双双介绍
K-center聚类和K-means聚类类似,都是通过迭代类中心点直至收敛,不同的是K-center的中心点必须是一个真实的样本点,而K-means并不需要。
函数介绍
class Kmedoid:def __init__(self, d…
C# | DBSCAN聚类算法实现 —— 对直角坐标系中临近点的点进行聚类
C# | DBSCAN聚类算法实现 聚类算法是一种常见的数据分析技术,用于将相似的数据对象归类到同一组或簇中。其中,DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,能够有效…
python实现K均值聚类算法
之前做大作业的时候本来想用聚类法给点集分类的,但是太复杂了,于是最后没有采用这个方案。现在把之前做的一些工作整理出来写个小博客。
K-means聚类法原理:
聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚…
聚类(Clustering)理论
一、无监督学习介绍 在这小节中,我将开始介绍聚类算法,这是我们学习的第一个非监督学习算法,我们将要让计算机学习无标签数据而不是此前的标签数据。那么什么是非监督学习呢?在学习机器学习知识的开始我曾简单地介绍过非监督学习&…
K-均值聚类(K-means clustering)
K-均值聚类(K-means clustering)是一种常用的无监督学习算法,用于将样本数据划分成K个不同的类别。K-均值聚类试图找到K个簇,使得簇内的样本点相似度最高,而簇间的样本点相似度最低。
算法步骤如下:
随机…

机器学习 - 聚类,聚类类别,聚类相似度,聚类性能度量
文章目录聚类一、概念二、聚类的类别1. 基于划分的聚类2. 基于层次的聚类3. 基于密度的聚类4. 基于网格的聚类5. 基于模型的聚类6. 基于模糊的聚类三、聚类的相似度度量1. 闵氏距离:2. 马氏距离:参考资料聚类 一、概念 无监督学习: 无监督学习…
机器学习-聚类算法Kmeans【手撕】
聚类算法
在训练时,使用没有标签的数据集进行训练,希望在没有标签的数据里面可以发现潜在的一些结构。 其中使用范围较广的是,聚类算法。聚类算法的目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于我们的…

聚类分析 | MATLAB实现基于LP拉普拉斯映射的聚类可视化
聚类分析 | MATLAB实现基于LP拉普拉斯映射的聚类可视化 目录 聚类分析 | MATLAB实现基于LP拉普拉斯映射的聚类可视化效果一览基本介绍程序设计参考资料 效果一览 基本介绍 聚类分析 | MATLAB实现基于LP拉普拉斯映射的聚类可视化,聚类结果可视化,MATLAB程…
Python机器学习零基础理解AgglomerativeClustering层次聚类
如何解决城市规划问题?
城市规划者们面临一个复杂问题:如何合理地规划土地,使商业、居民、公园和其他设施互相便利,同时又不互相干扰?解决这个问题不仅需要对土地进行精准的分类,还要考虑到土地之间的相互关系。
借助层次聚类算法(Agglomerative Clustering),规划者…

用于UAV轨迹初始化的 K-means 聚类算法
用于UAV轨迹初始化的K-means聚类算法K-means Algorithm算法思想算法解释算法应用其他K-means 简单算法设计K-means Algorithm
K均值聚类是一种无监督学习算法,主要用于数据挖掘和统计。此迭代方法旨在通过将每个点分配给具有最接近均值的聚类,将数据划分…

决策引擎系统 实时指标计算 风险态势感知系统 风险数据名单体系 欺诈情报体系
文章目录实时指标计算风险态势感知系统基于统计分析的方法核心风控指标数据核心业务数据基于无监督学习的方法基于欺诈情报的方法预警系统风险数据名单体系(名单库)欺诈情报体系数据情报技术情报事件情报情报分析实时指标计算
首先,大致上都…
图及谱聚类商圈聚类中的应用
背景
在O2O业务场景中,有商圈的概念,商圈是业务运营的单元,有对应的商户BD负责人以及配送运力负责任。这些商圈通常是一定地理围栏构成的区域,区域内包括商户和用户,商圈和商圈之间就通常以道路、河流等围栏进行分隔。…
【PCL免配置保姆级入门教程】win10 PCL1.8.0 VS2015 x64 使用Kdtree加速的DBSCAN进行点云聚类
前不久看到了大佬基于PCL做的点云聚类 https://www.jianshu.com/p/ae5a53a51ca6 ,自己实现了一遍,发现借助大佬做好的工程还有CmakeList.txt可以快速配置好PCL,免去了繁琐易错的配置过程,比自己配置一遍rabbit.pcd的入门程序来的快…

经典机器学习算法的数学推导
线性回归 为什么叫h(x)
为什么用θ表示参数
θ是向量还是矩阵?
为什么用x表示特征
为什么X是一个来表示的向量 为什么在表格添加一列1 ?便于矩阵计算 为什么用表示误差?
K-means
基础概念:
1.要得到簇的个数,需要指定K…
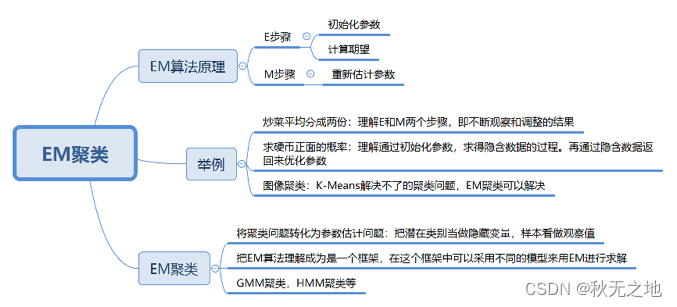
EM聚类(上):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…

自然语言处理(第17课 文本分类和聚类)
一、学习目标
1.学习文本分类的两种传统机器学习方法:朴素贝叶斯和支持向量机
2.学习文本分类的深度学习方法
3.学习文本分类的性能评估标准
4.学习文本聚类的相似性度量、具体算法、性能评估 二、文本分类 1.概述 将文本分类,主要工作是让机器分析文…

一文读懂:GBDT梯度提升
先缕一缕几个关系:
GBDT是gradient-boost decision treeGBDT的核心就是gradient boost,我们搞清楚什么是gradient boost就可以了GBDT是boost中的一种方法,boost还有XGBoost,adaboost。
基本概念
【Boost】就是让多个弱分类器&a…
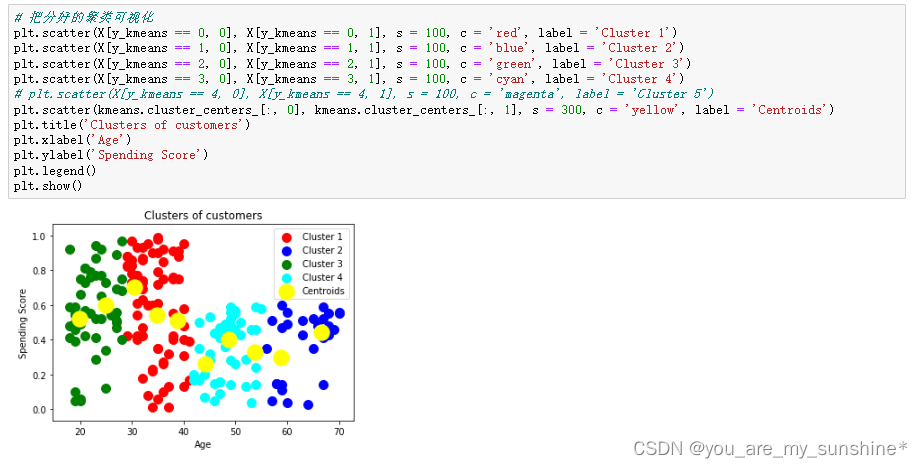
机器学习_无监督学习之聚类
文章目录 介绍机器学习下的分类K均值算法K值的选取:手肘法用聚类辅助理解营销数据贴近项目实战 介绍机器学习下的分类 以下介绍无监督学习之聚类 聚类是最常见的无监督学习算法。人有归纳和总结的能力,机器也有。聚类就是让机器把数据集中的样本按照特征的性质分组&…
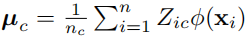

【机器学习】聚类算法(三)
六、基于图的算法 6.1 谱聚类 6.2 算法原理 RatioCut算法 NCut算法 6.3 如何选择合适的K值 6.4 谱聚类的应用场景 示例代码1:对鸢尾花数据集进行聚类,并绘制结果 # 导入所需的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datas…
python实现Kmeans
代码:
import numpy as np
import random
from math import sqrtdef dist(arr1, arr2):return sqrt(np.sum(arr1 - arr2) ** 2)def random_center(dataset, k):"""随机生成初始的聚类中心,dataset的每一行是一个样本:param dataset::par…

python笔记:使用数据结构的凝聚分层聚类
这个blog显示了使用连接图来捕获数据中的局部结构。在有局部结构的情况下凝聚分层聚类的结果
1 使用数据结构后,凝聚分层聚类的特点
使用数据结构后,会有以下的特点: 首先,没有连接矩阵的聚类比有连接矩阵的聚类要快。其次&#…
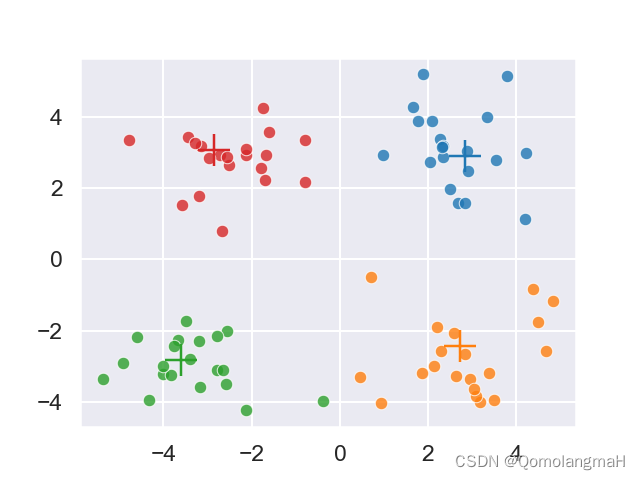
【机器学习】聚类(二):原型聚类:LVQ聚类(学习向量量化)
文章目录 一、实验介绍1. 算法流程2. 算法解释3. 算法特点4. 应用场景5. 注意事项 二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. LVQ类a. 构造函数b. 闵可夫斯基距离c. LVQ聚类过程e. 聚类结果可视化 2. 辅助函数3. 主函数a. 命令行界面 ÿ…
66 | RMF细分聚类案例
引言
在当今数字化时代,电子商务已成为商业领域中不可或缺的一部分,企业在网络平台上通过交易产品和服务,与全球范围内的消费者进行互动。随着电子商务的迅速发展,企业面临着巨大的竞争压力,为了有效地满足不同客户群体的需求,提高市场份额,更深入地了解客户的消费行为…
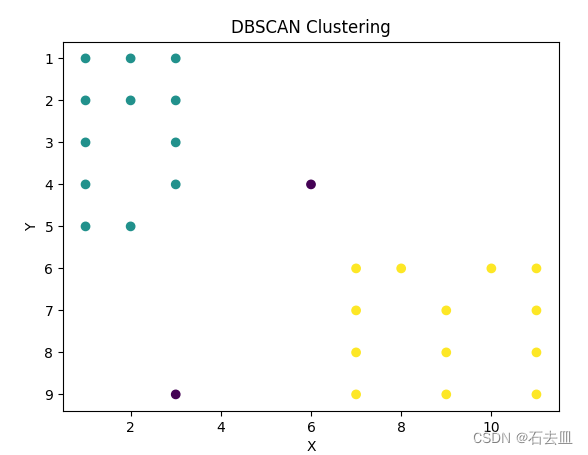
数据挖掘题目:设ε= 2倍的格网间距,MinPts = 6, 采用基于1-范数距离的DBSCAN算法对下图中的实心格网点进行聚类,并给出聚类结果(代码解答)
问题 代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import DBSCAN
#pip install matplotlib
#pip install numpy
#pip install scikit-learn
# 实心格网点的坐标
solid_points np.array([[1, 1], [2, 1],[3, 1], [1, 2], [2, 2], [3, 2],[…

机器学习(16)---聚类(KMeans)
聚类 一、聚类概述1.1 无监督学习与聚类算法1.2 sklearn中的聚类算法 二、 KMeans2.1 基本原理2.2 簇内误差平方和 三、sklearn中的KMeans3.1 所用模块3.2 聚类算法的模型评估指标3.3 轮廓系数3.4 CHI(卡林斯基-哈拉巴斯指数) 四、KMeans做矢量量化4.1 概述4.2 案例 一、聚类概…
20230527 K-均值聚类算法,由INSCODE AI创作助手进行生成
目录 1. K-均值聚类算法的原理2. K-均值聚类算法的优点3. K-均值聚类算法的缺点举例 由INSCODE AI创作助手进行生成 K-均值聚类算法是一种非监督学习算法,主要用于将数据集分为不同的类别。下面我将对该算法及其优缺点进行详细说明。
1. K-均值聚类算法的原理
K-均…
【聚类】谱聚类解读、代码示例
【聚类】谱聚类详解、代码示例 文章目录【聚类】谱聚类详解、代码示例1. 介绍2. 方法解读2.1 先验知识2.1.1 无向权重图2.1.2 拉普拉斯矩阵2.2 构建图(第一步)2.2.1 ϵ\epsilonϵ 邻近法2.2.2 k 近邻法2.2.3 全连接法2.3 切图(第二步…

yoloV2细节改进
文章目录 1 v2 细节升级概述2 .网络结构特点3. 架构细节解读4. 基于聚类来选择先验框尺寸5. 偏移量计算方法6. 坐标映射与还原7 感受野8. 特征融合的改进其他知识点filter 是什么? 1 v2 细节升级概述 2 .网络结构特点
使用dropout,杀死部分神经元&#…
Python | 机器学习之聚类算法
🌈个人主页:Sarapines Programmer🔥 系列专栏:《人工智能奇遇记》🔖少年有梦不应止于心动,更要付诸行动。 目录结构 1. 机器学习之聚类算法概念
1.1 机器学习
1.2 聚类算法
2. 聚类算法
2.1 实验目的…

回答关于模糊C均值聚类(FCM)的一些问题!FCM停止迭代的条件是什么,FCM中的隶属度起什么作用?
文章目录 一、模糊C均值聚类(FCM)中的隶属度是起什么作用二、FCM停止迭代的条件是什么 一、模糊C均值聚类(FCM)中的隶属度是起什么作用 表示样本点对各个聚类中心的隶属程度。隶属度取值范围是0-1之间,值越大表示样本点越可能属于…
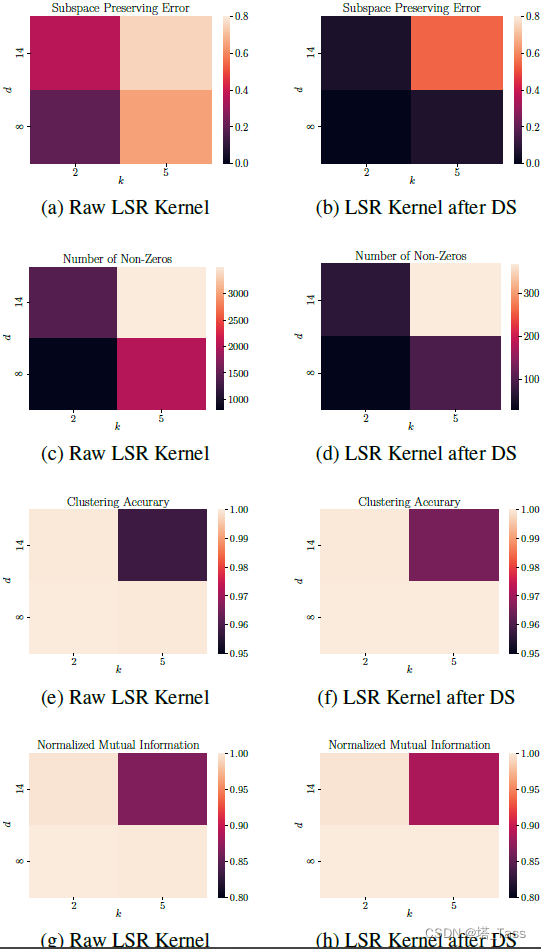
论文阅读:Understanding Doubly Stochastic Clustering
Publisher: PMLR 2022 Author: 丁天骄, 德里克林, 雷内维达尔, 本杰明海菲勒 摘要
将矩阵投影到双随机矩阵空间上的问题在机器学习中有几个应用。例如,在谱聚类中,从数据亲和矩阵形成归一化拉普拉斯矩阵与将其投影到双…
机器学习面试题库:K-means
一、简述K-means算法的原理及工作流程?
原理: K-means是一个无监督的聚类算法。它的主要目的是对同一组数据对象进行分类。其原理是基于样本间的相似性来聚类分析的,即将所有样本分为K个簇,使得同一个簇间中样本相似性最高&#…
Python机器学习零基础理解AffinityPropagation聚类
如何解决社交媒体上的好友推荐问题?
想象一下,一个社交媒体平台希望提供更加精准的好友推荐功能,让用户能更容易地找到可能成为好友的人。这个问题看似简单,但当面对数百万甚至数千万的用户时,手动进行好友推荐就变得几乎不可能。
解决这个问题的一个方案就是使用机器学…
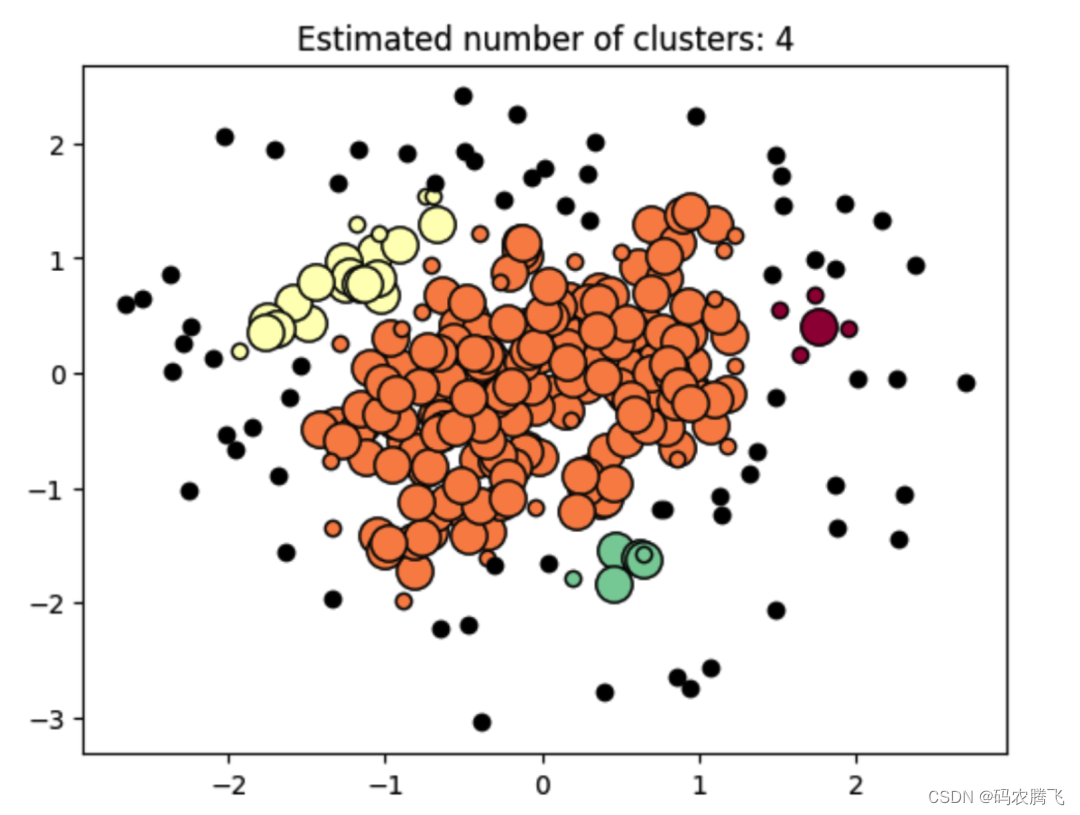
聚类分析 | Python密度聚类(DBSCAN)
密度聚类是一种无需预先指定聚类数量的聚类方法,它依赖于数据点之间的密度关系来自动识别聚类结构。 本文中,演示如何使用密度聚类算法,具体是DBSCAN(Density-Based Spatial Clustering of Applications with Noise)来…
机器学习---微博聚类案例
1、微博聚类分析 要实现广告的精准投放,需要使用聚类找出兴趣一致的用户群体,这样就需要对用户进行聚类找出行为一致的用户,当对所有用户完成聚类之后,再使用关键词分析找出每个聚类群体中的用户的讨论主题,如果主题符…
机器学习之K-means聚类算法
目录
K-means聚类算法
算法流程
优点
缺点
随机点聚类
人脸聚类
旋转物体聚类 K-means聚类算法
K-means聚类算法是一种无监督的学习方法,通过对样本数据进行分组来发现数据内在的结构。K-means的基本思想是将n个实例分成k个簇,使得同一簇内数据相…
【数据聚类|深度聚类】Graph Contrastive Clustering(GCC)论文研读
文章目录 AbstractIntroductionRelated WorkDeepClusteringContrasitve LearningGraph Contrastive ClusteringProblem FormulationGraph Contrastive(GC)Framework of GCCGraph ConstructionSimilarity FunctionRepresentation Graph ContrastiveAssignment Graph Contrastive…
今天面字节啦~05.10
每次面试都感觉面试官好温和,每次面试也是对自己的一个检验,感觉自己有所长进,但更有所提升。面试除了紧张之外,还有长长的收获跟对未来的规划。 一、 Q&A
Q1:计网三次握手A1:老话术了——客户端发送请…
python(sklearn) 聚类性能度量
文章目录python(sklearn) 聚类性能度量一、sklearn聚类评价函数:二、评价函数说明:1. 轮廓系数(Silhouette Coefficient)2. CH分数(Calinski Harabasz Score )3. 戴维森堡丁指数(DBI)——davies_bouldin_sc…

多目标进化算法的性能评价指标总结
文章目录一、多目标进化算法二、指标的常见分类方法二、常用性能评价指标回顾三、参考集的缺陷四、支配关系的缺陷一、多目标进化算法
多目标进化算法 (MOEA )是一类模拟生物进化机制而形成的全局性概率优化搜索方法 ,在 20世纪 90年代中期开始迅速发展 ,其发展可以分为两个阶…
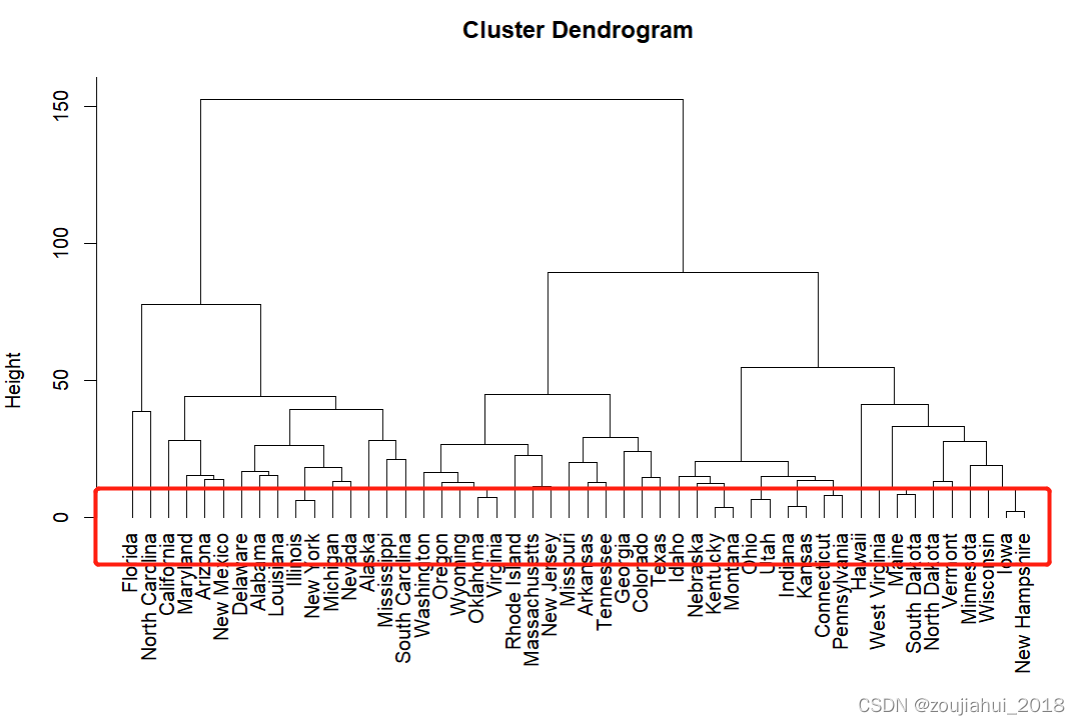
R语言中利用hclust实现层次聚类
介绍
hclust()函数是stats包中的函数,可以根据距离矩阵实现层次聚类。
hclust()使用介绍
hclust(d, method "complete", members NULL)
## S3 method for class hclust
plot(x, labels NULL, hang 0.1, check TRUE,axes T…
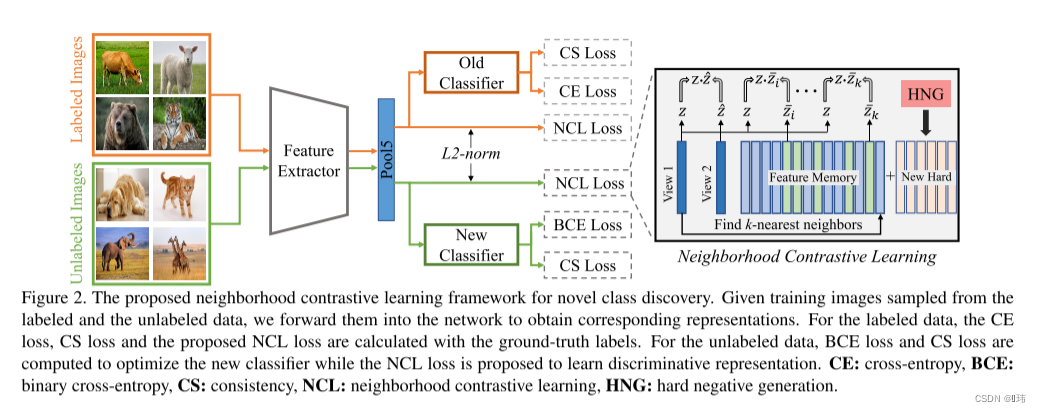
Neighborhood Contrastive Learning for Novel Class Discovery (CVPR 2021)
Neighborhood Contrastive Learning for Novel Class Discovery (CVPR 2021)
摘要
在本文中,我们解决了新类发现(NCD)的问题,即给定一个具有已知类的有标签数据集,在一组未标记的样本中揭示新的类。我们利用ncd的特性构建了一个新的框架&am…
VCG 网格顶点聚类
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 顶点聚类方法将落在给定大小体素中的所有顶点集中到单个顶点之上,其过程有点类似于点云体素下采样,之后再基于聚类之后的顶点重新连接面片,以达到网格简化的目的。 二、实现代码
//VCG
#include <vcg/comple…

基于超像素的多视觉特征图像分割算法研究
0.引言
背景: 经典聚类算法:Kmeans、FCM 现有问题: 1)现有算法大都是基于单一的视觉特征而设计的,eg:基于颜色特征的分割。 2)没有考虑像素周围的空间信息;分割结果:多噪…
一文速学数模-K-means聚类算法实战:信用卡用户画像聚类分析
目录
前言
一、用户画像概述
1.用户画像
2.为何用聚类算法作用户画像
二、数据质量校验
1.数据背景
2.数据说明
三、数据预处理
1.数据空缺值检验 2.数据归一化
四、K-means聚类
step1:选取K值
手肘法
step2:计算初始化K点
step3:迭代计算重新划分
五.画像分析 …
python实现AGNES(凝聚层次聚类)算法
#AGNES(凝聚层次聚类)算法
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from sklearn import datasets
from sklearn.metrics import confusion_matrix
irisdatasets.load_iris()
irisdatai…


聚类分析(文末送书)
目录
聚类分析是什么
一、 定义和数据类型
聚类应用
聚类分析方法的性能指标
聚类分析中常用数据结构有数据矩阵和相异度矩阵
聚类分析方法分类
二、K-means聚类算法
划分聚类方法对数据集进行聚类时包含三个要点
K-Means算法流程:
K-means聚类算法的特点
三、k-med…
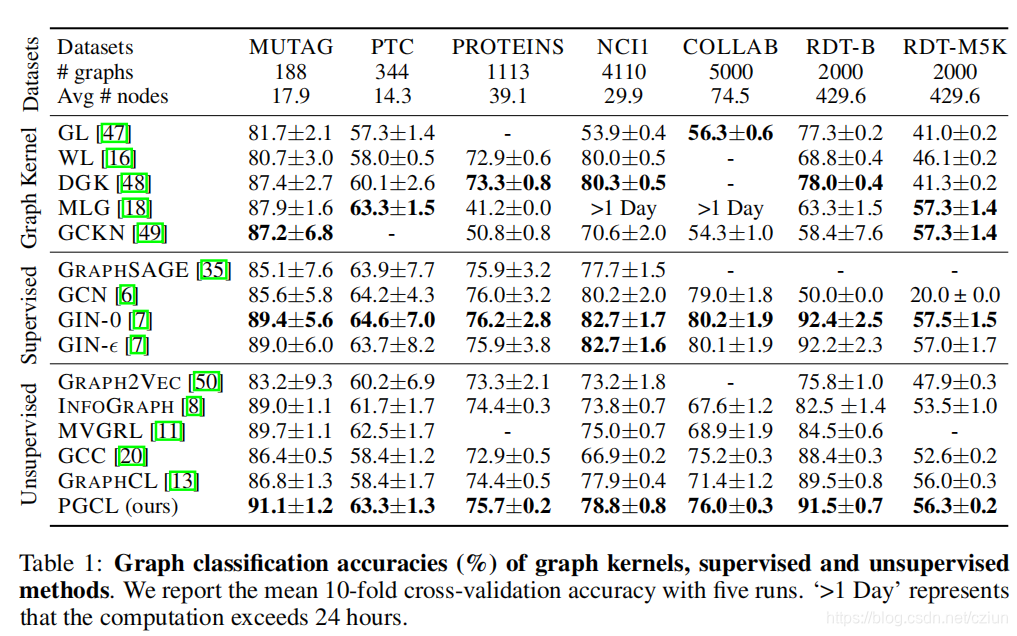
【论文阅读】PGCL:Prototypical Graph Contrastive Learning
目录摘要1 引言2 相关工作3 准备工作3.1 问题定义3.2 GNN3.3 图对比学习4 PGCL4.1 相关视图的聚类一致性4.2 重加权对比目标5 实验摘要
之前的对比方法存在一个抽样偏差问题,即负样本很可能与正样本具有相同的语义结构,从而导致性能下降。为了减轻该抽样…

专利学习——一种基于变量相关性的多元时间序列相似性搜索方法
文章目录1 摘要2 介绍——针对多元时间序列相似度量2.1 目前常见的多元时间序列特征提取方法3 步骤分析3.1 归一化3.2 采用皮尔逊相关系数,算相关性1 摘要
一种基于变量相关性的多元时间序列相似性搜索方法。
步骤一:对多元时间序列进行归一化处理 步骤…
6. DBSCAN浮光略影
6. DBSCAN浮光略影 学机器学习易陷入一个误区:以为机器学习是若干种算法(方法)的堆积,熟练了“十大算法”或“二十大算法”一切即可迎刃而解,于是将目光仅聚焦在具体算法推导和编程实现上;待到实践发现效果…
机器学习之分层聚类中的概念聚类(Conceptual Clustering)
概念
在分层聚类中,概念聚类指的是通过将数据点分组成具有相似性的概念或类别,并构建一个层次化的结构来表示这些概念之间的关系。这种方法旨在捕捉数据的内在结构,并将数据组织成一个层次化的树状结构,以便更好地理解数据的层次性和相关性。
概念聚类在分层聚类中的主要…

QT+VS实现Kmeans聚类算法
1、Kmeans的定义
聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为无监督学习。k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使…
基于Kdtree加速的DBSCAN点云聚类
目录
一、相关介绍
二、实现原理
三、实现代码
四、运行结果 一、相关介绍 在点云数据分析中,我们经常需要对点云数据进行分割,提取感兴趣的部分。聚类是点云分割中的一类方法(其他方法有模型拟合、区域增长、基于图的方法、深度学习方法等)
简介:KMeans聚类算法
在机器学习中,无监督学习一直是我们追求的方向,而其中的聚类算法更是发现隐藏数据结构与知识的有效手段。聚类是一种包括数据点分组的机器学习技术。给定一组数据点,我们可以用聚类算法将每个数据点分到特定的组中。 理论上,属于同…

MATLAB基于隐马尔可夫模型-高斯混合模型-期望最大化的MR图像分割
隐马尔可夫模型是一种统计模型,它描述了马尔可夫过程,隐马尔可夫过程中包含隐变量,语音识别和词性自动标注等一些领域常常使用隐马尔可夫模型方法来处理。马尔可夫过程是一类随机过程,马尔可夫链是它的原始模型,马尔可…
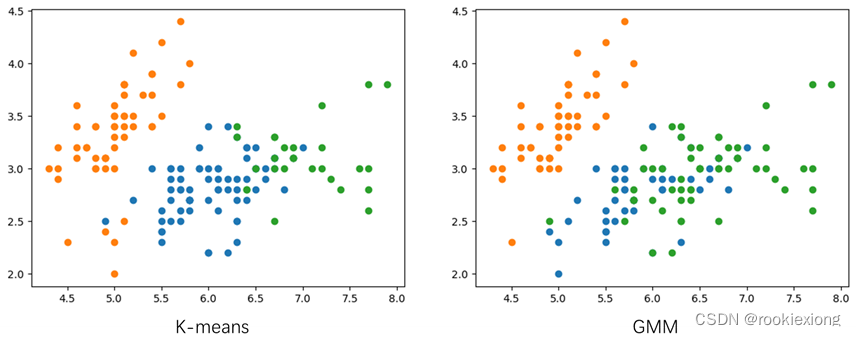
机器学习 | 无监督聚类K-means和混合高斯模型
机器学习 | 无监督聚类K-means和混合高斯模型
1. 实验目的
实现一个K-means算法和混合高斯模型,并用EM算法估计模型中的参数。
2. 实验内容
用高斯分布产生 k k k个高斯分布的数据(不同均值和方差)(其中参数自己设定ÿ…
nba球员python_分组NBA球员
nba球员pythonIn basketball, we typically talk about 5 positions: point guard, shooting guard, small forward, power forward, and center. Based on this, one might expect NBA players to fall into 5 distinct groups- Point guards perform similar to other point …
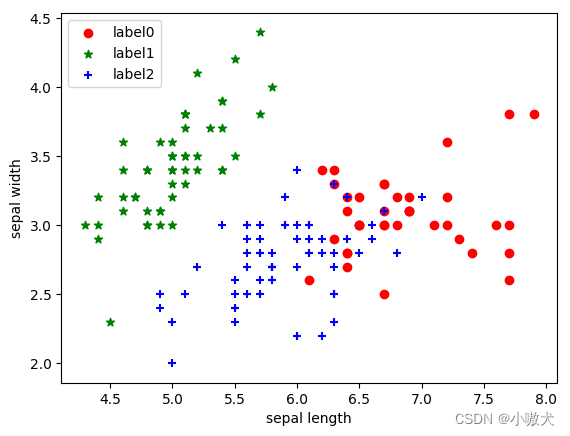
Python sklearn实现K-means鸢尾花聚类
Python sklearn实现K-means鸢尾花聚类准备1.导入相关包2.直接从sklearn.datasets中加载数据集3.绘制二维数据分布图4.实例化K-means类,并且定义训练函数5.训练6.可视化展示7.预览图准备 使用到的库: numpymatplotlibsklearn 安装: pip instal…

【数据挖掘】聚类分析
聚类分析 Cluster Analysis 肝到爆炸呜呜呜 一、什么是聚类分析
关键词
1️⃣ 簇 Cluster:数据对象的集合,相同簇中的数据彼此相似,不同簇中的数据彼此相异。
2️⃣ 聚类分析 Cluster analysis:根据数据特征找到数据中的相似性…
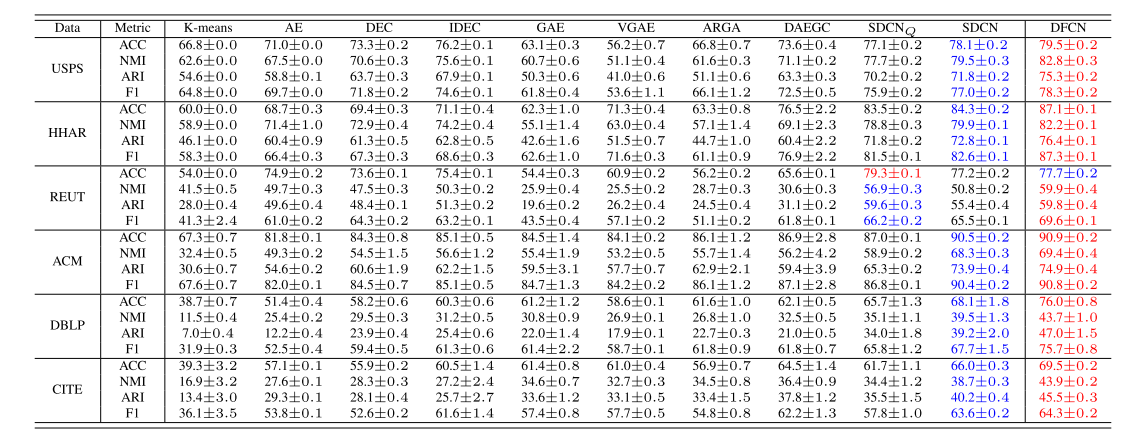
论文阅读09——《Deep Fusion Clustering Network》
论文阅读09——《Deep Fusion Clustering Network》
原文链接:论文阅读09——《Deep Fusion Clustering Network》 作者:Wenxuan Tu, Sihang Zhou, Xinwang Liu, Xifeng Guo, Zhiping Cai, En zhu, Jieren Cheng 发表时间:2021年5月18日 论文…
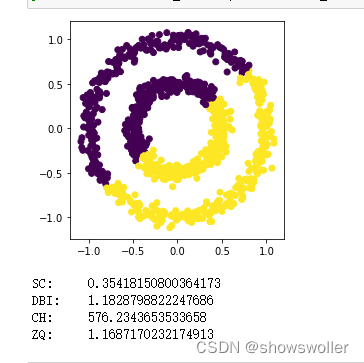
【Python机器学习】聚类算法任务,评价指标SC、DBI、ZQ等系数详解和实战演示(附源码 图文解释)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~ 一、聚类任务
设样本集S{x_1,x_2,…,x_m}包含m个未标记样本,样本x_i(x_i^(1),x_i^(2),…,x_i^(n))是一个n维特征向量。
聚类在分簇过程的任务是建立簇结构,即要将S划分为k(有的聚类算法…

数据挖掘Java——DBSCAN算法的实现
一、DBSCAN算法的前置知识
DBSCAN算法:如果一个点q的区域内包含多于MinPts个对象,则创建一个q作为核心对象的簇。然后,反复地寻找从这些核心对象直接密度可达的对象,把一些密度可达簇进行合并。当没有新的点可以被添加到任何簇时…
10种顶流聚类算法Python实现(附完整代码)
目录
前言
一、聚类
二、聚类算法
三、聚类算法示例
1、库安装
2、聚类数据集
3、亲和力传播
4、聚合聚类
5、BIRCH
6、DBSCAN
7、K均值
8、Mini-Batch K-均值
9、均值漂移聚类
10、OPTICS
11、光谱聚类
12、高斯混合模型
三、总结 前言
今天给大家分享一篇关…
2023 年你应该知道的所有机器学习算法
在过去的几年里,根据自己的工作经验,整理了我认为最重要的机器学习算法。
通过这个,我希望提供一个工具和技术的存储库,以便您可以解决各种数据科学问题!
让我们深入研究六种最重要的机器学习算法:
解释…

【机器学习】聚类算法(实战)
聚类算法(实战) 目录一、不同聚类算法的执行效果和所用时间二、准备工作(设置 jupyter notebook 中的字体大小样式等)三、Kmeans 算法1、构建样本数据2、基于样本数据构建分类器3、绘制决策边界4、演示 k-means 算法的不稳定性5、…

【机器学习】聚类算法(理论)
聚类算法(理论) 目录一、概论1、聚类算法的分类2、欧氏空间的引入二、K-Means算法1、算法思路2、算法总结三、DBSCAN算法1、相关概念2、算法思路3、算法总结四、实战部分一、概论 聚类分析,即聚类(Clustering)…
机器学习笔记之狄利克雷过程(一)基本介绍
机器学习笔记之狄利克雷过程——基本介绍引言回顾:高斯混合模型狄利克雷过程——引出引言
从本节开始,将介绍狄利克雷过程。
回顾:高斯混合模型
高斯混合模型(Gaussian Mixture Model,GMM\text{Gaussian Mixture Model,GMM}Gaussian Mixtu…
MASKGROUP: HIERARCHICAL POINT GROUPING AND MASKING FOR 3D INSTANCE SEGMENTATION
ABSTRACT
本文研究了 3D 实例分割问题,该问题在机器人技术和增强现实等现实世界中具有多种应用。由于3D物体的周围环境非常复杂,不同物体的分离非常困难。为了解决这个具有挑战性的问题,我们提出了一个新的框架来对 3D 实例进行分组和优化。在实践中,我们首先为每个点学习…
julia系列12:聚类算法包
引用“using Clustering”,使用方法如下:
1. K-means
简单例子:
using Clustering# make a random dataset with 1000 random 5-dimensional points
X rand(5, 1000)# cluster X into 20 clusters using K-means
R kmeans(X, 20; maxite…

scDML:单细胞转录组数据的批次对齐
scRNA-seq支持在单细胞分辨率呈现基因表达谱,这提高了对已知细胞类型的检测,以及异质细胞与疾病失调的理解。然而,scRNA-seq技术的广泛应用产生了许多庞大而复杂的数据集,这给集成来自不同批次和平台的数据集带来了计算挑战。
来…
信息时代的必修课:信息的矢量化(信息聚类)【矢量字体的原理】
文章目录 引言I 信息的矢量化1.1 矢量图1.2 矢量化的原理II 案例2.1 象形文字的矢量化2.2 拼音文字的矢量化2.3 形状的矢量化过程引言
利用编码原理人工设计的汇编语言:给计算机识别的指令代号基本上是很短的、等长的字母组合
信息越多,需要的编码越多,这是文明自然演变不…
【风光场景生成】基于改进ISODATA的负荷曲线聚类算法(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…

【数据聚类|深度聚类】Contrastive Clustering(CC)论文研读
文章目录 AbstractIntroductionRelated WorkContrastive LearningDeep ClusteringMethodAbstract 翻译 在本文中,我们提出了一种名为对比聚类(Contrastive Clustering, CC)的单阶段在线聚类方法,它执行的是实例级和簇级对比学习。具体来说,对于一个给定的数据集,通过数据…

机器学习---聚类算法
目录【写在前面】1、确认安装有scikit-learn库2、使用 make _ classification ()建立数据集3、使用模型进行分类头文件汇总亲和力传播聚合聚类BIRCH 聚类DBSCAN【本人的毕业设计系统中有用到】K-均值高斯混合模型【写在最后】【写在前面】
sklearn和scikit-learn: …
【KNN算法详解(用法,优缺点,适用场景)及应用】
KNN算法介绍
KNN(K Near Neighbor):k个最近的邻居,即每个样本都可以用它最接近的k个邻居来代表。KNN算法属于监督学习方式的分类算法,我的理解就是计算某给点到每个点的距离作为相似度的反馈。
简单来讲,…
简要介绍 | 图像聚类:概念、原理与方法
注1:本文系“简要介绍”系列之一,仅从概念上对图像聚类进行非常简要的介绍,不适合用于深入和详细的了解。 图像聚类:概念、原理与方法 Cluster Analysis | NVIDIA Developer 1. 背景介绍
图像聚类(Image Clustering&a…

Talk预告 | ICLR‘23 北京大学楼家宁:针对鲁棒聚类问题的接近最优核心集
本期为TechBeat人工智能社区第485期线上Talk!
北京时间3月29日(周三)20:00,北京大学信息科学技术学院——楼家宁的Talk将准时在TechBeat人工智能社区开播!
他与大家分享的主题是: “针对鲁棒聚类问题的接近最优核心集”,届时将针…
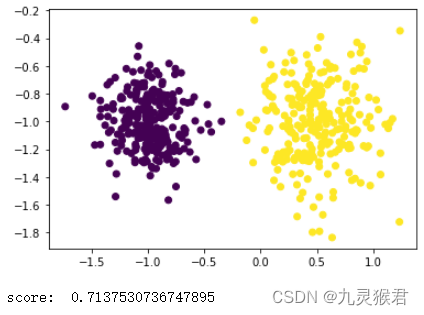
密度聚类算法(DBSCAN)实验案例
密度聚类算法(DBSCAN)实验案例
描述
DBSCAN是一种强大的基于密度的聚类算法,从直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。DBSCAN的一个巨大优势是可以对任意形状…

PCL中点云分割算法简析
文章目录 前言一、点云分割算法简介1.1 基于RANSAC的点云分割1.2 基于聚类的点云分割1.2.1 欧式聚类分割 1.3 基于深度学习的点云分割 二、算法示例2.1 基于RANSAC的平面分割2.2 欧式聚类2.3 基于PointNet的点云分割 总结 前言
点云分割算法广泛应用于激光遥感、无人驾驶、工业…
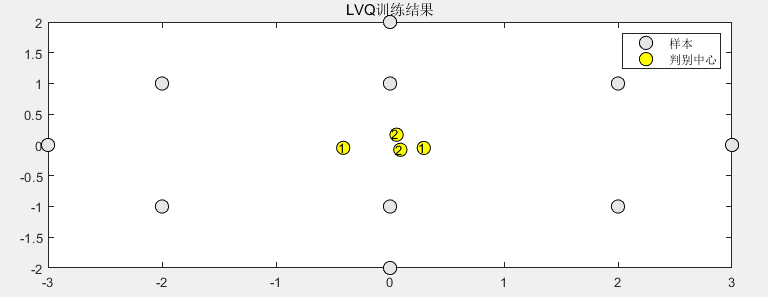
快速了解LVQ神经网络是什么
本站原创文章,转载请说明来自《老饼讲解-BP神经网络》bp.bbbdata.com 目录
一. 快速了解LVQ神经网络
1.1 LVQ神经网络是什么
1.2 LVQ神经网络的表示
二. 关于LVQ神经网络的判别计算过程
2.1 LVQ神经网络模型与它的判别方法
2.2 LVQ模型的…
聚类/clustering介绍
聚类(Clustering)是一种无监督学习技术,它通过将数据集中的对象划分为多个不同的组或簇,从而实现数据的分析和分类。聚类算法是数据挖掘和机器学习领域中最常用的技术之一,可以应用于各种不同的领域,如生物…

GEE:无监督聚类算法(wekaKMeans)
作者:CSDN @ _养乐多_
本文将介绍如何使用 Google Earth Engine(GEE)进行卫星图像 K-means 聚类分析的基本步骤,并提供相应的示例代码。
结果如下图所示, 文章目录 一、K-means 原理二、代码详解三、代码链接一、K-means 原理
二、代码详解
var roi = table;
Map.cent…
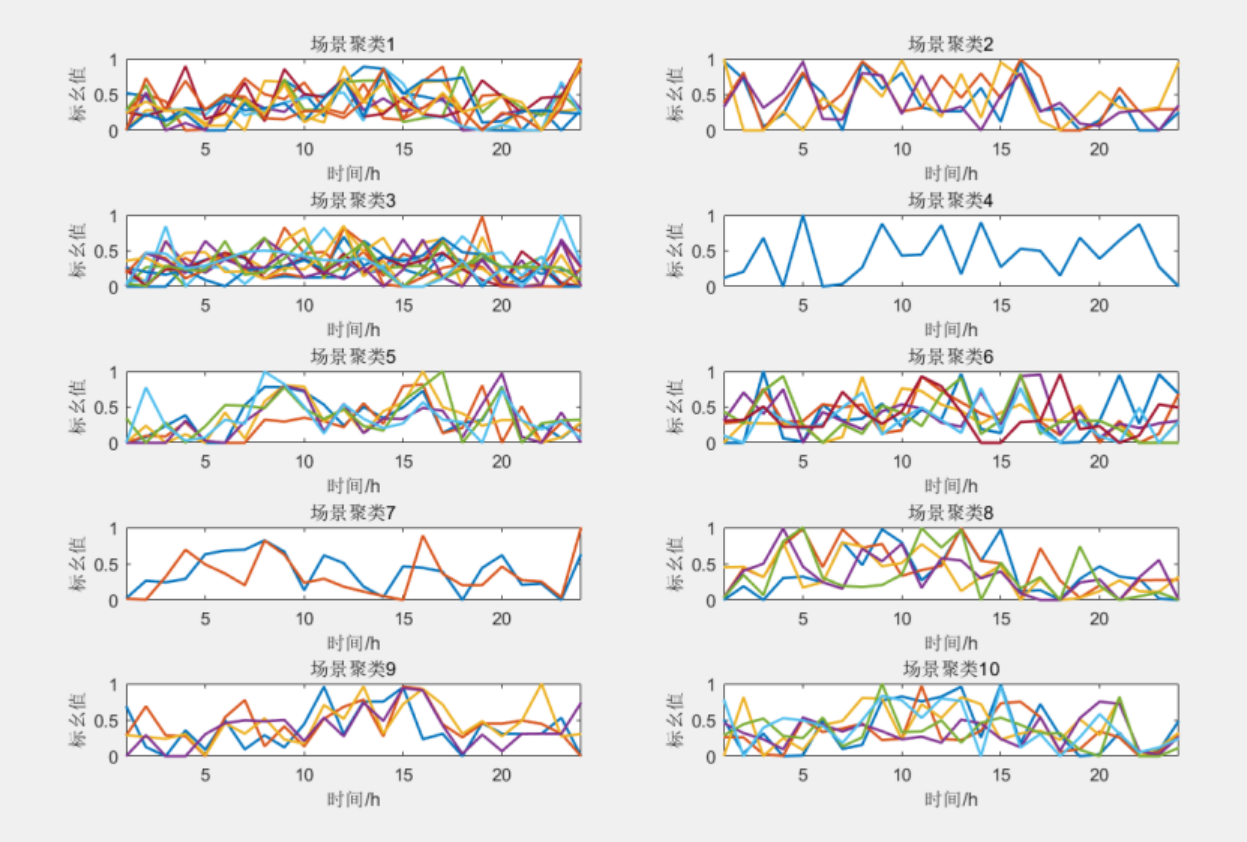
基于DBSCAN密度聚类的风电-负荷场景削减方法
目录
1 主要内容
基于密度聚类的数据预处理:
场景提取:
算法流程:
2 部分程序
3 程序结果
4 下载链接 1 主要内容
该程序复现文章《氢能支撑的风-燃气耦合低碳微网容量优化配置研究》第三章内容,实现的是基于DBSCAN…
人工智能算法|K均值聚类算法Python实现
01、算法说明 K均值聚类算法是一种简单的迭代型聚类算法,采用距离作为相似性指标,从而发现给定数据集中的K个类,且每个类有一个聚类中心,即质心,每个类的质心是根据类中所有值的均值得到。对于给定的一个包含n个d维数据点的数据集X以及要分得的类别K,选取欧式距离作为相似…

Python学习笔记——cmeans模糊聚类例程
文章目录 模糊聚类应用简介安装环境demo:运行结果 模糊聚类应用简介
模糊聚类即通过模糊数学(处理模糊或不确定性信息的数学方法)的相关算法进行聚类分析任务。 常用的模糊聚类算法包括模糊C均值聚类(FCM,Fuzzy-c mea…
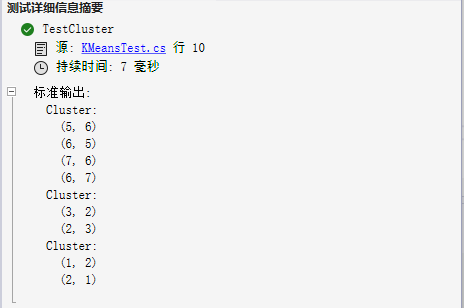
C# | KMeans聚类算法的实现,轻松将数据点分组成具有相似特征的簇
C# KMeans聚类算法的实现 文章目录 C# KMeans聚类算法的实现前言示例代码实现思路测试结果结束语 前言
本章分享一下如何使用C#实现KMeans算法。在讲解代码前先清晰两个小问题: 什么是聚类? 聚类是将数据点根据其相似性分组的过程,它有很多的应用场景&…

算法设计与智能计算 || 专题九: 基于拉普拉斯算子的谱聚类算法
谱聚类 文章目录 谱聚类1. 信息增益的度量2. 谱聚类: 寻找最优的函数向量 f \boldsymbol{f} f2.1 : 寻找一个最优的函数向量 f \boldsymbol{f} f2.2 寻找鲁棒性更强的多个函数向量2.3 谱聚类(spectral clustering)算法 小结 1. 信息增益的度量
由于数据集 X [ x 1 , x 2 ,…
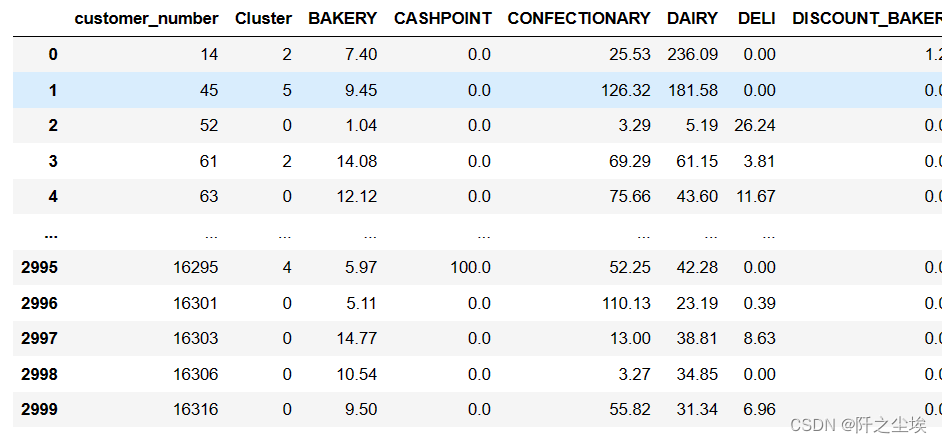
Python数据分析案例27——PCA-K均值-轮廓系数客户聚类
本案例适合应用统计,数据科学,电商专业 K均值对客户进行分类的案例都做烂了......但我认为这个案例还是有一定的价值的,使用了pca,还有轮廓系数寻找最优的聚类个数。
下面来看看 代码准备
导入包
import numpy as np
import pa…
章硕士论文学习——第二章数据挖掘中的聚类方法+时间序列相似性分析
文章目录1 前言2 总结距离度量函数2.1 动态时间弯曲距离 DTW2.2 最长公共子序列距离 LCS2.3 **模式距离 PD1 前言 时间序列相似性度量,是高效时间序列相似比较分析的基础,建立何种度量函数来实现时间序列相似度量直观重要 —— 度量函数的选择!!! 考虑…

专利学习—— 一种基于聚类的水文降雨一致区分析方法
文章目录1 所属领域:属于水文水资源和数据挖掘交叉领域2 步骤分析2.1 根据单场降雨分割规则进行分割,获得单场降雨时间序列2.2 统计单场降雨时间序列的特征量,将每场降雨用一个n维特征向量表示2.3 使用主成分变换,保留特征值贡献率…

专利学习——基于单场降雨类型的降雨站点相似性评价方法
文章目录1 所属领域:水文水资源与数据挖掘技术交叉领域2 步骤分析2.1 提取统计特征量2.2 对2.1中的特征向量,进行均值为0,方差为1的标准化2.3 对特征向量进行聚类2.4 得到N个类别之后,对每个类别降雨场次进行归一化处理࿰…
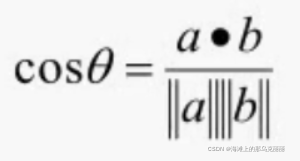
聚类算法介绍(欧氏距离和余弦距离)
1.聚类就是将数据集划分为若干相似对象组成的多个组或簇的过程,使得同一个组或簇相似度最大化,不同簇间相似度最小化。(有时候聚类可以评价相似性)
2.聚类的本质是分组,属于无监督机器学习(只需要特征X&am…

【笔记整理】常见聚类算法
【笔记整理】常见聚类算法 文章目录 【笔记整理】常见聚类算法一、均值偏移 - Mean-shift(★★★★)1、概述 & 图解(“偏心”)2、公式 & 步骤1)基本公式(“偏移量更新圆心”)2ÿ…
机器学习——聚类算法的评分函数
系列文章目录
机器学习——随机森林算法、极端随机树和单颗决策树分类器对手写数字数据进行对比分析_极端随机森林算法
机器学习聚类算法——BIRCH算法、DBSCAN算法、OPTICS算法
机器学习集成学习——Adaboost分离器算法
机器学习之SVM分类器介绍——核函数、SVM分类器的使…

Faiss PQ 乘积量化
Approximate Nearest Neighbor搜索简称ANN。
从宏观上看ANN
brute-force搜索的方式是在全空间进行搜索,为了加快查找的速度,几乎所有的ANN方法都是通过对全空间分割,将其分割成很多小的子空间,在搜索的时候,通过某种…
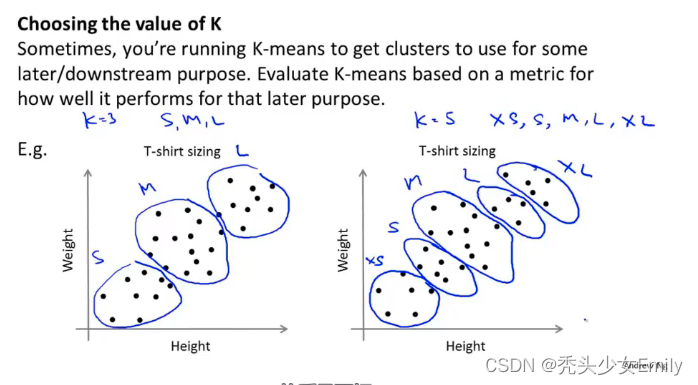
机器学习|监督学习|无监督学习|8:20~9:20
目录
一、监督学习(Supervised learning)
2.1分类(classification)
2.2回归(regression)
泛化能力 Generalization Ability
欠拟合
过拟合
不收敛
2.3 K近邻算法
k近邻分类
k近邻回归
KNN变种
二、无监督学习(Unsupervised learning)
2.1 聚类(c…
【聚类算法】谱聚类spectral clustering
every blog every motto: You can do more than you think. https://blog.csdn.net/weixin_39190382?typeblog
0. 前言
说明: 后续增补
1. 正文
1.1 整体理解
谱聚类(Spectral Clustering)是一种基于图论的聚类方法,将带权无…

聚类算法概要及相关知识准备
聚类的概念
聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。 将物理或抽象对象的集合分成由类似对象组成的多个类或簇(cluster)的过程被称为…
【聚类深度卷积网络:高光谱图像超分】
Hyperspectral image super-resolution using cluster-based deep convolutional networks
(基于聚类深度卷积网络的高光谱图像超分辨率) 近年来,深度卷积神经网络(Deep Convolutionary Neural Networks,CNNs…
机器学习_聚类(k-means)
文章目录 聚类步骤k-means APIKmeans性能评估指标Kmeans性能评估指标API 聚类步骤
k-means通常被称为劳埃德算法,这在数据聚类中是最经典的,也是相对容易理解的模型。算法执行的过程分为4个阶段。
1.首先,随机设K个特征空间内的点作为初始的…

第五章 目标检测中K-means聚类生成Anchor box(工具)
第一种做法
在基于anchor的目标检测算法中,anchor一般都是通过人工设计的。例如,在SSD、Faster-RCNN中,设计了9个不同大小和宽高比的anchor。然而,通过人工设计的anchor存在一个弊端,就是并不能保证它们一定能很好的适…
K-means聚类算法思想以及Python代码实现
K-means聚类算法 K-means也是聚类算法中最简单的一种了,但是里面包含的思想却是不一般。最早我使用并实现这个算法是在学习韩爷爷那本数据挖掘的书中,那本书比较注重应用。看了Andrew Ng的这个讲义后才有些明白K-means后面包含的EM思想。 聚类属于无监督…

基因表达分析聚类分析
基因表达分析聚类&分析
1. Introduction to gene expression analysis
Technology: microarrays vs. RNAseq. Resulting data matricesSupervised (Clustering) vs. unsupervised (classification) learning 微阵列技术: 制备DNA探针阵列并进行互补性杂交。 …
人工智能|机器学习——Canopy聚类算法(密度聚类)
1.简介 Canopy聚类算法是一个将对象分组到类的简单、快速、精确地方法。每个对象用多维特征空间里的一个点来表示。这个算法使用一个快速近似距离度量和两个距离阈值T1 > T2 处理。 Canopy聚类很少单独使用, 一般是作为k-means前不知道要指定k为何值的时候&#…
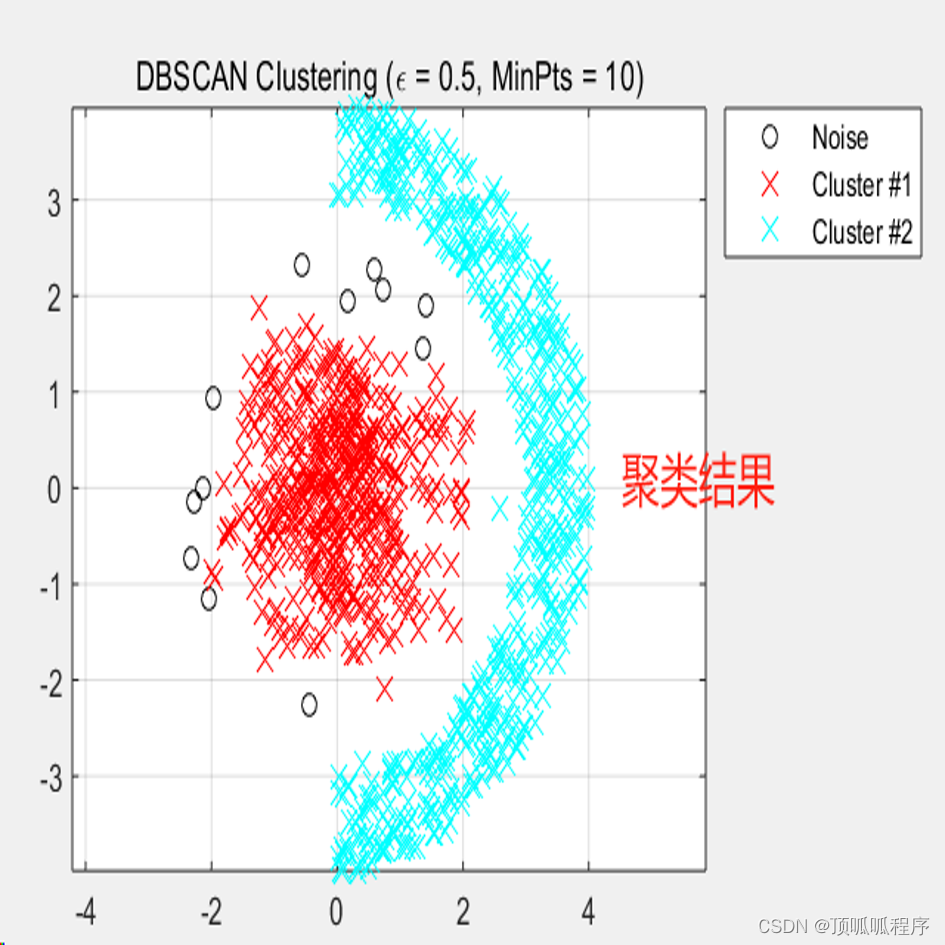
159基于matlab的基于密度的噪声应用空间聚类(DBSCAN)算法对点进行聚类
基于matlab的基于密度的噪声应用空间聚类(DBSCAN)算法对点进行聚类,聚类结果效果好,DBSCAN不要求我们指定集群的数量,避免了异常值,并且在任意形状和大小的集群中工作得非常好。它没有质心,聚类簇是通过将相邻的点连接…
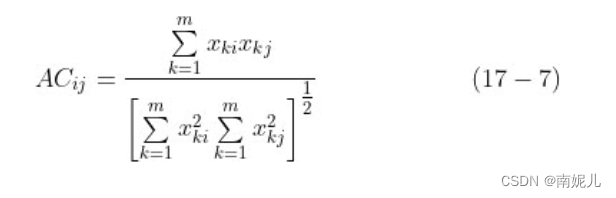
机器学习公式推导与代码实现-无监督学习模型
聚类分析与k均值聚类算法
督学习算法。在给定样本的情况下,聚类分析通过度量特征相似度或者距离,将样本自动划分为若干类别。
距离度量和相似度度量方式
距离度量和相似度度量是聚类分析的核心概念,大多数聚类算法建立在距离度量之上。常用的距离度量方式包括闵氏距离和马…
PCA+DBO+DBSCN聚类,蜣螂优化算法DBO优化DBSCN聚类,适合学习,也适合发paper!
PCADBODBSCN聚类,蜣螂优化算法DBO优化DBSCN聚类,适合学习,也适合发paper!
一、蜣螂优化算法
摘要:受蜣螂滚球、跳舞、觅食、偷窃和繁殖等行为的启发,提出了一种新的基于种群的优化算法(Dung Beetle Optim…

大数据机器学习 - 似然函数:概念、应用与代码实例
文章目录 大数据机器学习 - 似然函数:概念、应用与代码实例一、概要二、什么是似然函数数学定义似然与概率的区别重要性举例 三、似然函数与概率密度函数似然函数(Likelihood Function)定义例子 概率密度函数(Probability Density…

KMeans+DBSCAN密度聚类+层次聚类的使用(附案例实战)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…

机器学习——聚类算法-KMeans聚类
机器学习——聚类算法-KMeans聚类
在机器学习中,聚类是一种无监督学习方法,用于将数据集中的样本划分为若干个簇,使得同一簇内的样本相似度高,不同簇之间的样本相似度低。KMeans聚类是一种常用的聚类算法之一,本文将介…
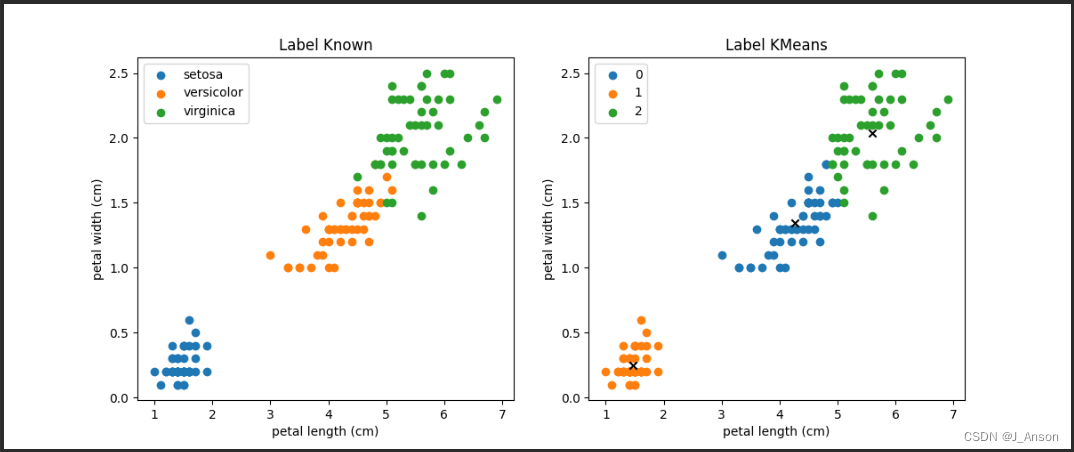
KMeans聚类算法实现
目录
1. K-Means的工作原理
2.Kmeans损失函数
3.Kmeans优缺点
4.编写KMeans算法实现类
5.KMeans算法测试
6.结果 Kmeans是一种无监督的基于距离的聚类算法,其变种还有Kmeans。其中,sklearn中KMeans的默认使用的即为KMeans。使用sklearn相关算法API…
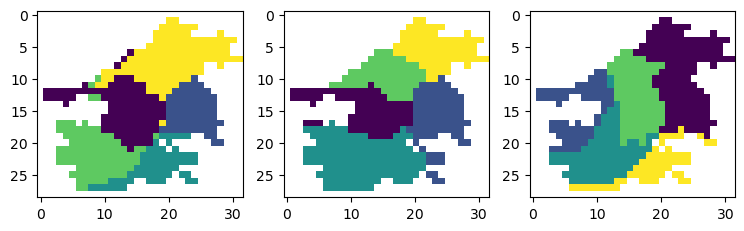
一种栅格数据的空间聚类方法(ACA-Cluster)
本文结合实例详细讲解了如何使用Python对栅格数据进行空间聚类,关注公众号GeodataAnalysis,回复20230616获取示例数据和代码,包含整体的写作思路,上手运行一下代码更容易弄懂。
带有非空间属性的空间数据聚类分析是空间聚类研究的…
要求CHATGPT高质量回答的艺术:提示工程技术的完整指南—第 19 章:聚类提示
要求CHATGPT高质量回答的艺术:提示工程技术的完整指南—第 19 章:聚类提示
聚类提示是一种允许模型根据某些特征或特性将相似数据点分组的技术。
具体做法是向模型提供一组数据点,并要求它根据某些特征或特性将这些数据点分组。
这种技术适…
数学建模【聚类模型】
一、聚类模型简介
“物以类聚, 人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测,也可以探究不同类之间的相关性和…

Unsupervised Learning(无监督学习)
目录
Introduction
Clustering(聚类)
Dimension Reduction(降维) PCA(Principle component analysis,主成分分析)
Word Embedding(词嵌入)
Matrix Factorization(矩…

【数据清洗 | 数据规约】数据类别型数据 编码最佳实践,确定不来看看?
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…
C#,基于密度的噪声应用空间聚类算法(DBSCAN Algorithm)源代码
1 聚类算法
聚类分析或简单聚类基本上是一种无监督的学习方法,它将数据点划分为若干特定的批次或组,使得相同组中的数据点具有相似的属性,而不同组中的数据点在某种意义上具有不同的属性。它包括许多基于差分进化的不同方法。
E、 g.K-均值…
【K-means聚类】
K-means聚类python代码实现 聚类k-means聚类代码 聚类
定义:聚类是一种无监督的机器学习方法,它的主要目的是将数据集中的对象(或点)按照它们之间的相似性分组或聚类。这些聚类(或称为簇)中的对象在某种度…

利用HGT聚类单细胞多组学数据并推理生物网络
单细胞多组学数据允许同时对多种组学数据进行定量分析,以捕捉复杂的分子机制和细胞异质性。然而现有的工具不能有效地推断不同细胞类型的活性生物网络以及这些网络对外部刺激的反应。
来自:Single-cell biological network inference using a heterogen…
R语言作图——热图聚类及其聚类结果输出
代码
不多说了,做个记录,代码如下。
library(pheatmap)
library(RColorBrewer)
# args commandArgs(TRUE)
betafile "twist_common_panel_434.csv"
infofile "twist_common_panel_434.txt"
title "twist_common_panel&qu…
leaflet聚类——leaflet.markercluster
leaflet实现为实现mark聚类渲染提供了很好的插件:leaflet.markercluster。
demo查看地址:Leaflet 聚类渲染
插件下载地址:https://github.com/Leaflet/Leaflet.markercluster
用法
创建一个新的 MarkerClusterGroup,将您的标记…


k-Medoids 聚类系列算法:PAM, CLARA, CLARANS
前言
如果你对这篇文章可感兴趣,可以点击「【访客必读 - 指引页】一文囊括主页内所有高质量博客」,查看完整博客分类与对应链接。 kkk-Means 作为一种经典聚类算法,相信大家都比较熟悉,其将簇中所有的点的均值作为簇中心…
Geospatial Data Science (6): Spatial clustering
Geospatial Data Science (6): Spatial clustering
1.Clustering, spatial clustering, and geodemographics
本节涉及空间观测的统计聚类。许多问题和主题都是复杂的现象,涉及多个维度,难以归纳为一个单一的变量。在统计学术语中,我们把这一类问题称为多变量,而不是在…

python实现DBSCAN(密度聚类)算法
#DBSCAN(密度聚类)算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.cluster import DBSCAN
irisdatasets.load_iris()
xiris.data[:,:4] #取特征空间4个维度
print(x.shape)
plt.scat…

python实现K均值(K-Means分散性聚类)算法
#K均值(K-Means分散性聚类)算法
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import datasets
irisdatasets.load_iris()
xiris.data[:,:4] #取特征空间4个维度
print(x.shape)
plt.scatter(x[:,0],x[:,1],c"re…
22 谱聚类——Spectral Clustering
文章目录 22 谱聚类——Spectral Clustering22.1 背景介绍22.2 模型介绍22.3 模型导出22.4 模型的矩阵形式 22 谱聚类——Spectral Clustering
22.1 背景介绍
我们在一般的聚类过程中,普遍理性而言会有两种思想:
将聚集在一起的点进行聚类(…


客户细分_客户细分初学者指南
客户细分In this post I’m going to talk about something that’s relatively simple but fundamental to just about any business: Customer Segmentation. At the core of customer segmentation is being able to identify different types of customers and then figure…
详解高斯混合聚类(GMM)算法原理
详解高斯混合聚类(GMM)算法原理
摘要:高斯混合聚类(GMM)是一种聚类算法,可以用来对数据进行分类。GMM算法假设数据点是由一个或多个高斯分布生成的,并通过最大似然估计的方法来估计每个簇的高斯分布的参数。在实际应用中,GMM聚类…

4 经典非监督学习算法—K-Means聚类 机器学习基础理论入门
4 经典非监督学习算法—K-Means聚类 机器学习基础理论入门
4.1 高斯混合模型
本节内容主要是介绍单变量高斯混合模型的数学表示和集合表示,虽然在K均值聚类中没有很多用武之地,但是在期望最大算法中,五年会更深入的了解一般意义上的高斯混合…
【零基础学习(面试考点/竞赛不用)】GBDT Gradient-Boosting-Decision-Tree 梯度下降树
站主近期建立了一个自己的网站来发博文,文章已经搬运到了下面的地址:
GBDT Gradient-Boosting-Decision-Tree 梯度下降树
也欢迎大家给我的新网站投稿哈哈,什么主题都可以,可以阅读小站首页的公告。
公众号回复【下载】有精选的…
《机器学习公式推导与代码实现》chapter17-kmeans
《机器学习公式推导与代码实现》学习笔记,记录一下自己的学习过程,详细的内容请大家购买作者的书籍查阅。
聚类分析和k均值聚类算法
聚类分析(cluster analysis)是一类经典的无监督学习算法,在给定样本的情况下,聚类分析通过度量…

人脸聚类原理和算法解释
人脸聚类是指将大量人脸图像根据它们的相似性分组到不同的群集中的过程。人脸聚类通常利用人脸的特征向量表示来度量人脸之间的相似性,并将相似的人脸图像聚集在一起。
以下是人脸聚类的一般原理: 人脸特征提取:对每张人脸图像提取特征向量。…
【C++】Keans聚类算法的C++实现
Kmeans算法的实现步骤: 1、从D中随机取k个元素,作为k个簇的各自的中心。 2、分别计算剩下的元素到k个簇中心的相异度(元素到簇中心的欧氏距离),将这些元素分别划归到相异度最低的簇。 3、根据聚类结果,重…
机械学习模型训练常用代码(随机森林、聚类、逻辑回归、svm、线性回归、lasso回归,岭回归)
一、数据处理(特征工程)
更多pandas操作请参考添加链接描述pandas对于文件数据基本操作 导入的包sklearn
pip3 install --index-url https://pypi.douban.com/simple scikit-learn缺失值处理
#缺失值查看
df.replace(NaN , np.nan, inplaceTrue)#将数…

六、回归与聚类算法 - 模型保存与加载
目录
1、API
2、案例 欠拟合与过拟合线性回归的改进 - 岭回归分类算法:逻辑回归模型保存与加载无监督学习:K-means算法
1、API 2、案例
k_mean聚类结果做推荐组合实践
参考:李航 机器学习
聚类任务
聚类原则:
聚类过程:
聚类将样本D划分为K个不相交的簇
应用场景:
聚类可以寻找数据内在的分布结构,也可以作为分类等任务前置任务。 如:
性能度量
性能度量有两类&am…
机器学习算法基础--层次聚类法
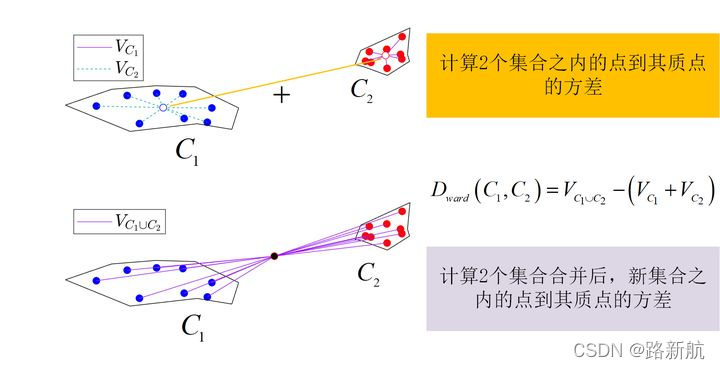
文章目录 1.层次聚类法原理简介2.层次聚类法基础算法演示2.1.Single-linkage的计算方法演示2.2.Complete-linkage的计算方法演示2.3.Group-average的计算方法演示 3.层次聚类法拓展算法介绍3.1.质心法原理介绍3.2.基于中点的质心法3.3.Ward方法 4.层次聚类法应用实战4.1.层次聚…
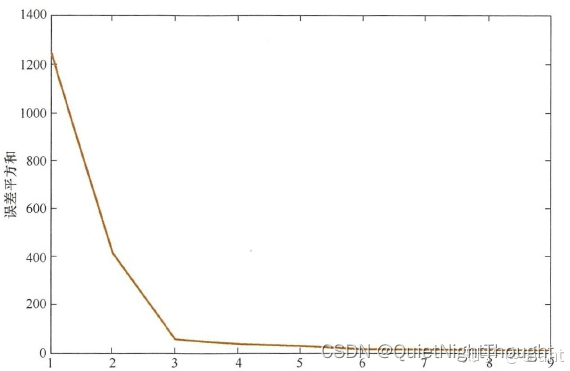
数学建模:K-means聚类手肘法确定k值(含python实现)
原理 当K-means聚类的k值不被指定时,可以通过手肘法来估计聚类数量。 在聚类的过程中,随着聚类数的增大,样本划分会变得更加精细,每个类别的聚合程度更高,那么误差平方和(SSE)会逐渐变小&am…
MATLAB 聚类点簇保存到多个pcd文件中 (19)
MATLAB 聚类点簇保存到多个pcd文件中 (19) 一、算法介绍二、算法实现1.代码2.效果3.自动循环保存文件的代码细节说明一、算法介绍
上一章基于欧式距离,对近邻点进行聚类后,赋予不同颜色进行效果展示,这里对聚类的结果进行保存,主要是将聚类结果按照一定序号,保存为多个…
Python Kmeans聚类挑选合适的K值可视化
无监督
无监督聚类这里使用了Kmeans的聚类方式,适用于凸数据集,当然如果有更好的聚类方式也可以替换的。
输入一系列数据,输出的就是这一系列数据的标签。
看代码
# 导入包
import numpy as np
from sklearn.cluster import KMeans
from …

Kmeans算法在MATLAB中的实现及实例
基本思想
K-means 是一种基本的、经典的聚类方法,也被称为K-平均或K-均值算法,是一种广泛使用的聚类算法。K-Means算法是聚焦于相似的无监督的算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它…

python 机器学习——聚类性能评估
聚类性能评估一、综述二、Rand index(兰德指数)(RI) 、Adjusted Rand index(调整兰德指数)(ARI)三、Silhouette Coefficient(轮廓系数)(s(i))四、建模实例参考文献:一、综述
聚类性能度量亦称聚类“有效性指标”(validity index)。与监督学习中的性能度量作用类似&…
python机器学习——聚类分析简介
聚类分析数据聚类理论理论一、聚类定义二、聚类与分类区别三、聚类分析的目的四、聚类主要方法数据聚类理论理论
一、聚类定义
数据聚类 ( Cluster analysis )是指根据数据的内在性质将数据分成一些聚合类,每一聚合类中的元素尽可能具有相同的特性,不同…

Python实现LRFM模型分析客户价值
作者:Dake1. 分析背景 这是一份某电商平台的销售数据,数据包含2010年4月22到2014年7月24的销售数据。分析该销售数据,可以发现客户价值。现利用KMeans聚类实现LRFM模型来分析客户的价值,便于客户分群,针对性推广&#…
组合数学中将物体放入盒子中的四种情况
在实现生活中, 如何将物体分配到盒子里面是一个非常普通且常见的一个问题。 要解决这个问题需要考虑几种清空。 首先我们把这个问题分成四个类别的的问题。 将不同的物体分配到不同的盒子中 将相同的物体分配到不同的盒子中 将不同的物体分配到相同的盒子中 将相…
智能运维 | 解放程序员,一个工具就能锁定程序故障(下)
在上一篇《智能运维 | 解放程序员,一个工具就能锁定程序故障》文章中我们主要介绍了一种在服务发生故障时自动排查监控指标的算法。算法的第一步利用了概率统计的方式估算每个指标的异常分数,第二步用聚类的方式把异常模式相近的实例聚集在一起形成摘要&…

Day_56-57kMeans 聚类
目录 Day_56-57 k-Means 聚类
一. 基本概念介绍
二. 具体过程
三. 代码实现与解释 1. 导入数据与数据初始化 2. 核心代码 3. 后续信息的补充 4. 距离计算和随机排列
四. 后续的数据分析
五. 运行结果 Day_56-57 k-Means 聚类
一. 基本概念介绍 同我上一篇博客的介绍&…

机器学习之无监督学习:基于聚类的整图分割
前置准备
详情请见我的上一篇博客
基于聚类的图像分割
实现机理
图像分割:利用图像的灰度、颜色、纹理、形状等特征,把图像分为若干个互不重叠的区域,并使这些特征在同一区域内呈现相似性,在不同的区域内存在较明显的差异性。…
模式识别——聚类分析相关问题
1. 聚类分析和判别分析的相关与区别?
答: (1)相关:聚类分析和判别都是多元统计中研究事物分类的基本方法。 (2)区别: ①基本思想不同。聚类分析:根据研究对象特征对研究…
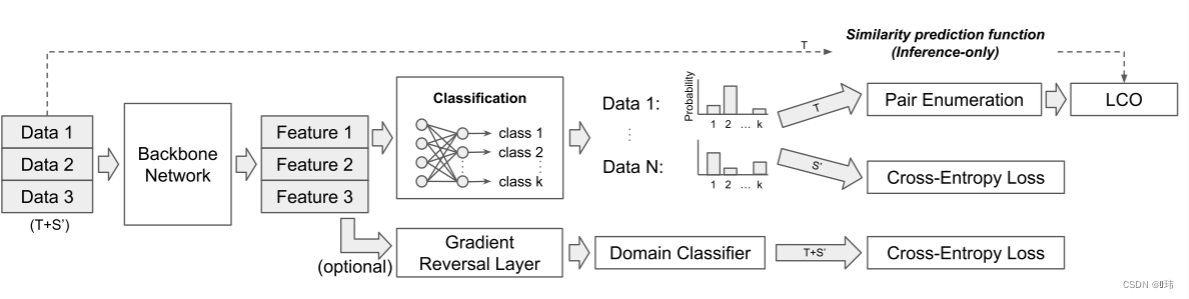
Learning to cluster in order to transfer across domains and tasks (ICLR 2018)
Learning to cluster in order to transfer across domains and tasks (ICLR 2018)
摘要
这篇论文提出一个进行跨域/任务的迁移学除了习任务,并将其作为一个学习聚类的问题。除了特征,我们还可以迁移相似度信息,并且这是足以学习一个相似度…
LeGO-Loam代码解析(二)--- Lego-LOAM的地面点分离、聚类、两步优化方法
1 地面点分离剔除方法
1.1 数学推导 LeGO-LOAM 中前端改进中很重要的一点就是充分利用了地面点,那首先自然是提取 对地面点的提取。 如上图,相邻的两个扫描线束的同一列打在地面上如 点所示,他们的垂直高度差 ,水平距离差 ,计算垂直高度差和水平高度差…
一文详解4种聚类算法及可视化(Python)
在这篇文章中,基于20家公司的股票价格时间序列数据。根据股票价格之间的相关性,看一下对这些公司进行聚类的四种不同方式。 苹果(AAPL),亚马逊(AMZN),Facebook(META&…
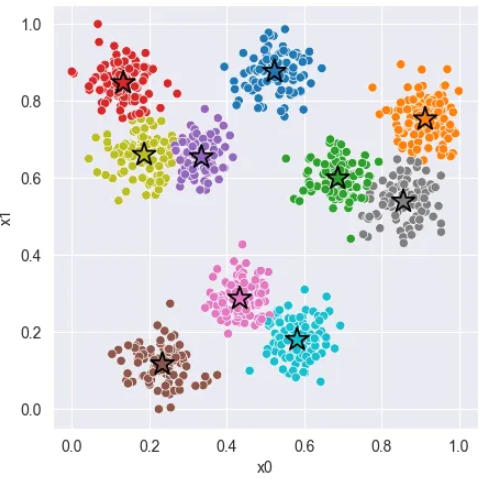
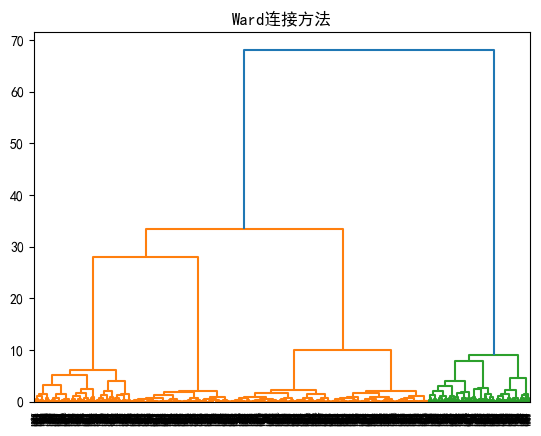
统计学补充概念06-层次聚类
概念
层次聚类是一种将数据点组织成层次结构的聚类方法,它逐步合并或划分数据点以形成聚类。这种方法不需要预先指定要形成的聚类数量,而是通过一系列步骤来建立聚类层次。层次聚类可以分为两种主要类型:凝聚型和分裂型。
凝聚型层次聚类&a…
数分面试题-业务题2
目录标题 1、相关性分析?相关和因果的区别是什么?2、聚类?业务应用场景?常见算法?3、分类?业务应用场景?常见算法?4、回归?业务应用场景?常见算法?…

机器学习之无监督学习:聚类
前置准备
推荐安装Python3.8及以上环境,选择一款适合的开发环境,下载案例所需的实验数据(提取码:BigG),安装必备的第三方库如下图:
K-means方法及应用
实现机理
K-means算法以k为参数&…
深度学习流行网络与数据集
一. 常用网络 深度学习相关的几个比较著名的网络,AlexNet、VGG、GoogleNet、ResNet。 模型 AlexNet VGG GoogleNet ResNet 时间 2012 2014 2014 2015 层数 8 19 22 152 Top-5错误率 15.3% …
机器学习中的特征工程
机器学习中的特征工程
什么是特征工程
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。特征工程指的是把原始数据转变为模型的训练数据的过程,它的目的就是获取更好的训练数据特征,使得机器学习模型逼近这个上限。
构…
聚类分析-Python
聚类分析-Python
K-均值聚类
#读取数据
import psycopg2
import os
import pandas as pd
import numpy as np
#import math
from sklearn.cluster import KMeans
#from sklearn import metrics
import matplotlib.pyplot as plt
#from sklearn.cluster import DBSCAN
#from …

MATLAB与大数据:如何应对海量数据的处理和分析
第一章:引言 在当今数字化时代,大数据已经成为了各行各业的核心资源之一。海量的数据源源不断地涌现,如何高效地处理和分析这些数据已经成为了许多企业和研究机构面临的重要挑战。作为一种功能强大的数学软件工具,MATLAB为我们提供…
使用词袋模型(BoW)测试提取图像的特征点和聚类中心
文章目录 环境配置代码测试 环境配置
(1) 导入opencv,参考链接
https://blog.csdn.net/Aer_7z/article/details/132612369(2) 安装numpy 激活虚拟环境的前提下,输入:
pip install numpy(3) 安装sklearn 激活虚拟环境的前提下,输…

python基础学习10【哑变量处理、离散化(等宽法、等频法、基于聚类分析的方法)、fit()、聚类模型评价指标、 分类模型评价指标、ROC曲线】
哑变量处理
特点:对于一个类别型特征,若其取值有m个,则经过哑变量处理后就变成了m个二元特征,并且这些特征互斥,每次只有一个激活,这使得数据变得稀疏。
get_dummise()函数:
pd.get_dummies(…
聚类sklearn实践
k均值聚类 K-Means
非常大的 n_samples, 中等的 n_clusters,将样本分成 n 组等方差的样本来聚类数据
metric:点之间的距离
步骤: 随机选K个聚集点 每个数据被赋值最近聚集点类别 使用每个聚集中心点更新 重复直到聚点移动小于阈值 返回K个…

机器学习算法基础--聚类问题的评价指标
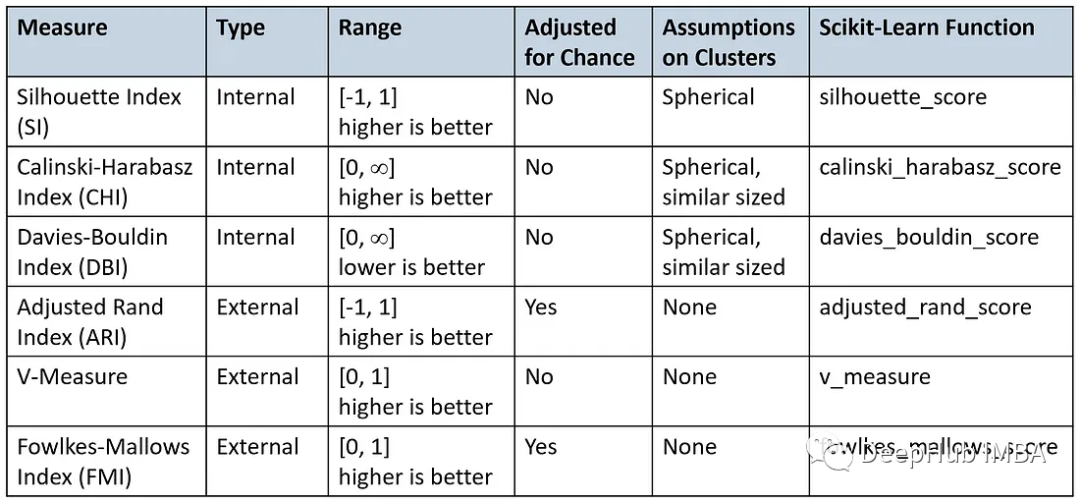
1.聚类问题指标评价的意义 聚类算法是非监督学习最常用的一种方法,性能度量是衡量学习模型优劣的指标,也可作为优化学习模型的目标函数。聚类性能度量根据训练数据是否包含标记数据分为两类,一类是将聚类结果与标记数据进行比较,称…
Sklearn 聚类算法的性能评估
聚类算法的性能评估是什么?
聚类是无监督学习的一种常用技术,用于将相似的数据点分组在一起。然而在实施聚类算法后,一个关键的问题便是如何评估其性能或质量。由于聚类是无监督的,因此评估其性能相对更为复杂。本文将探讨多种用于评估聚类性能的指标,包括肘部法则、轮廓…
(完全解决)如何输入一个图的权重,然后使用sklearn进行谱聚类
文章目录 背景输入点直接输入邻接矩阵 背景
网上倒是有一些关于使用sklearn进行谱聚类的教程,但是这些教程的输入都是一些点的集合,然后根据谱聚类的原理,其会每两个点计算一次亲密度(可以认为两个点距离越大,亲密度越…
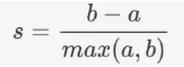
K近邻算法(KNN)K-means聚类算法
K近邻算法(KNN)
有监督机器学习
KNN是分类算法
1.思想:在特征空间中,如果一个样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个类别,则该样本也属于这个类别。简单来说就是你离那个样本最近你就属于那个类别。
2.运用欧式距…

K-MEANS算法+实战
聚类和分类有什么区别?
分类算法的样本是带标签的,而聚类算法的样本是不带标签的 k-means 例子 实战数据(两列,以空格隔开)
import numpy as np
import matplotlib.pyplot as plt # 载入数据
data np.genfrom…

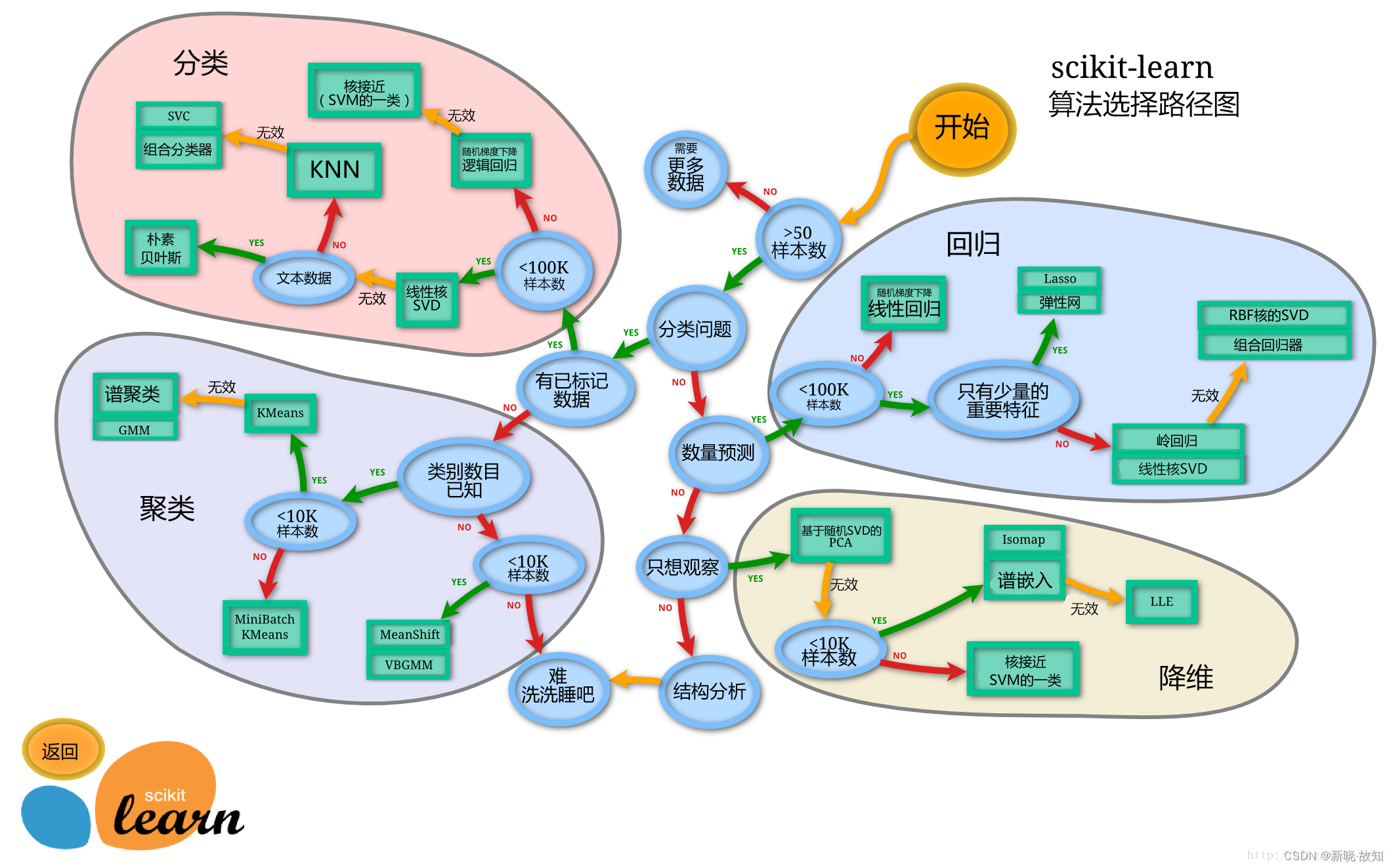
sklearn机器学习通用解决方案
从 START 开始,首先看数据的样本是否 >50,小于则需要收集更多的数据。
由图中,可以看到算法有四类,分类,回归,聚类,降维。
其中 分类和回归是监督式学习,即每个数据对应一个 la…
聚类之详解FCM算法原理及应用
原文地址为:
聚类之详解FCM算法原理及应用【之前】 该文的pdf清晰版已被整理上传,方便保存学习,下载地址: https://download.csdn.net/download/on2way/10394655 (一)原理部分 模糊C均值(Fuzzy …
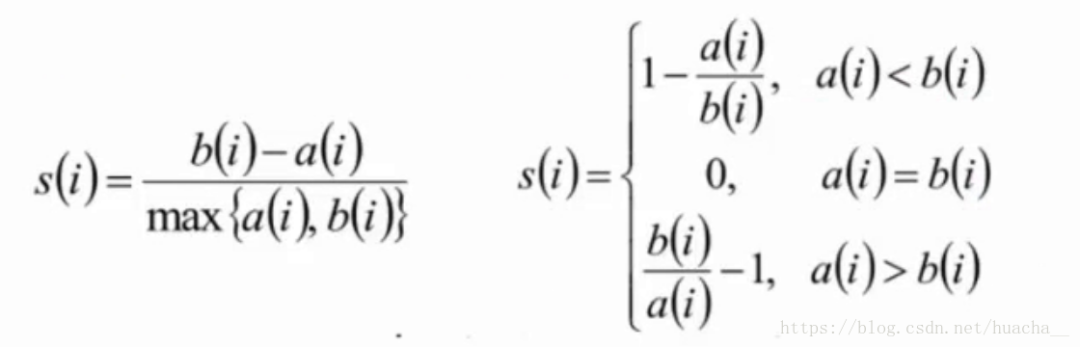
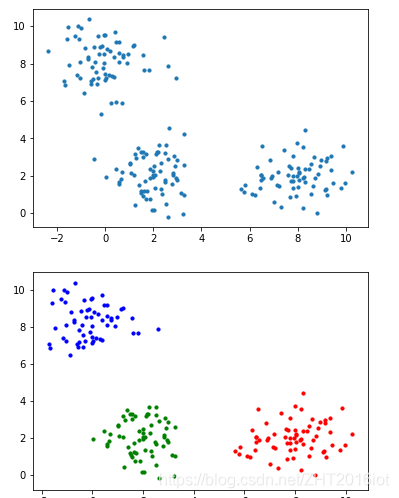
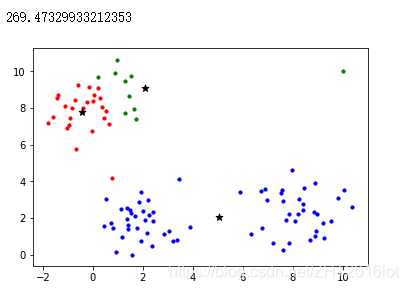
【机器学习】DBSCAN密度聚类算法(理论 + 图解)
文章目录一、前言二、DBSCAN聚类算法三、DBSCAN算法步骤四、算法的理解五、常用评估方法:轮廓系数一、前言
之前学聚类算法的时候,有层次聚类、系统聚类、K-means聚类、K中心聚类,最后呢,被DBSCAN聚类算法迷上了。
为什么呢&…

【Python】sklearn机器学习之Birch聚类算法
文章目录基本原理sklearn调用基本原理
BIRCH,即Balanced Iterative Reducing and Clustering Using Hierarchies,利用分层的平衡迭代规约和聚类,特点是扫描一次数据就可以实现聚类,
而根据经验,一般这种一遍成功的算…
机器学习知识点:不均衡数据的采样方法
下采样方法
ClusterCentroids https://imbalanced-learn.org/stable/references/generated/imblearn.under_sampling.ClusterCentroids.html ClusterCentroids是一种基于聚类方法的欠采样算法,通过生成聚类中心来进行欠采样。
ClusterCentroids算法通过使用K均值算…
支持向量机设计思想和相关面试题
支持向量机从idea到优化方法的全流程 支持向量机的key idea? key idea1: 待分类点在决策边界法向量上的投影大于决策边界到原点的距离,则是正样本 key idea2: 如何求支持向量的间隔 选取一个正样本X 一个负样本X- 求X - X-在决策边界法向量上的投影长度 key idea3 …
层次聚类AGNES与DIANA
1. AGNES
AGNES是一种采用自底向上合并策略的聚类算法,其思想为:初始将所有样本看成一个簇,然后在每一轮过程中将距离最近的两个簇合并为一个簇,簇的个数不断减少到人为指定的聚类簇数K,终止算法。该算法关键在于如何…
密度聚类DBSCAN
1.相关概念
DBSCAN是基于密度的聚类算法,该类算法假设聚类结构能够通过样本分布的紧密程度确定(样本密度均匀分布),它通常考虑的是样本之间的可连接性,并以最大连接性确定聚类簇。要搞懂该算法,首先要理清楚几个概念&…

K-means及其改进
一. k-means
1.算法流程
给定数据样本集D{x1,x2,...,xm}D\{x_1,x_2,...,x_m\}D{x1,x2,...,xm},k-means欲将DDD划分成K个簇C{c1,c2,...,ck}C\{c_1,c_2,...,c_k\}C{c1,c2,...,ck}并且簇之间没有交集。其目标是最小化平方误差和: E∑i1k∑x∈ci∣∣x−ui…

计算机视觉的基本面试题
1.描述图像大小,通道数? 长:331 宽:500 通道数:3
2.img[:,:,0]的含义 0,1,2表示图像的RGB通道
3.
如图的iread设置参数0的含义?
就是读取灰度图像
4.
如何让该图片颜色显示正常…
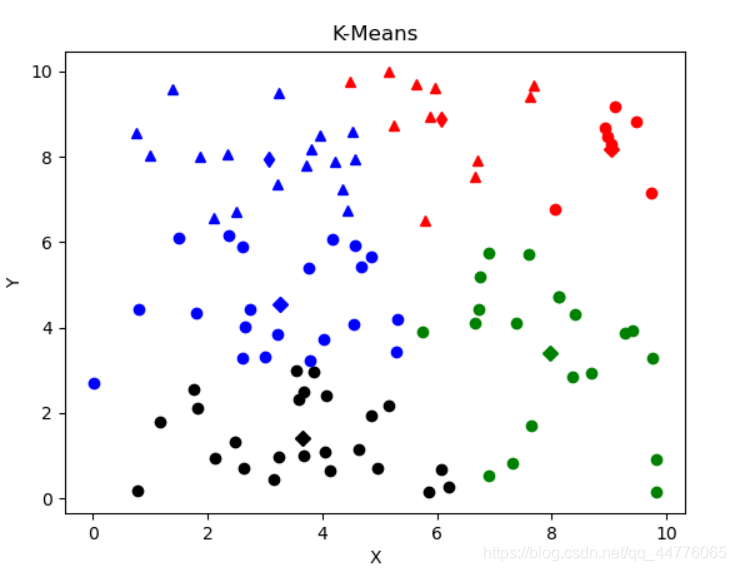
【聚类】K-Means聚类
cluster:簇
原理:
这边暂时没有时间具体介绍kmeans聚类的原理。简单来说,就是首先初始化k个簇心;然后计算所有点到簇心的欧式距离,对一个点来说,距离最短就属于那个簇;然后更新不同簇的簇心&a…
K-means算法与K-means++算法的异同
经典Kmeans算法是最常用的一种聚类算法。感觉在西瓜书里面最容易看懂的,而且最容易用的一个算法便是k-mean算法,算法实现的流程十分简单,可以简单将其划分为4个步骤:
Step1:选定聚类中心,从数据集中随机选取K个样本作…

rbf神经网络和bp神经网络,rbf神经网络是什么意思
Rbf神经网络原理
rbf神经网络即径向基函数神经网络(RadicalBasisFunction)。
径向基函数神经网络是一种高效的前馈式神经网络,它具有其他前向网络所不具有的最佳逼近性能和全局最优特性,并且结构简单,训练速度快。
…
神经网络算法图像识别,神经网络算法图怎么看
rbf神经网络算法是什么?
RBF神经网络算法是由三层结构组成,输入层至隐层为非线性的空间变换,一般选用径向基函数的高斯函数进行运算;从隐层至输出层为线性空间变换,即矩阵与矩阵之间的变换。
RBF神经网络进行数据运算时需要确认…
八种点云聚类方法(二)— KMeans
传统机器学习聚类的方法有很多种,并且很多都能够应用在点云上。这是由于聚类方法一般是针对于通用样本,只是样本的维度有所不同。对于三维点云来说,其样本的维度为3。这里主要介绍几种典型的方法及其实现方式,包括DBSCAN、KMeans等…
八种点云聚类方法(一)— DBSCAN
传统机器学习聚类的方法有很多种,并且很多都能够应用在点云上。这是由于聚类方法一般是针对于通用样本,只是样本的维度有所不同。对于三维点云来说,其样本的维度为3。这里主要介绍几种典型的方法及其实现方式,包括DBSCAN、KMeans等…
机器学习 K-Means算法
文章目录1. K-Means原理2. k-means 代码3. 结果3.1 关于 matplotlib.pyplot 中绘制点的形状和颜色3.2 分类的结果K-Means算法用来进行聚类,需要我们指定类别,即指定K的大小,通过类心不断改变,完成分类,这是无监督学习 …
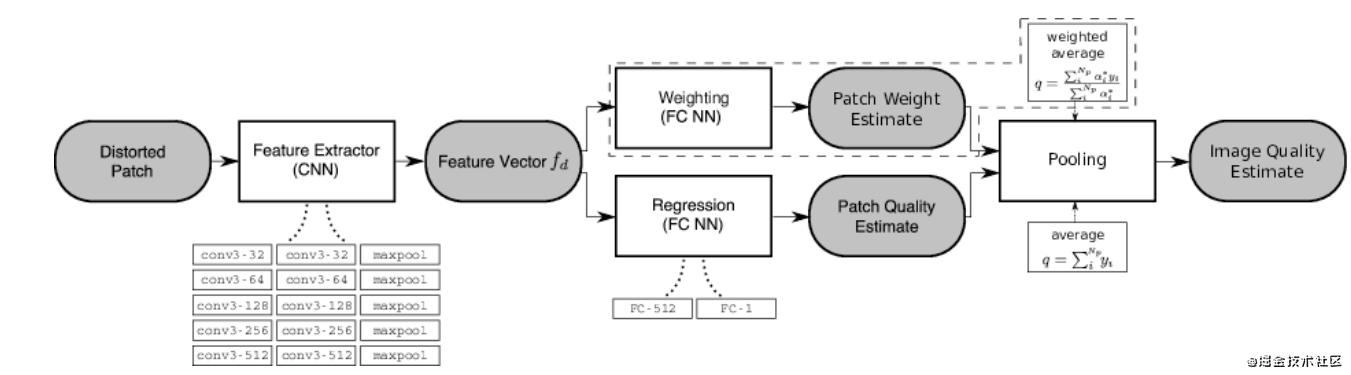
图像质量评估论文 | Deep-IQA | IEEETIP2018
主题列表:juejin, github, smartblue, cyanosis, channing-cyan, fancy, hydrogen, condensed-night-purple, greenwillow, v-green, vue-pro, healer-readable, mk-cute, jzman, geek-black, awesome-green, qklhk-chocolate
贡献主题:https://github.…

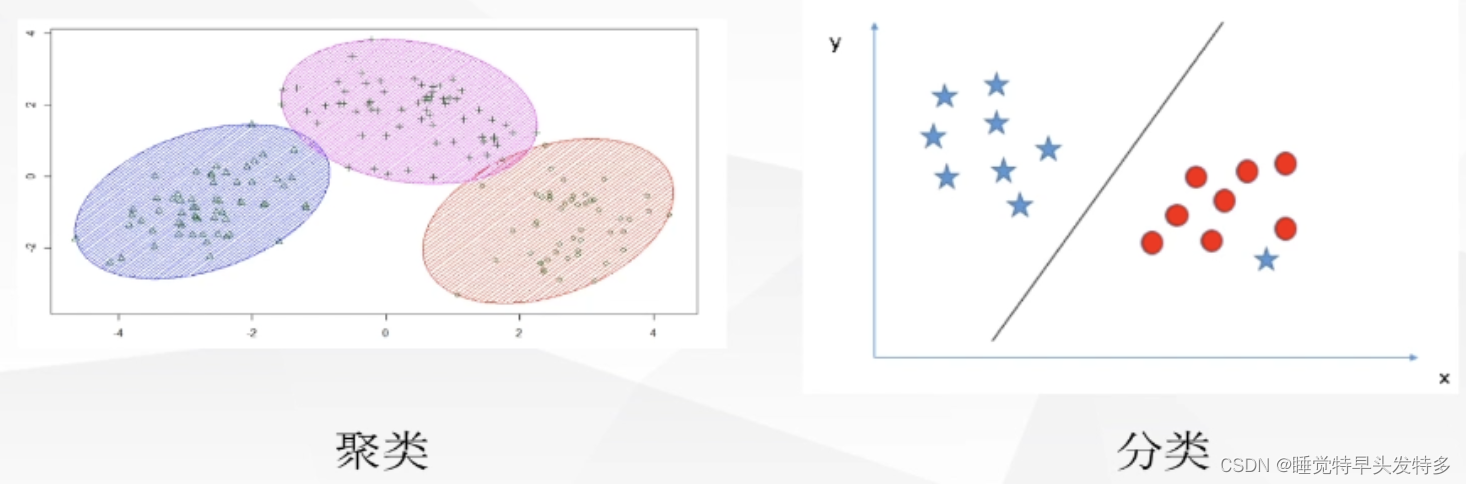
以最易懂的人话讲分类和聚类算法(建议分享和收藏)
以最易懂的人话讲分类和聚类算法(建议分享)
今天在使用聚类方法进行客户价值分析时遇到了个问题,将我卡住了半个小时,实际上现在想来是一个很简单的问题,但是大家都知道,一个人脑子短路时就是会一个小学数…
计算机视觉:基于BOW的图像检索与识别
目录
一、基础简介
二、实验步骤
1、特征提取
2、学习“视觉词典(visual vocabulary)”
3、根据IDF原理,计算视觉单词的权
4、针对特征集,根据视觉词典进行量化
5、对输入图像,根据TF-IDF转化成视觉单词的频率直…

【研一小白论文速览1】
《CDIMC-net: Cognitive Deep Incomplete Multi-view Clustering Network》
认知的深度不完全多视图聚类网络,如题目所说,本篇论文主要是提出了一个新的网络架构。虽然不完全多视图聚类这个方向已经有很多工作再做了,而且也取得了不错的效果…
Scikit-learn聚类方法代码批注及相关练习
一、代码批注
代码来自:https://scikit-learn.org/stable/auto_examples/cluster/plot_dbscan.html#sphx-glr-auto-examples-cluster-plot-dbscan-py
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets …

大数据分析案例-基于KMeans和DBSCAN算法对汽车行业客户进行聚类分群
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…
opencv进阶08-K 均值聚类cv2.kmeans()介绍及示例
K均值聚类是一种常用的无监督学习算法,用于将一组数据点分成不同的簇(clusters),以便数据点在同一簇内更相似,而不同簇之间差异较大。K均值聚类的目标是通过最小化数据点与所属簇中心之间的距离来形成簇。 当我们要预测…
从聚类(Clustering)到异常检测(Anomaly Detection):常用无监督学习方法的优缺点
一、引言 无监督学习是机器学习的一种重要方法,与有监督学习不同,它使用未标记的数据进行训练和模式发现。无监督学习在数据分析中扮演着重要的角色,能够从数据中发现隐藏的模式、结构和关联关系,为问题解决和决策提供有益的信息。…
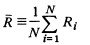
Davies-Bouldin指数(DBI)
参考http://blog.sina.com.cn/s/blog_65c8baf901016flh.html 用途:聚类算法中评估判断簇的个数是否合适(用来选择k) 原理:计算所有簇的类内距离和类间距离的比值(类内/类间),比值越小越好。即希望类间距离越大,类内距离越小(数据越…

Matlab K-means聚类算法对多光谱遥感图像进行分类(一)
Matlab K-means聚类算法对多光谱遥感图像进行分类
作者: 白艺亭
测试了下matlab自带kmeans函数,作者编写函数,以及ENVI下的Kmeans方法,对比其效果,代码及结果图展示见下。(K均值聚类的matlab代码…
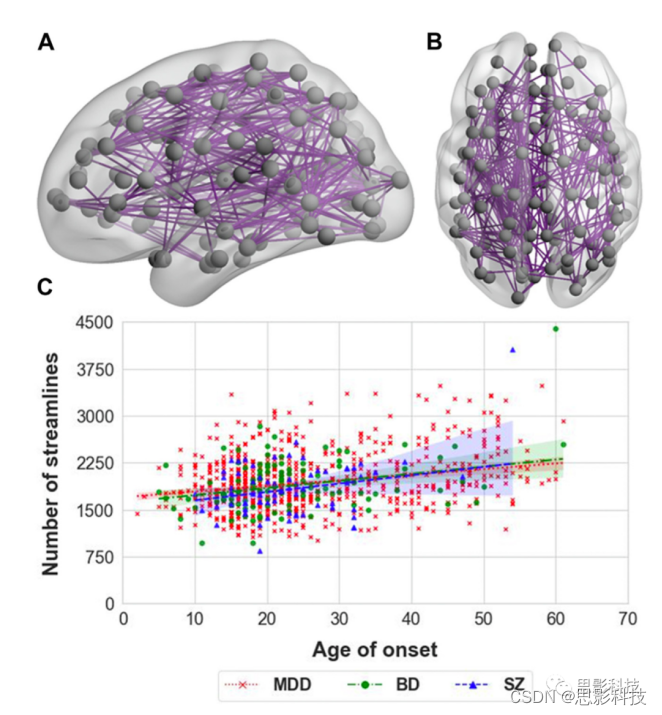
情感性和精神病性障碍之间结构性脑连接的共有和特定模式
脑结构连接改变与精神分裂症(SZ)、双相情感障碍(BD)和重度抑郁障碍(MDD)等精神疾病的病理生理学有关。然而,目前尚不清楚这些连接异常中的哪一部分是疾病特有的,哪些是精神障碍和情感障碍的共同特征。本文基于大样本精神分裂症、双相情感障碍、重度抑郁患…

追踪静息态下的全脑动态连接
自发波动是我们在人脑无特定任务下观察到的神经信号,其发生的时间尺度从毫秒到数十分钟不等。然而,基于静息态功能磁共振成像对大脑内在组织的研究在很大程度上没有考虑到时间变异性的存在和潜力。目前大多数检验功能连接(FC)的方法默认地假设这个连接性…

semi、unsupervised1
记录1leetcode文献leetcode
题目:530. 二叉搜索树的最小绝对差
二叉树特点是每个结点最多只能有两棵子树,且有左右之分 二叉查找树(Binary Search Tree),(又:二叉搜索树,二叉排序树…
PAMAE: Parallel k-Medoids Clustering with High Accuracy and Efficiency论文复现
PAMAE: Parallel k-Medoids Clustering with High Accuracy and Efficiency论文复现
项目介绍
项目github地址:PAMAE项目
PAMAE: Parallel k-Medoids Clustering with High Accuracy and Efficiency 是SIGKDD2017一篇关于k-medoids并行聚类的论文,论文…
判断聚类 n_clusters
目录 基本原理
代码实现:
肘部法则(Elbow Method):
轮廓系数(Silhouette Coefficient)
Gap Statistic(间隙统计量):
Calinski-Harabasz Index(Calinski-…
Python迁移学习:机器学习算法
机器学习是人工智能中一个流行的子领域,其涉及的领域非常广泛。流行的原因之一是在其策略下有一个由复杂的算法、技术和方法论组成的综合工具箱。该工具箱已经经过了多年的开发和改进,同时新的工具箱也在持续不断地被研究出来。为了更好地使用机器学习工…
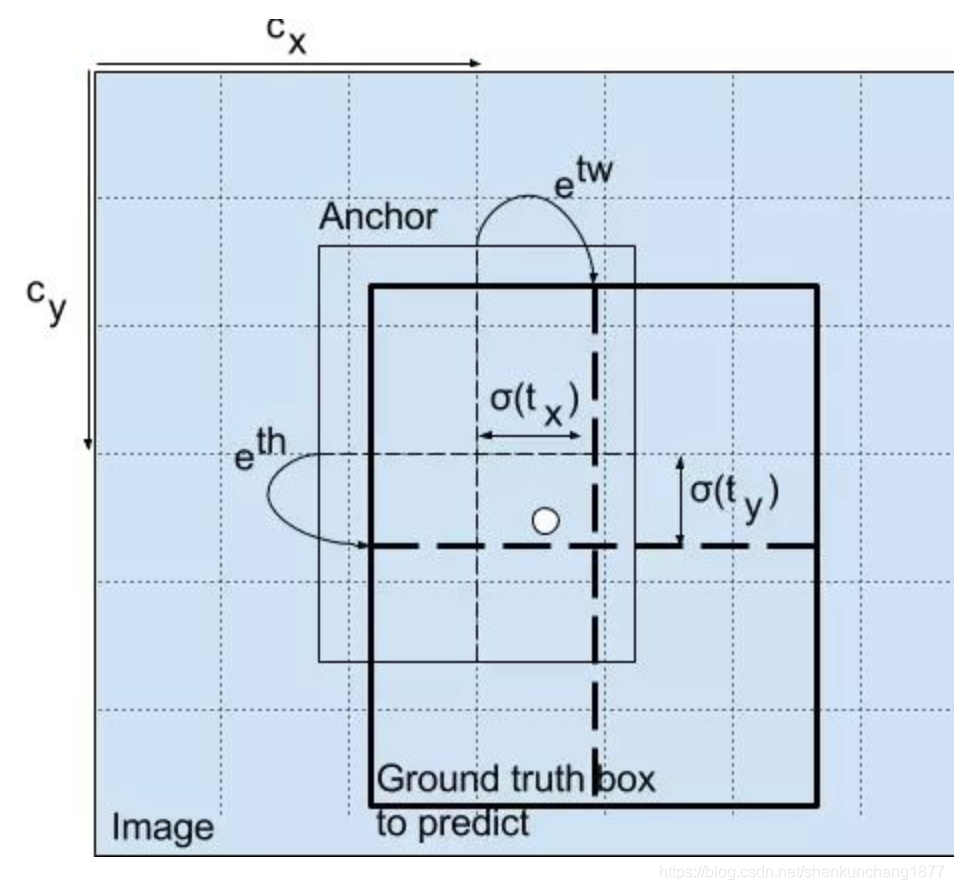
YOLO v2和V3 关于设置生成anchorbox,Boundingbox边框回归的个人理解
虽然阅读量不是很多,但是没想到居然能得到这么多收藏和赞,大家提出的问题,我会不断更新,尽量把过程解释得让大家都能了解清楚。
PS:这篇文章是自己学习纪录下的笔记,主要是通过阅读paddle复现的yolov3源码…

机器学习 — python(sklearn / scipy) 实现层次聚类,precomputed自定义距离矩阵
文章目录机器学习 — python(sklearn / scipy) 实现层次聚类,precomputed自定义距离矩阵一. scipy实现(一) 函数说明1. linkage2. fcluster(二) 示例含完整算法二、sklearn实现(一) 函数说明(二) 完整算法补充基于预计算(precomputed)的距离矩…
Python数据挖掘-RFM模型K-means聚类分析-航空公司客户价值分析
使用教材:《Python数据分析与挖掘实战》 模型:RFM模型 算法:K-means聚类;其他方法还用到了层次聚类 数据:需要数据的可以评论里call。
内容:
(1)案例: 航空公司客户价值分析
&…
基于Kohonen网络的聚类算法
1.案例背景
1.1 Kohonen网络 Kohonen网络是自组织竞争型神经网络的一种,该网络为无监督学习网络,能够识别环境特征并自动聚类。Kohonen神经网络是芬兰赫尔辛基大学教授Teuvo Kohonen 提出的,该网络通过自组织特征映射调整网络权值,使神经网络收敛于一种表示形态。在这一形态中…
K-Means(K-均值)聚类算法
目录
K-Means 算法
K-Means 术语
K 值如何确定
K-Means 场景
美国总统大选摇争取摆选民
电商平台用户分层
给亚洲球队做聚类
编辑
其他场景
K-Means 工作流程
K-Means 开发流程
K-Means的底层代码实现
K-Means 的评价标准 K-Means 算法
对于 n 个样本点来说&am…
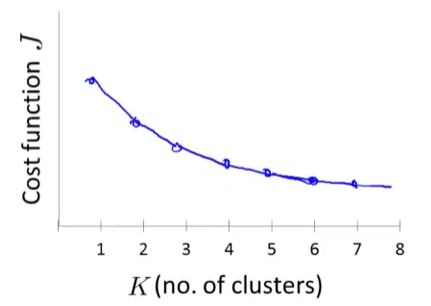
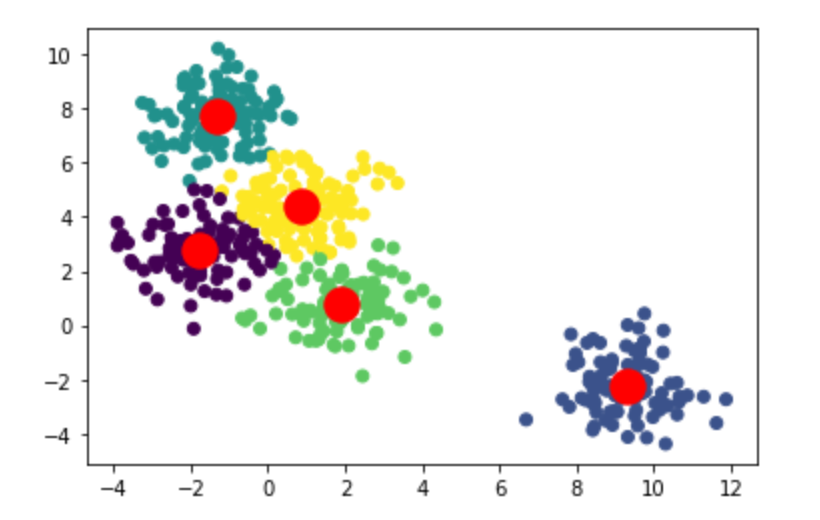
K-means(K均值)
K-means(K均值) 这一系列的博客前面介绍的线性回归(linear regression)、逻辑回归(logistics regression)、神经网络(neural network)和支持向量机(support vector machineÿ…
点云数据做简单的平面的分割 三维场景中有平面,杯子,和其他物体 实现欧式聚类提取 对三维点云组成的场景进行分割
点云分割是根据空间,几何和纹理等特征对点云进行划分,使得同一划分内的点云拥有相似的特征,点云的有效分割往往是许多应用的前提,例如逆向工作,CAD领域对零件的不同扫描表面进行分割,然后才能更好的进行空洞修复曲面重建,特征描述和提取,进而进行基于3D内容的检索,组合…
【K 均值聚类】02/5:简介
一、说明 k-mean算法是一种聚类算法,它的主要思想是基于数据点之间的距离进行聚类。K-means聚类是一种无监督的机器学习算法。让我们再解释一下这句话。聚类分析的目标是将数据划分为同类聚类。每个聚类中的点彼此之间比其他聚类中的点更相似。 无监督机器学习是在没…

数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法...
全文链接:http://tecdat.cn/?p30131 最近我们被客户要求撰写关于上海空气质量指数的研究报告。本文向大家介绍R语言对上海PM2.5等空气质量数据(查看文末了解数据免费获取方式)间的相关分析和预测分析,主要内容包括其使用实例&…
机器学习——聚类算法一
机器学习——聚类算法一 文章目录 前言一、基于numpy实现聚类二、K-Means聚类2.1. 原理2.2. 代码实现2.3. 局限性 三、层次聚类3.1. 原理3.2. 代码实现 四、DBSCAN算法4.1. 原理4.2. 代码实现 五、区别与相同点1. 区别:2. 相同点: 总结 前言
在机器学习…
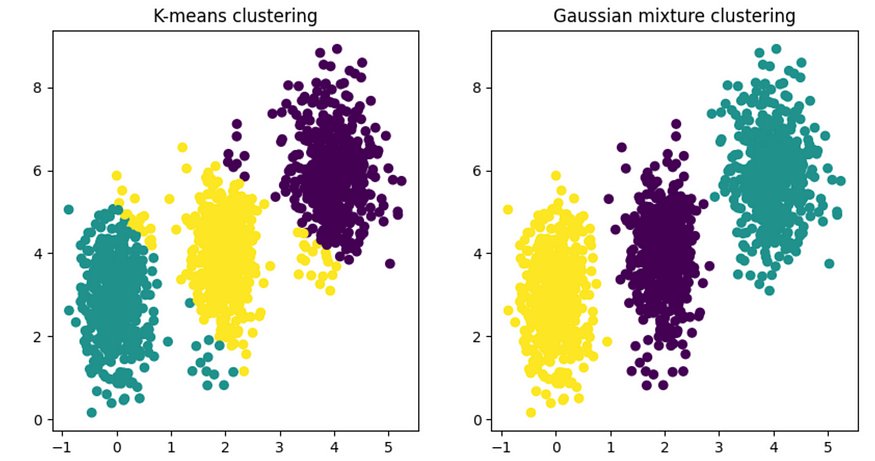
使用高斯混合模型进行聚类
一、说明 高斯混合模型 (GMM) 是一种基于概率密度估计的聚类分析技术。它假设数据点是由具有不同均值和方差的多个高斯分布的混合生成的。它可以在某些结果中提供有效的聚类结果。 二、Kmean算法有效性 K 均值聚类算法在每个聚类的中心周围放置一个圆形边…
超图聚类论文阅读1:Kumar算法
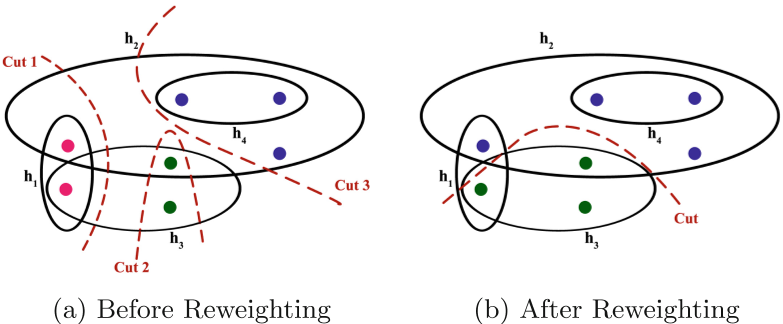
超图聚类论文阅读1:Kumar算法 《超图中模块化的新度量:有效聚类的理论见解和启示》 《A New Measure of Modularity in Hypergraphs: Theoretical Insights and Implications for Effective Clustering》 COMPLEX NETWORKS 2020, SCI 3区 具体实现源码见…
回归与聚类算法系列②:线性回归
目录
1、定义与公式
2、应用场景
3、特征与目标的关系分析
线性回归的损失函数
为什么需要损失函数
损失函数
⭐如何减少损失
4、优化算法
正规方程
梯度下降
优化动态图
偏导
正规方程和梯度下降比较
5、优化方法GD、SGD、SAG
6、⭐线性回归API
7、实例&#…
基于MATLAB实现KECA、PCA和KPCA的多阶段发酵过程监测方法毕业设计(完整源码+说明文档+PPT+开题报告+数据)
文章目录,完整源码在文末 1. 研究目标2. 主要研究内容3. 技术路线4. 预期成果5. 功能说明6. 参考文献7. 完整仿真源码下载 1. 研究目标
实现基于KECA的青霉素发酵过程故障监测
2. 主要研究内容
1.针对KPCA监测算法在数据降维过程中簇结构信息丢失的问题ÿ…

基于纹理特征的kmeas聚类的图像分割方案
Gabor滤波器简介
在图像处理中,以Dennis Gabor命名的Gabor滤波器是一种用于纹理分析的线性滤波器,本质上是指在分析点或分析区域周围的局部区域内,分析图像中是否存在特定方向的特定频率内容。Gabor滤波器的频率和方向表示被许多当代视觉科学…

【机器学习基础】K-Means聚类算法
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!相对完整的机器学习基础教学! ⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战…
【机器学习】聚类(一):原型聚类:K-means聚类
文章目录 一、实验介绍1. 算法流程2. 算法解释3. 算法特点4. 应用场景5. 注意事项 二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. Kmeans类a. 构造函数b. 闵可夫斯基距离c. 初始化簇心d. K-means聚类e. 聚类结果可视化 2. 辅助函数3. 主函数a. 命令…
基于k-均值聚类的图像分割
参考链接:
https://blog.csdn.net/LucasXu01/article/details/90764759?utm_mediumdistribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-0-90764759-blog-125619862.235v39pc_relevant_3m_sort_dl_base3&spm1001.2101.3001.4242…
机器学习---数字聚类案例
1、K-means找中心点和数据点分类例子
import numpy as npdef loadDataSet(fileName):dataMat []fr open(fileName)for line in fr.readlines():curLine line.strip().split(\t)fltLine map(float,curLine)dataMat.append(fltLine)return dataMatdef distEclud(vecA,vecB):…
机器学习之聚类-2D数据类别划分
无监督学习(Unsupervised Learning)
机器学习的一种方法,没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群。 方式一:站着或坐着 方式二:全身或半身 方式三:蓝眼球或不是蓝眼球 …
聚类分析 | 聚类有效性评价指标外部NMI(MATLAB)
指标解释
聚类有效性评价指标中的外部NMI(Normalized Mutual Information,归一化互信息)是一种常见的外部有效性指标,用于评估聚类结果与真实标签之间的相似度。NMI从信息论的角度出发,衡量两个聚类结果的共享信息量。
NMI的计算基于聚类结果和真实标签之间的互信息以及…

六、回归与聚类算法 - 逻辑回归与二分类
线性回归欠拟合与过拟合线性回归的改进 - 岭回归分类算法:逻辑回归模型保存与加载无监督学习:K-means算法
1、应用场景 2、原理
2.1 输入 2.2 激活函数 3、损失以及优化
3.1 损失 3.2 优化 4、逻辑回归API 5、分类的评估方法
5.1 精确率和召回率 5.2…
聚类分析 | 聚类有效性评价指标外部AR,RI,MI,HI(MATLAB)
指标介绍
聚类有效性评价指标外部AR,RI,MI,HI 聚类有效性评价指标是用于评估聚类结果质量的工具,它们帮助研究人员理解聚类算法的性能以及聚类结果与真实标签或预期结构之间的符合程度。外部指标主要考察聚类结果与真实类别之间的关系。以下是关于AR(Adjusted Rand Index,调…
【详解算法流程+程序】DBSCAN基于密度的聚类算法+源码-用K-means和DBSCAN算法对银行数据进行聚类并完成用户画像数据分析课设源码资料包
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。 与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇, 并可在噪声的空间数据…

数据挖掘原理与实践 第四章作业
P147
4.2
假设数据挖掘的任务是将如下的8个点(用 (x,y) 代表位置)聚类为三个簇:A1 (2,10),A2(2,5),A3(8,4),B1(5,8),B2(7,5),B3(6,4),C1(1,2),C2(4,9)。距离…

2、k-means聚类算法sklearn与手动实现
本文将对k-means聚类算法原理和实现过程进行简述 算法原理
k-means算法原理较简单,基本步骤如下:
1、假定我们要对N个样本观测做聚类,要求聚为K类,首先选择K个点作为初始中心点; 2、接下来,按照距离初始中…
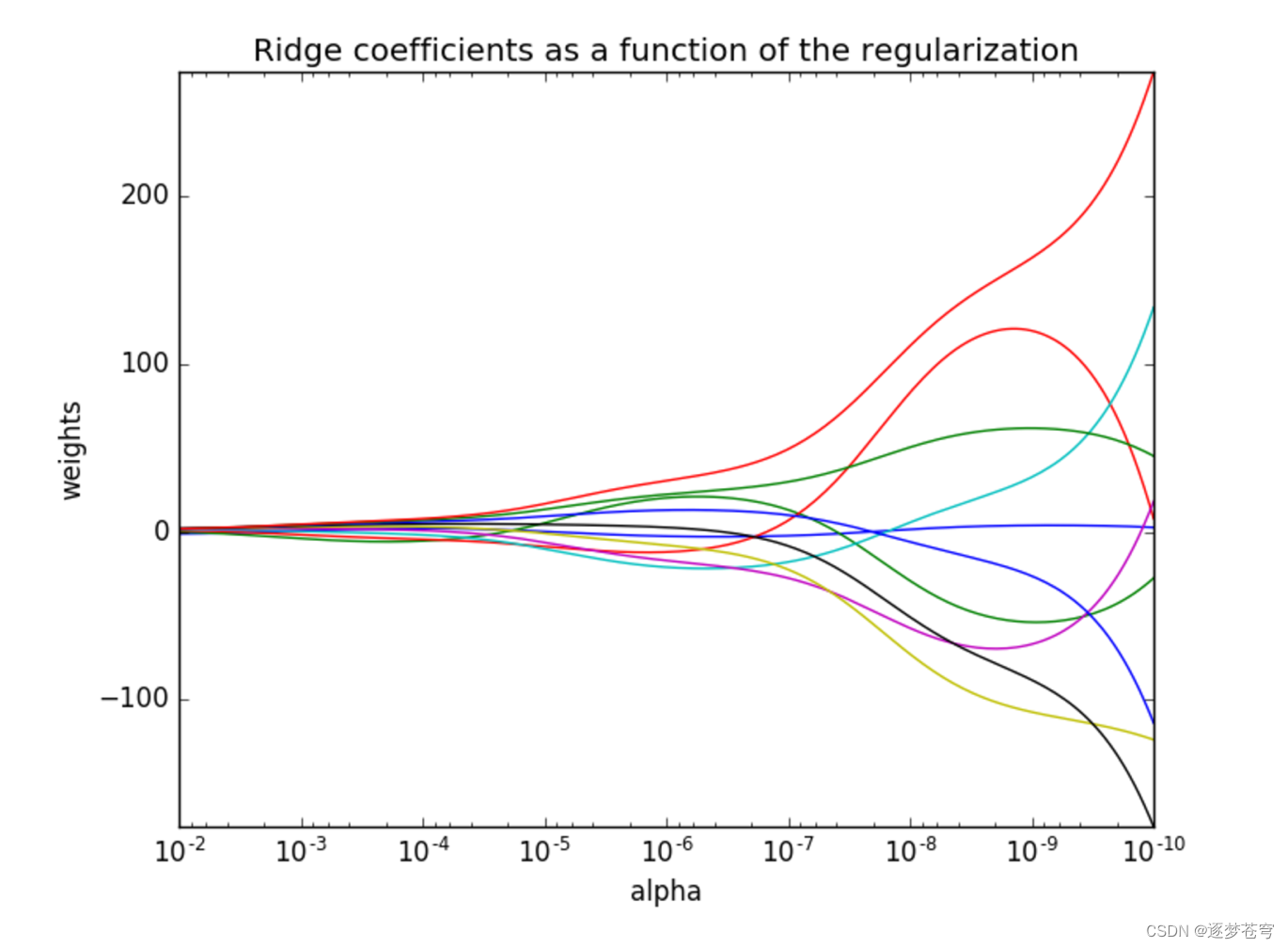
回归与聚类算法系列④:岭回归
目录
1. 背景
2. 数学模型
3. 特点
4. 应用领域
5. 岭回归与其他正则化方法的比较
6、API
7、代码
8、总结 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅长web应用开发、数…

k-means像素聚类
使用K-means进行像素聚类
python通过使用K-means对像素聚类以此进行图像分割
K-means聚类简介:
K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一。K-means算法的基本思想是:以空间中k个点为中心进行聚类࿰…
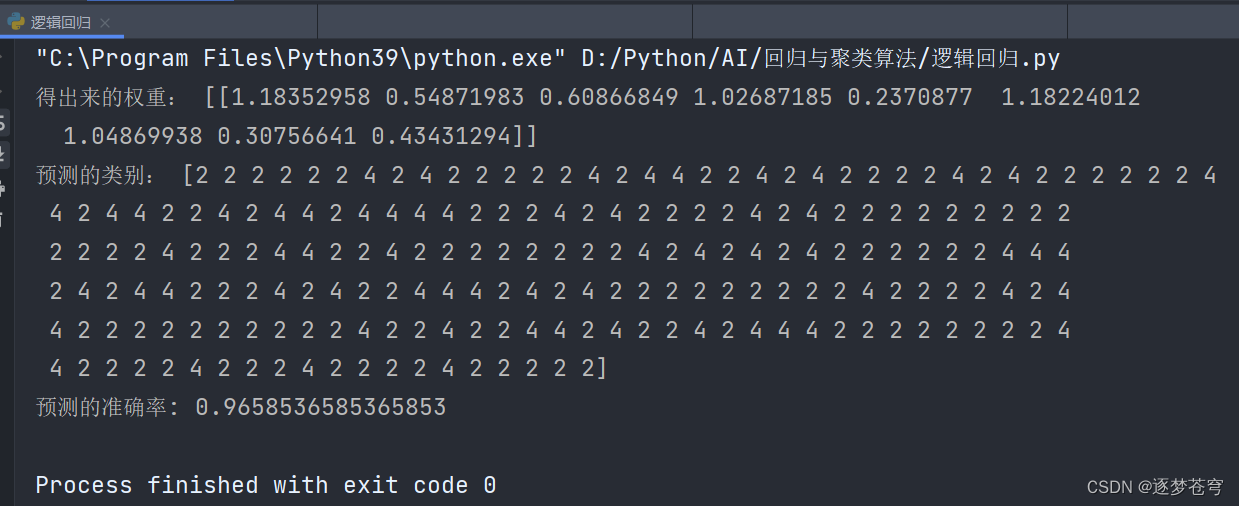
回归与聚类算法系列⑤:逻辑回归
目录
1、介绍
2、原理
输入
激活函数
3、损失及其优化
损失函数
优化
4、API
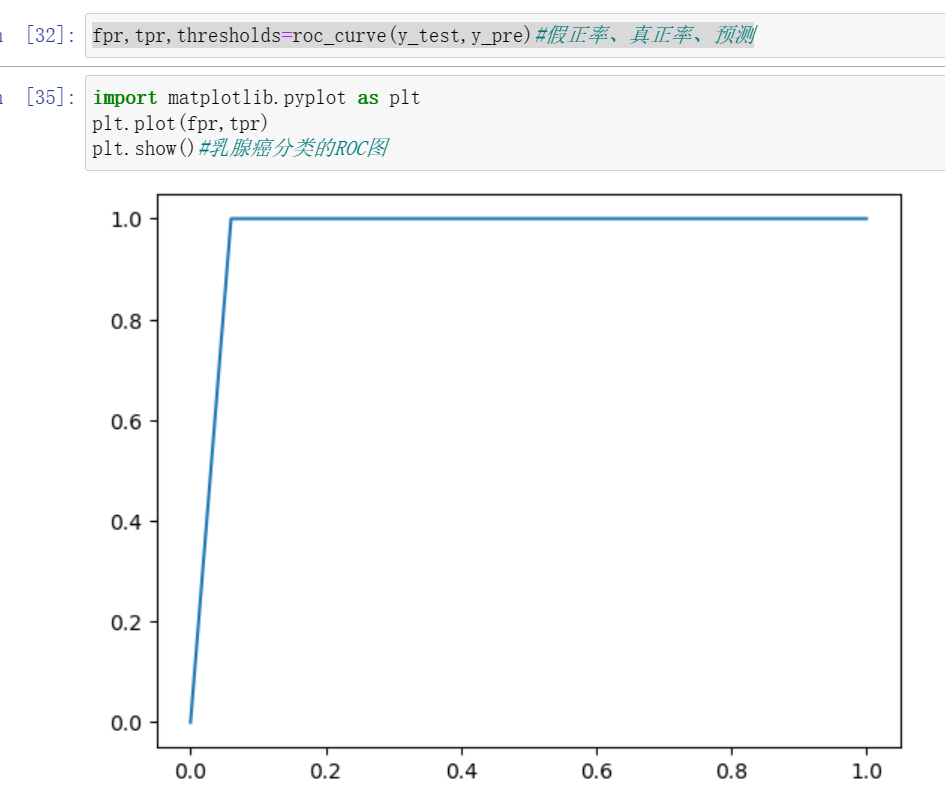
5、案例:乳腺癌肿瘤预测
数据集
代码 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习࿰…
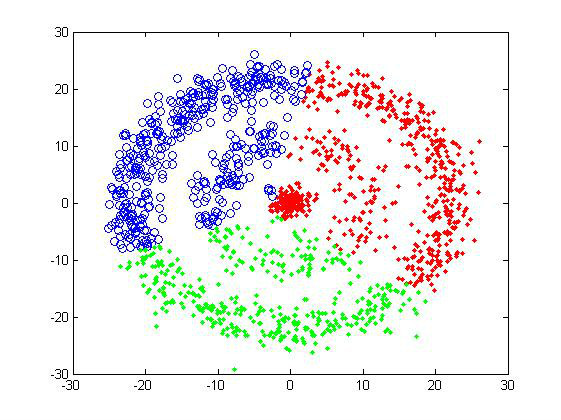
聚类算法实践(一)——层次聚类、K-means聚类
摘要: 所谓聚类,就是将相似的事物聚集在一 起,而将不相似的事物划分到不同的类别的过程,是数据分析之中十分重要的一种手段。比如古典生物学之中,人们通过物种的形貌特征将其分门别类,可以说就是 一种朴素的人工聚类。…

时间序列论文-聚类和异常检测(一)
这篇文章摘自,知乎:https://www.zhihu.com/question/29507442/answer/1212624591?utm_id0 写的很好,就记录一下。 两篇关于时间序列的论文 原文链接:两篇关于时间序列的论文 这次整理的就是清华大学裴丹教授所著的两篇与时间序…

时间序列论文-聚类和异常检测(二)
同样摘自知乎的回答:https://www.zhihu.com/question/29507442/answer/1212624591?utm_id0 正巧之前做过时间序列 的异常检测项目,这里介绍几种尝试过的方法,也算是抛砖引玉 吧,欢迎大家讨论交流~
背景与定义
时间序列异常 检测…
机器学习——聚类之K-means(未完)
这是我看下来,最简单的内容,哭了,K-means,so nice K-means,由于太过简单,不需要数学推导时,一时间甚至无从下指
首先,K-means需要提前锚定几个点,然后让所有数据样本根据…

浅谈我对DB INDEX (Davies Bouldin index)的理解
本人原创作品,转载请注明出自网易博客双鱼传说! 说实话,国内的资料少之又少,去搜下GOOGLE大神的KEYWORD好了,我看到的不是求助就是论文摘要。这到底是个啥东西,为什么有人问没人说呢? 不…

机器学习——聚类算法
0、前言:
机器学习聚类算法主要就是两类:K-means和DBSCAN聚类:一种无监督的学习,事先不知道类别(相当于不用给数据提前进行标注),自动将相似的对象归到同一个簇中 1、K-means:
原理…
K-means 聚类算法学习笔记
K-means 聚类算法 是一种无监督学习算法,用来将 n n n 个样本点分成 k k k 类,使得整个数据集的误差平方和 S S E SSE SSE 最小。在本例中,样本点是指平面直角坐标系上的点,聚类中心也是平面直角坐标系上的点,而每个…

groupby后选取列和不选取列的区别
1.首先通过groupby得到DataFrameGroupBy对象, 比如df.groupby(flee)
2.然后选择需要研究的列, 比如[age], 这样我们就得到了一个SeriesGroupby, 它代表每一个组都有一个Series
3.对SeriesGroupby进行操作, 比如.mean(), 相当于对每个组的Series求均值
4.如果df.groupby(flee)后…
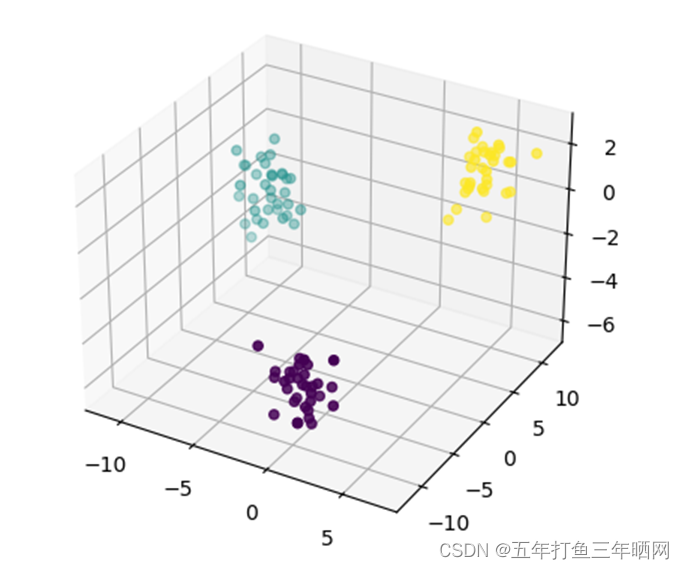
Numpy实现K-Means聚类
问题描述:
数据放在数据文件中(不得放在程序中),第一行是数据的个数,以后各行是各个点的x,y,z坐标。读取文本文件数据,并用K-means方法输出聚类中心k-means 算法接受输入量k;然后将n个数据对象划分为 k个聚类以便使得…
6.2 构建并评价聚类模型
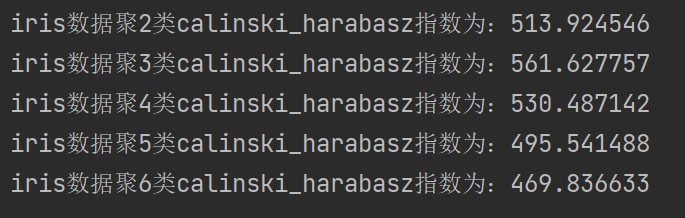
6.2 构建并评价聚类模型 6.2.1 使用sklearn估计器构建聚类模型1、聚类的概念2、常见聚类方法3、使用sklearn估计器构建聚类模型4、sklearn估计器代码:构建K-Means聚类模型 6.2.2 评价聚类模型1、FMI评价法2、轮廓系数评价法3、Calinski-Harabasz指数评价法 6.2.1 使…

二值贝叶斯滤波计算4d毫米波聚类目标动静属性
机器人学中有些问题是二值问题,对于这种二值问题的概率评估问题可以用二值贝叶斯滤波器binary Bayes filter来解决的。比如机器人前方有一个门,机器人想判断这个门是开是关。这个二值状态是固定的,并不会随着测量数据变量的改变而改变。就像门…

基于流形距离的聚类算法
在家蹲了一个月照顾小孩,完全被洗脑了,程序代码是神马,能吃么?
今天回来,决定练练脑,瞎看了会儿黎曼几何的入门知识,突然觉得没准儿可以用在聚类上,检索了一下,果然有相…
基于R做宏基因组进化树+丰度柱状图TreeBar带聚类树的堆叠柱形图
写在前面
同之前一样,重分析需要所以自己找了各路代码借鉴学习,详情请参考 R语言绘制带聚类树的堆叠柱形图 , 实操效果如下: 步骤
表格预处理
选取不同样本属水平的物种丰度图(绝对和相对水平都可以,相对…
【聚类】DBCAN聚类
OPTICS是基于DBSCAN改进的一种密度聚类算法,对参数不敏感。当需要用到基于密度的聚类算法时,可以作为DBSCAN的一种替代的优化方案,以实现更优的效果。
原理
基于密度的聚类算法(1)——DBSCAN详解_dbscan聚类_root-ca…

资源分享| 4种聚类算法及可视化(Python)
在这篇文章中,基于20家公司的股票价格时间序列数据。根据股票价格之间的相关性,看一下对这些公司进行聚类的四种不同方式。 苹果(AAPL),亚马逊(AMZN),Facebook(META&…
从方法到目标了解什么是机器学习?
一、什么是机器学习
1、简述 机器学习是 人工智能(AI) 和计算机科学的一个分支,专注于利用数据和算法来模仿人类的学习方式,逐步提高其准确性。过去几十年来,存储和处理能力方面的技术进步催生了一些基于机器学习的创新产品,例如 Netflix 的推荐引擎和自动驾驶汽车。 机…
机器学习第十一课--K-Means聚类
一.聚类的概念
K-Means算法是最经典的聚类算法,几乎所有的聚类分析场景,你都可以使用K-Means,而且在营销场景上,它就是"King",所以不管从事数据分析师甚至是AI工程师,不知道K-Means是”不可原谅…
使用Velodyne传感器生成的点云进行快速且稳健的聚类处理:一个C++实践指南
一、引言
点云数据在现今的自动驾驶、机器人以及三维建模领域中扮演着越来越重要的角色。其中,Velodyne传感器作为业内知名的激光雷达产品,其生成的点云数据质量上乘。然而,对于这样的数据进行有效、快速、稳健的聚类处理仍是一个挑战。本文…
【生物信息学】使用谱聚类(Spectral Clustering)算法进行聚类分析
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
3. IDE
三、实验内容
0. 导入必要的工具
1. 生成测试数据
2. 绘制初始数据分布图
3. 循环尝试不同的参数组合并计算聚类效果
4. 输出最佳参数组合
5. 绘制最佳聚类结果图
6. 代码整合 一、实验介绍…

BIRCH算法全解析:从原理到实战
目录 一、引言什么是BIRCH算法BIRCH算法的应用场景文章目标和结构概述 二、BIRCH算法基础CF(Clustering Feature)树的概念数据点簇簇的合并和分裂 BIRCH的时间复杂度和空间复杂度BIRCH vs K-means和其他聚类算法 三、BIRCH算法的技术细节CF树的构建节点和…
Python机器学习零基础理解AffinityPropagation亲和力传播聚类
如何解决社交媒体上的好友推荐问题?
想象一下,一个社交媒体平台希望提供更加精准的好友推荐功能,让用户能更容易地找到可能成为好友的人。这个问题看似简单,但当面对数百万甚至数千万的用户时,手动进行好友推荐就变得几乎不可能。
解决这个问题的一个方案就是使用机器学…
Cluster聚类算法大比拼:性能、应用场景和可视化对比总结
聚类分析是一种无监督学习方法,广泛应用于各种领域,包括市场细分、社交网络分析、生物信息学和推荐系统等。通过将相似的对象组合在一起,聚类有助于揭示数据的内在结构,从而为进一步的数据分析和决策提供有用的洞见。本文深入探讨了14种不同的聚类算法,包括KMeans、DBSCAN…
【Python机器学习】零基础掌握OPTICS聚类
你是否曾经困扰于这样的如何将相似的商品以最优的方式推荐给你的客户?
假设你是一个电商网站的运营经理,有成千上万的商品和用户,但不知道如何有效地将相似的商品分组以便推荐。或者是一个环保组织的数据分析师,希望找出那些具有相似环境影响的地区。这些问题都需要一种可…
【论文复现】基于多模态深度学习方法的单细胞多组学数据聚类(【生物信息学】实验二:多组学数据融合:scMDC)
目录
一、实验介绍
1. 论文:基于多模态深度学习方法的单细胞多组学数据聚类
Abstract
2. Github链接
二、实验环境
0. 作者要求
1. 环境复现
实验一
实验二(本实验)
2. 库版本介绍
实验一
实验二
3. IDE
三、实验内容
1. 用法…
【数据挖掘】数据挖掘、关联分析、分类预测、决策树、聚类、类神经网络与罗吉斯回归
目录 一、简介二、关于数据挖掘的经典故事和案例2.1 正在影响中国管理的10大技术2.2 从数字中能够得到什么?2.3 一个网络流传的笑话(转述)2.4 啤酒与尿布2.5 网上书店关联销售的案例2.6 数据挖掘在企业中的应用2.7 交叉销售 三、数据挖掘入门3.1 什么激发了数据挖掘…
聚类分析 | 聚类分析(K-means、层次聚类、密度聚类、高斯混合模型)
一、引言
聚类算法是一种无监督学习方法,旨在将相似的数据点分组成为若干个簇,使得同一簇内的数据点相似度高,不同簇之间的相似度低。聚类算法在数据挖掘、模式识别、图像分析等领域具有重要应用。
聚类算法的作用在于发现数据的内在结构和…
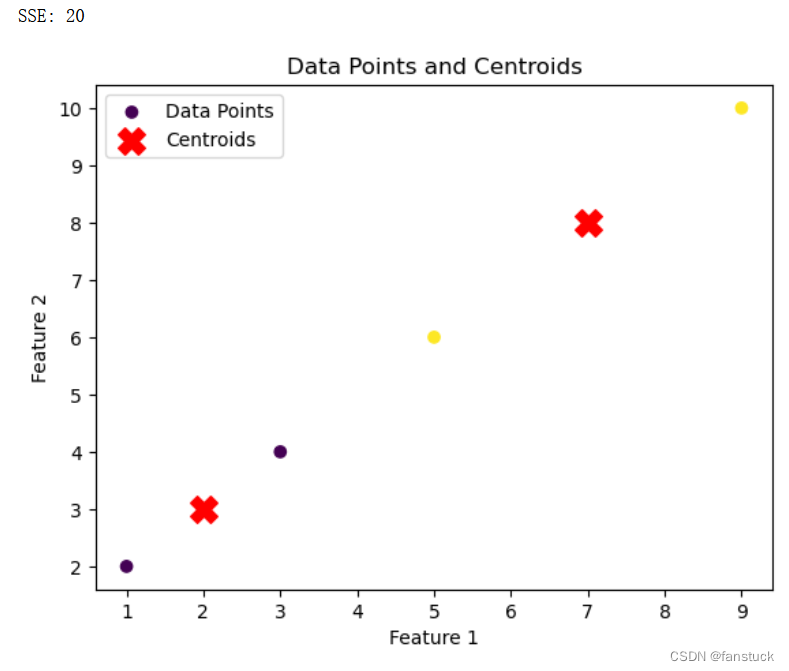
第2篇 机器学习基础 —(4)k-means聚类算法
前言:Hello大家好,我是小哥谈。聚类算法是一种无监督学习方法,它将数据集中的对象分成若干个组或者簇,使得同一组内的对象相似度较高,不同组之间的对象相似度较低。聚类算法可以用于数据挖掘、图像分割、文本分类等领域…
Python3实现10种顶流聚类算法
聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。
有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法以及每种算法的不同配置。在本教程中,你将发现如何在 pytho…
损失函数(Loss Function)一文详解-聚类问题常见损失函数Python代码实现+计算原理解析
损失函数(Loss Function)一文详解-聚类问题常见损失函数Python代码实现计算原理解析
前言
损失函数无疑是机器学习和深度学习效果验证的核心检验功能,用于评估模型预测值与实际值之间的差异。我们学习机器学习和深度学习或多或少都接触到了损失函数,但…
第十一章《搞懂算法:聚类是怎么回事》笔记
聚类是机器学习中一种重要的无监督算法,可以将数据点归结为一系列的特定组合。归为一类的数据点具有相同的特性,而不同类别的数据点则具有各不相同的属性。
11.1 聚类算法介绍
人们将物理或抽象对象的集合分成由类似 的对象组成的多个类的过程被称为聚…

机器学习 - DBSCAN聚类算法:技术与实战全解析
目录 一、简介DBSCAN算法的定义和背景聚类的重要性和应用领域DBSCAN与其他聚类算法的比较 二、理论基础密度的概念核心点、边界点和噪声点DBSCAN算法流程邻域的查询聚类的形成过程 参数选择的影响 三、算法参数eps(邻域半径)举例说明:如何选择…
计算机毕设 基于机器学习的文本聚类 - 可用于舆情分析
文章目录 0 简介1 项目介绍1.1 提取文本特征1.2 聚类算法选择 2 代码实现2.1 中文文本预处理2.2 特征提取2.2.1 Tf-idf2.2.2 word2vec 2.3 聚类算法2.3.1 k-means 2.3.2 DBSCAN2.4 实现效果2.4.1 tf-idf k-means聚类结果2.4.2 word2vec k-means 聚类结果 最后 0 简介
今天学…
适用于4D毫米波雷达的目标矩形框聚类
目录
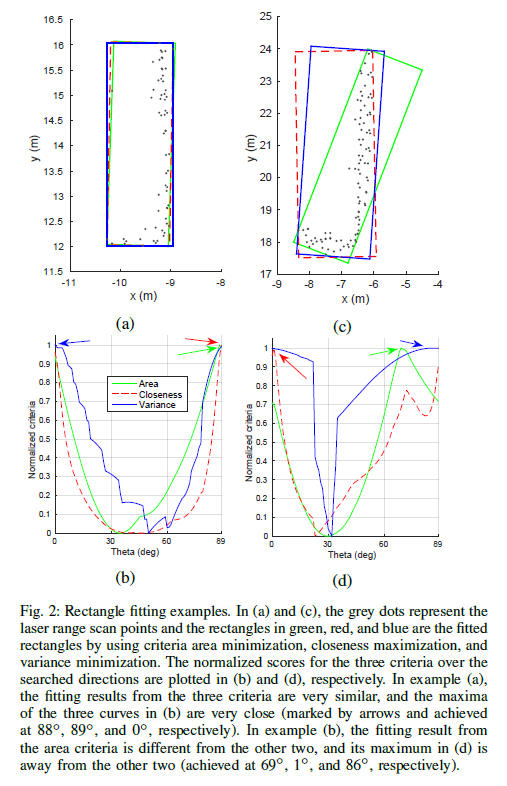
一、前言
二、点云聚类分割
三、基于方位搜索L型拟合
四、评价准则之面积最小化
五、评价准则之贴合最大化
六、评价准则之方差最小化 一、前言 对于多线束雷达可以获取目标物体更全面的面貌,在道路中前向或角雷达可能无法获取目标车矩形框但可以扫到两边…

数据挖掘:分类,聚类,关联关系,回归
数据挖掘:
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤其sql要学&…
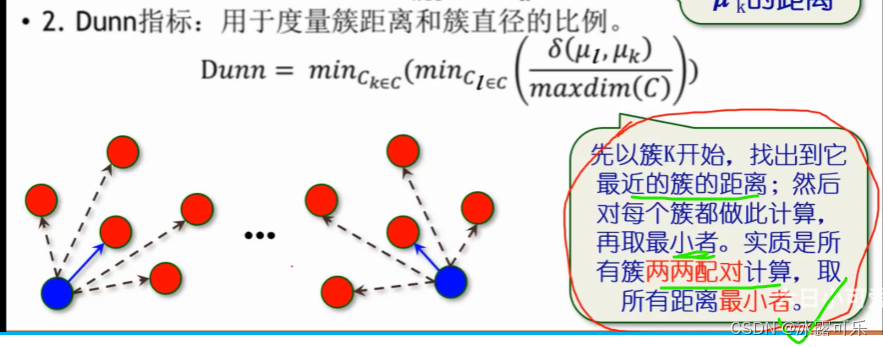
数据挖掘:关联规则,异常检测,挖掘的标准流程,评估指标,误差,聚类,决策树
数据挖掘:关联规则
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤其sql要…
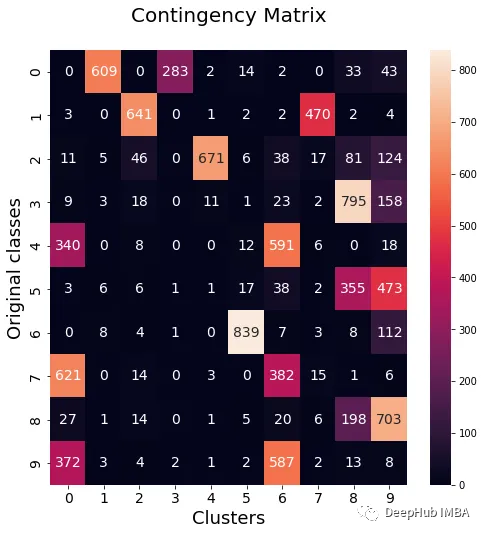
【matlab】KMeans KMeans++实现手写数字聚类
目录
matlab代码kmeans
matlab代码kmeans MNIST DATABASE下载网址: http://yann.lecun.com/exdb/mnist/ 聚类
将物理或抽象对象的集合分成由类似特征组成的多个类的过程称为聚类(clustering)。
对于给定N个n维向量x1,…,xN∈Rn,聚类的目标…
无监督学习的集成方法:相似性矩阵的聚类
在机器学习中,术语Ensemble指的是并行组合多个模型,这个想法是利用群体的智慧,在给出的最终答案上形成更好的共识。
这种类型的方法已经在监督学习领域得到了广泛的研究和应用,特别是在分类问题上,像RandomForest这样…
这款开源神器,让聚类算法从此变得简单易用
Scikit-Learn 以其提供的多个经过验证的聚类算法而著称。尽管如此,其中大多数都是参数化的,并需要设置集群的数量,这是聚类中最大的挑战之一。
通常,使用迭代方法来决定数据的最佳聚类数量,这意味着你需要多次进行聚类…

多视图聚类的论文阅读(一)
当聚类的方式使用的是某一类预定义好的相似性度量时, 会出现如下情况:
数据聚类方面取得了成功,但它们通常依赖于预定义的相似性度量,而这些度量受原始方法的影响:当输入维数相对较高时,往往是无效的。
1. Deep Mult…
多视图聚类论文阅读(二)
Deep multi-view semi-supervised clustering with sample pairwise constraints
Neuro Compucting
基于样本对约束的深度多视图半监督聚类
1.1 聚类的相关工作
典型相关分析(CCA)[13]寻求两个投影,将两个视图映射到一个低维公共子空间,其中两个视图…
基于像素特征的kmeas聚类的图像分割方案
kmeans聚类代码
将像素进行聚类,得到每个像素的聚类标签,默认聚类簇数为3 def seg_kmeans(img,clusters3):img_flatimg.reshape((-1,3))# print(img_flat.shape)img_flatnp.float32(img_flat)criteria(cv.TERM_CRITERIA_MAX_ITERcv.TERM_CRITERIA_EPS,2…

机器学习实验六:聚类
系列文章目录
机器学习实验一:线性回归机器学习实验二:决策树模型机器学习实验三:支持向量机模型机器学习实验四:贝叶斯分类器机器学习实验五:集成学习机器学习实验六:聚类 文章目录 系列文章目录一、实验…

维基百科文章爬虫和聚类【二】:KMeans
维基百科是丰富的信息和知识来源。它可以方便地构建为带有类别和其他文章链接的文章,还形成了相关文档的网络。我的 NLP 项目下载、处理和应用维基百科文章上的机器学习算法。 一、说明 在我的上一篇文章中,展示了该项目的轮廓,并奠定了其基础…
# 聚类系列(一)——什么是聚类?
目前在做聚类方面的科研工作, 看了很多相关的论文, 也做了一些工作, 于是想出个聚类系列记录一下, 主要包括聚类的概念和相关定义、现有常用聚类算法、聚类相似性度量指标、聚类评价指标、 聚类的应用场景以及共享一些聚类的开源代码 下面正式进入该系列的第一个部分ÿ…
![[点云分割] 条件欧氏聚类分割](https://img-blog.csdnimg.cn/e9ca0fe1d5824918a7b508ee5621ccc4.png)
[点云分割] 条件欧氏聚类分割
介绍
条件欧氏聚类分割是一种基于欧氏距离和条件限制的点云分割方法。它通过计算点云中点与点之间的欧氏距离,并结合一定的条件限制来将点云分割成不同的区域或聚类。
在条件欧氏聚类分割中,通常会定义以下两个条件来判断两个点是否属于同一个聚类&…
6个常用的聚类评价指标
评估聚类结果的有效性,即聚类评估或验证,对于聚类应用程序的成功至关重要。它可以确保聚类算法在数据中识别出有意义的聚类,还可以用来确定哪种聚类算法最适合特定的数据集和任务,并调优这些算法的超参数(例如k-means中的聚类数量…
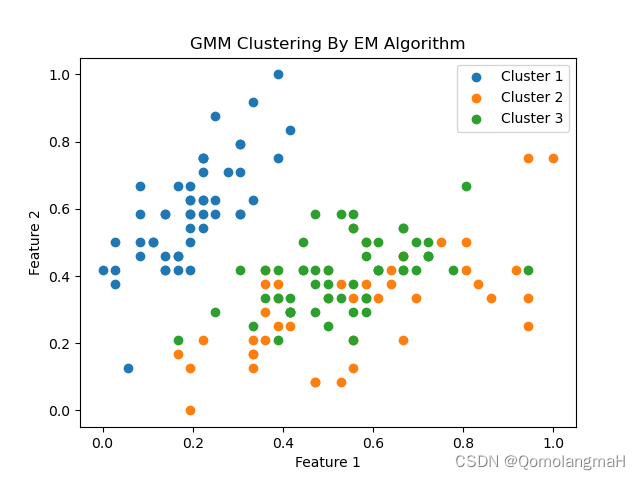
【机器学习】聚类(三):原型聚类:高斯混合聚类
文章目录 一、实验介绍1. 算法流程2. 算法解释3. 算法特点4. 应用场景5. 注意事项 二、实验环境1. 配置虚拟环境2. 库版本介绍 三、实验内容0. 导入必要的库1. 全局调试变量2. 调试函数3. 高斯密度函数(phi)4. E步(getExpectation)…

【机器学习 | 聚类】关于聚类最全评价方法大全,确定不收藏?
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…
基于KMeans聚类算法的网络流量分类预测(毕业论文)
点我完整下载:基于KMeans聚类算法的网络流量分类预测.docx 基于KMeans聚类算法的网络流量分类预测 "Network Traffic Classification Prediction based on KMeans Clustering Algorithm" 目录 目录 2 摘要 3 关键词 4 第一章 引言 4 1.1 研究背景 4 1.2 研…
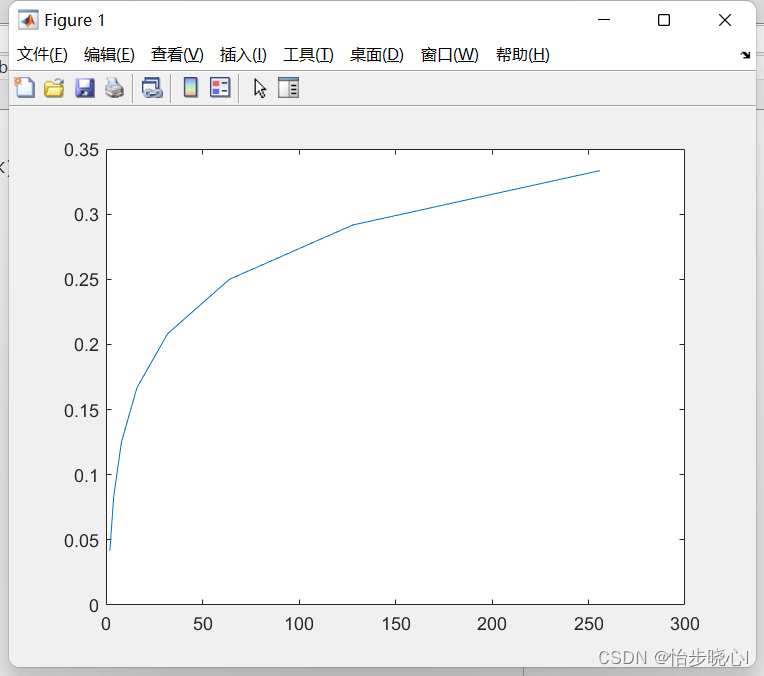
03、K-means聚类实现步骤与基于K-means聚类的图像压缩(2)
03、K-means聚类实现步骤与基于K-means聚类的图像压缩(2)
工程下载:K-means聚类实现步骤与基于K-means聚类的图像压缩
其他: 03、K-means聚类实现步骤与基于K-means聚类的图像压缩(1) 03、K-means聚类实现…
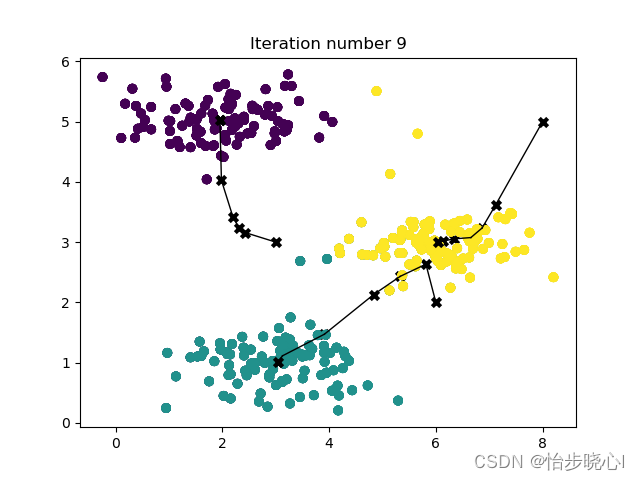
03、K-means聚类实现步骤与基于K-means聚类的图像压缩(1)
03、K-means聚类实现步骤与基于K-means聚类的图像压缩(1)
03、K-means聚类实现步骤与基于K-means聚类的图像压缩(1) 03、K-means聚类实现步骤与基于K-means聚类的图像压缩(2)
开始学习机器学习啦…

模糊C均值(Fuzzy C-means,FCM)聚类的python程序代码的逐行解释,看完你也会写!!
文章目录 前言一、本文的原始代码二、代码的逐行详细解释总结 前言
接上一篇博客,详细解释FCM聚类的程序代码!!
一、本文的原始代码
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
import skfuzzy as…
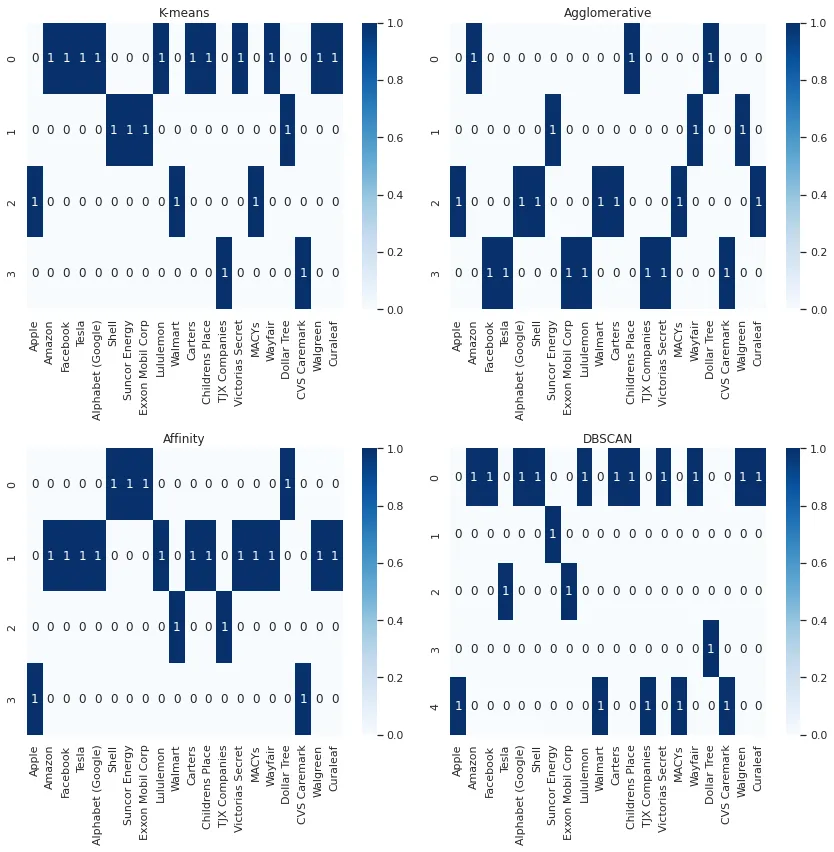
基于相关性的四种机器学习聚类方法
在这篇文章中,基于20家公司的股票价格时间序列数据。根据股票价格之间的相关性,看一下对这些公司进行分类的四种不同方式。 苹果(AAPL),亚马逊(AMZN),Facebook(META&…
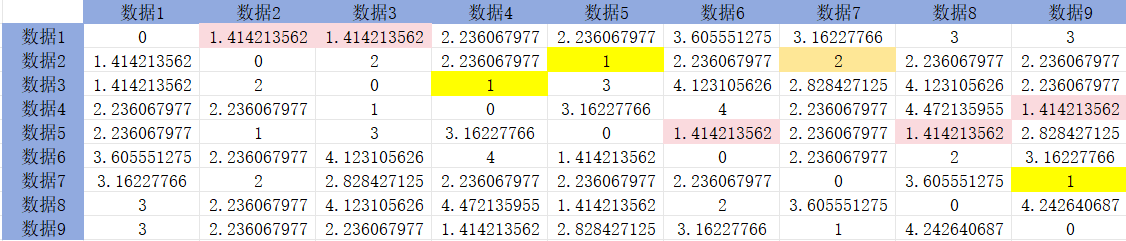

【人工智能Ⅰ】实验7:K-means聚类实验
实验7 K-means聚类实验
一、实验目的
学习K-means算法基本原理,实现Iris数据聚类。 二、实验内容
应用K-means算法对iris数据集进行聚类。 三、实验结果及分析
0:输出数据集的基本信息
参考代码在main函数中首先打印了数据、特征名字、目标值、目标…

matlab kmeans图像聚类例子
%*******************************读取图像数据********************************
clear
close all
clcx imread(fig.png); %读入一幅图像,得到图像数据x
whos x % 查看矩阵x的大小和类型
y double(x(:)); %将图像数据x按列拉长成一个长向量%***********…

大数据机器学习深度解读DBSCAN聚类算法:技术与实战全解析
大数据机器学习深度解读DBSCAN聚类算法:技术与实战全解析
一、简介
在机器学习的众多子领域中,聚类算法一直占据着不可忽视的地位。它们无需预先标注的数据,就能将数据集分组,组内元素相似度高,组间差异大。这种无监…

【人工智能Ⅰ】实验8:DBSCAN聚类实验
实验8 DBSCAN聚类实验
一、实验目的
学习DBSCAN算法基本原理,掌握算法针对不同形式数据如何进行模型输入,并结合可视化工具对最终聚类结果开展分析。 二、实验内容
1:使用DBSCAN算法对iris数据集进行聚类算法应用。
2:使用DBS…
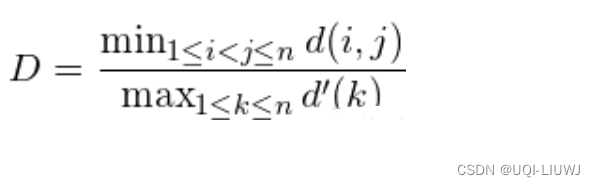
聚类笔记:聚类算法评估指标
1 内部评估方法
当一个聚类结果是基于数据聚类自身进行评估的,这一类叫做内部评估方法。如果某个聚类算法聚类的结果是类间相似性低,类内相似性高,那么内部评估方法会给予较高的分数评价。不过内部评价方法的缺点是: 这些评估方法…

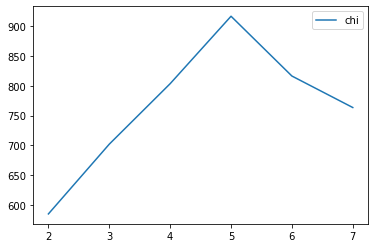
机器学习 | 聚类Clustering 算法
物以类聚人以群分。 什么是聚类呢? 1、核心思想和原理 聚类的目的 同簇高相似度 不同簇高相异度 同类尽量相聚 不同类尽量分离 聚类和分类的区别 分类 classification 监督学习 训练获得分类器 预测未知数据 聚类 clustering 无监督学习,不关心类别标签 …
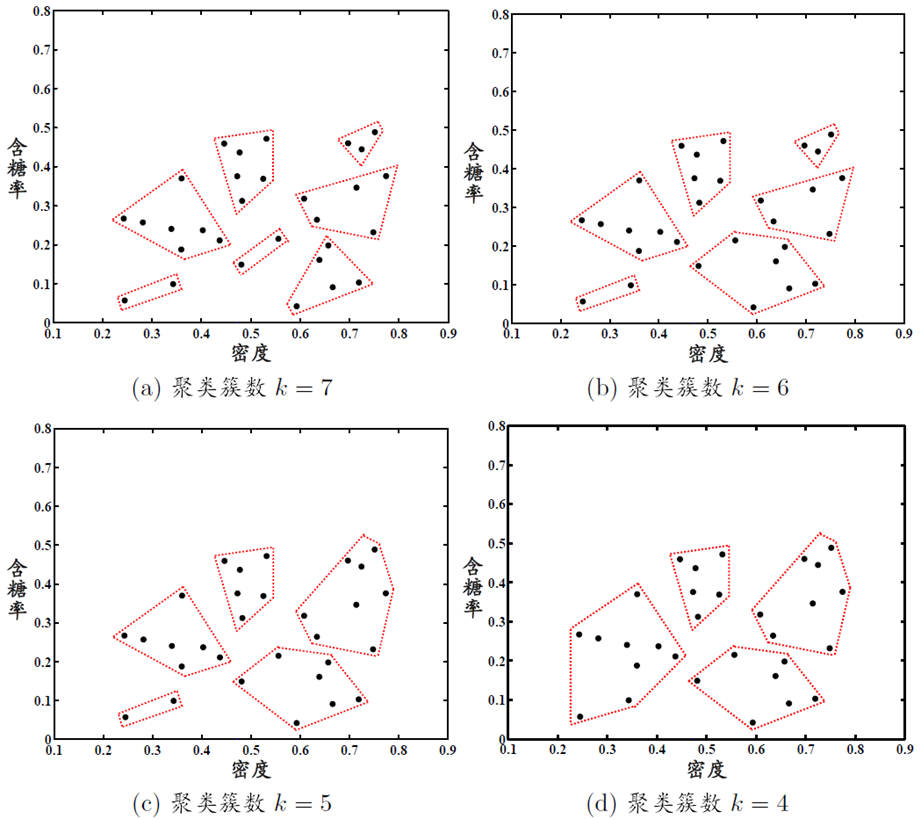
机器学习---聚类(原型聚类、密度聚类、层次聚类)
1. 原型聚类
原型聚类也称为“基于原型的聚类” (prototype-based clustering),此类算法假设聚类结构能通过一
组原型刻画。算法过程:通常情况下,算法先对原型进行初始化,再对原型进行迭代更新求解。著
名的原型聚类算法&#…

利用R语言heatmap.2函数进行聚类并画热图
数据聚类然后展示聚类热图是生物信息中组学数据分析的常用方法,在R语言中有很多函数可以实现,譬如heatmap,kmeans等,除此外还有一个用得比较多的就是heatmap.2。最近在网上看到一个笔记文章关于《一步一步学heatmap.2函数》,在此与…

聚类:聚类的介绍及k-means算法
聚类:聚类的介绍及k-means算法
什么是聚类
聚类就是在输入为多个数据时,将“相似”的数据分为一组的操作。1 个组就叫作 1 个 “簇”。下面的示例中每个点都代表1 个数据,在平面上位置较为相近、被圈起来的点就代表一 类相似的数据。也就是…
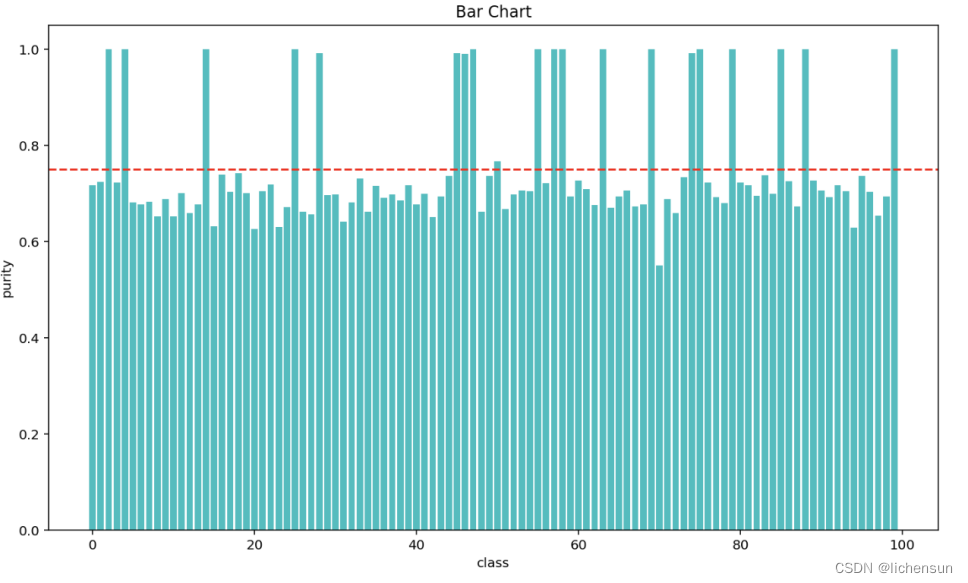
2023 年中国高校大数据挑战赛赛题B DNA 存储中的序列聚类与比对-解析与参考代码
题目背景:目前往往需要对测序后的序列进行聚类与比对。其中聚类指的是将测序序列聚类以判断原始序列有多少条,聚类后相同类的序列定义为一个簇。比对则是指在聚类基础上对一个簇内的序列进行比对进而输出一条最有 可能的正确序列。通过聚类与比对将会极大…
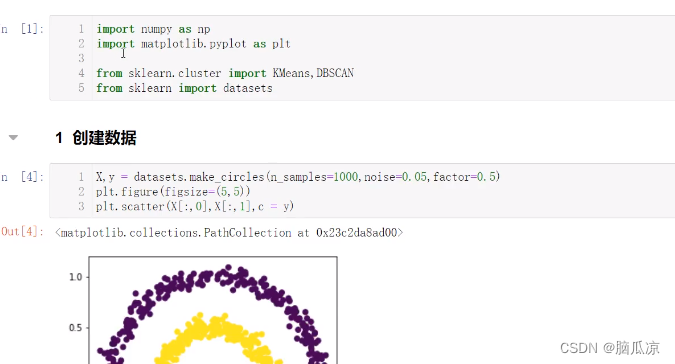
人工智能_机器学习087_DBSCAN聚类案例_聚类数据创建---人工智能工作笔记0127
之前我们把DBSCAN的原理以及参数都理解了,现在我们看如何使用
首先我们导包
import numpy as np 导入数学计算包
import matplotlib.pyplot as plt 导入画图包
from sklearn.cluster import KMeans,DBSCAN 导入算法
from sklearn import datasets 导入数据集包 X,y = data…
四种无监督聚类算法说明
目录 一、K-Means无监督学习(K-Means)的认识-CSDN博客 二、Mini-Batch K-Means -- Centroid models 三、AffinityPropagation (Hierarchical) -- Connectivity models
四、Mean Shift -- Centroid models 无监督聚类是一种机器学习技术&…
模糊聚类算法——模糊C均值聚类及matlab实现
模糊C均值聚类算法(Fuzzy C-Means, FCM)。
1. 算法概述
模糊C均值聚类算法是一种经典的模糊聚类算法,用于无监督学习中的数据聚类问题。它通过为每个数据点分配模糊隶属度,将数据点划分到不同的聚类中心。与传统的硬聚类算法不同…
西瓜书学习笔记——原型聚类(公式推导+举例应用)
文章目录 k均值算法算法介绍实验分析 学习向量量化(LVQ)算法介绍实验分析 高斯混合聚类算法介绍实验分析 总结 k均值算法
算法介绍
给定样本集 D { x 1 , x 2 , . . . , x m } D\{x_1,x_2,...,x_m\} D{x1,x2,...,xm},k均值算法针对聚…

4、K- 均值聚类(Clustering With K-Means)
用聚类标签解开复杂的空间关系。 文章目录 1、简介2、聚类标签作为特征3、k-均值聚类4、示例 - 加利福尼亚住房1、简介
这节课和下一节课将使用所谓的无监督学习算法。无监督算法不使用目标;相反,它们的目的是学习数据的某些属性,以某种方式表示特征的结构。在预测的特征工…
【PostGIS】POSTGIS实现聚类统计提取外轮廓
项目需求根据某些条件进行聚类统计,然后返回聚类的外轮廓,这里主要用到POSTGIS的两个算法,一个是聚类统计功能,一个是提取外轮廓的功能。
1. 聚类统计
Postgis主要实现并提供了四种聚类方法,前两个为窗口函数&#x…
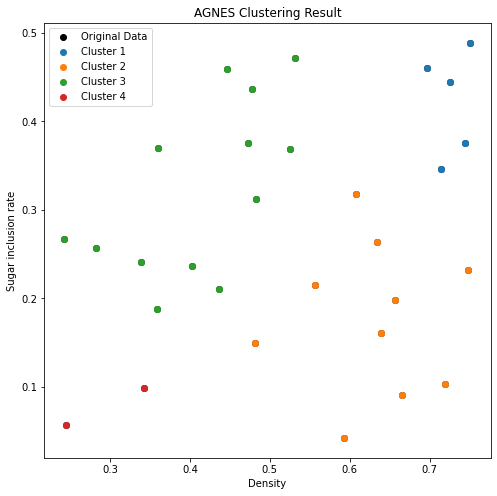
西瓜书学习笔记——层次聚类(公式推导+举例应用)
文章目录 算法介绍实验分析 算法介绍
层次聚类是一种将数据集划分为层次结构的聚类方法。它主要有两种策略:自底向上和自顶向下。 其中AGNES算法是一种自底向上聚类算法,用于将数据集划分为层次结构的聚类。算法的基本思想是从每个数据点开始࿰…

【脑电信号处理与特征提取】P7-贾会宾:基于EEG/MEG信号的大尺度脑功能网络分析
基于EEG/MEG信号的大尺度脑功能网络分析 Q: 什么是基于EEG/MEG信号的大尺度脑功能网络分析? A: 基于脑电图(EEG)或脑磁图(MEG)信号的大尺度脑功能网络分析是一种研究大脑活动的方法,旨在探索脑区之间的功能…
【非监督学习 | 聚类】聚类算法类别大全 距离度量单位大全
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…
机器学习本科课程 实验6 聚类实验
第一题:使用sklearn的DBSCAN和AgglomerativeClustering完成聚类
实验内容:
使用sklearn的DBSCAN和AgglomerativeClustering在两个数据集上完成聚类任务对聚类结果可视化对比外部指标FMI和NMI
1. 导入模块
import numpy as np
import matplotlib.pypl…
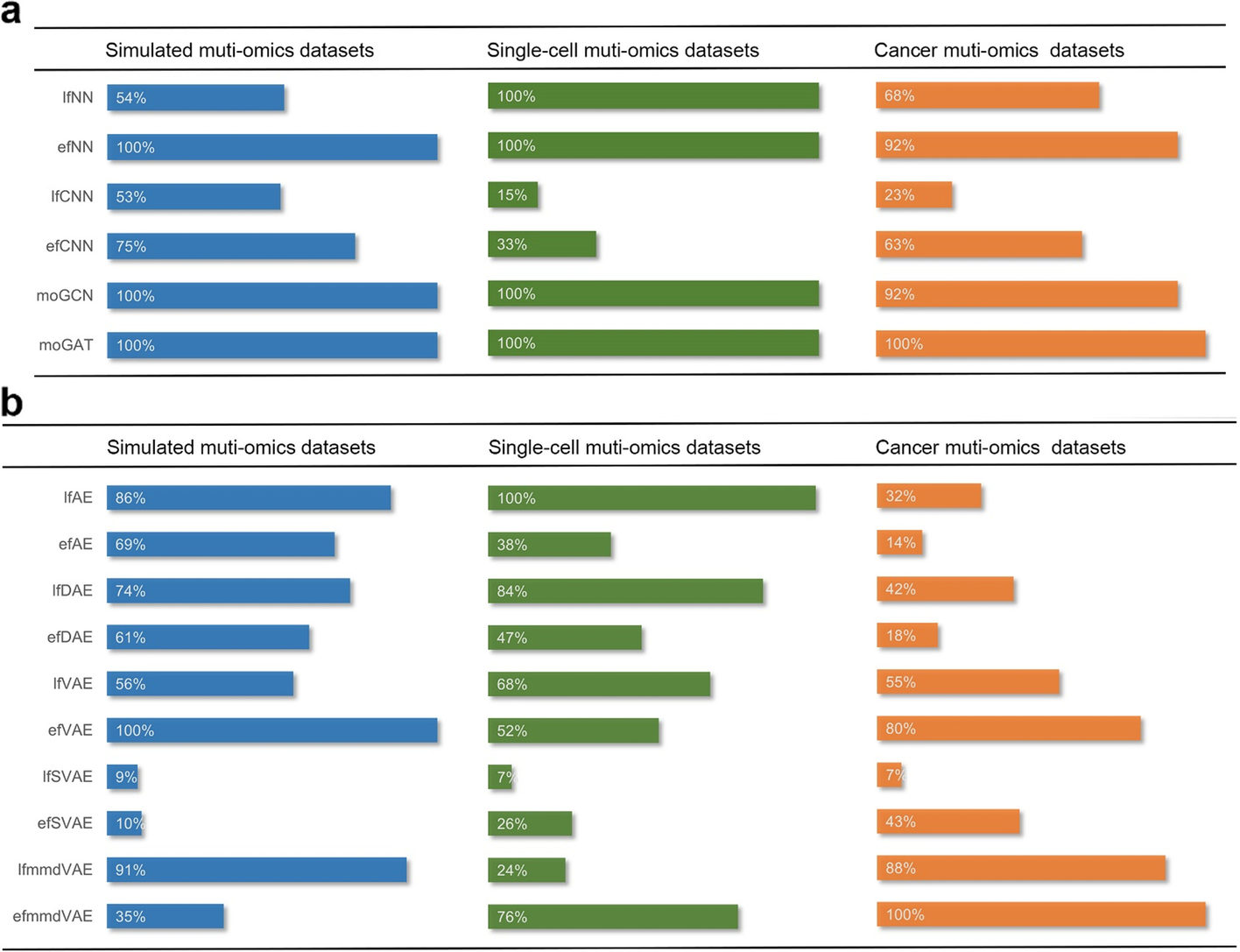
综述 2022-Genome Biology:“AI+癌症multi-omics”融合方法benchmark
Leng, Dongjin, et al. "A benchmark study of deep learning-based multi-omics data fusion methods for cancer." Genome biology 23.1 (2022): 1-32.
被引次数:34作者单位 红色高亮表示写论文中可以借鉴的地方 一、方法和数据集
1. 3个数据集&…
维基百科文章爬虫和聚类:高级聚类和可视化
一、说明 维基百科是丰富的信息和知识来源。它可以方便地构建为带有类别和其他文章链接的文章,还形成了相关文档的网络。我的 NLP 项目下载、处理和应用维基百科文章上的机器学习算法。
在我的上一篇文章中,KMeans 聚类应用于一组大约 300 篇维基百科文…

DBSCAN聚类算法学习笔记
DBSCAN聚类算法学习笔记
一些概念名词 MinPts:聚类在一起的点的最小数目,超过这一阈值才算是一个族群 核心点:邻域内数据点超过MinPts的点 边界点:落在核心点邻域内的点称为边界点 噪声点:既不是核心点也不是边界点的…

【数学建模】《实战数学建模:例题与讲解》第十一讲-因子分析、聚类与主成分(含Matlab代码)
【数学建模】《实战数学建模:例题与讲解》第十一讲-因子分析、聚类与主成分(含Matlab代码) 基本概念聚类分析Q型聚类分析R型聚类分析 主成分分析因子分析 习题10.11. 题目要求2.解题过程3.程序4.结果 习题10.21. 题目要求2.解题过程3.程序4.结…

社交网络分析3:社交网络隐私攻击、保护的基本概念和方法 + 去匿名化技术 + 推理攻击技术 + k-匿名 + 基于聚类的隐私保护算法
社交网络分析3:社交网络隐私攻击、保护的基本概念和方法 去匿名化技术 推理攻击技术 k-匿名 基于聚类的隐私保护算法 写在最前面社交网络隐私泄露用户数据暴露的途径复杂行为的隐私风险技术发展带来的隐私挑战经济利益与数据售卖防范措施 社交网络 用户数据隐私…

传统机器学习 基于TF_IDF的文本聚类实现
简介
使用sklearn基于TF_IDF算法,实现把文本变成向量。再使用sklearn的kmeans聚类算法进行文本聚类。
个人观点:这是比较古老的技术了,文本转向量的效果不如如今的 text2vec 文本转向量好。 而且sklearn 不支持GPU加速,处理大量…
利用 OpenAI API 进行文本聚类和标记
每日推荐一篇专注于解决实际问题的外文,精准翻译并深入解读其要点,助力读者培养实际问题解决和代码动手的能力。
欢迎关注公众号 原文标题:Text Clustering and Labeling Utilizing OpenAI API
原文地址:https://medium.com/kbd…
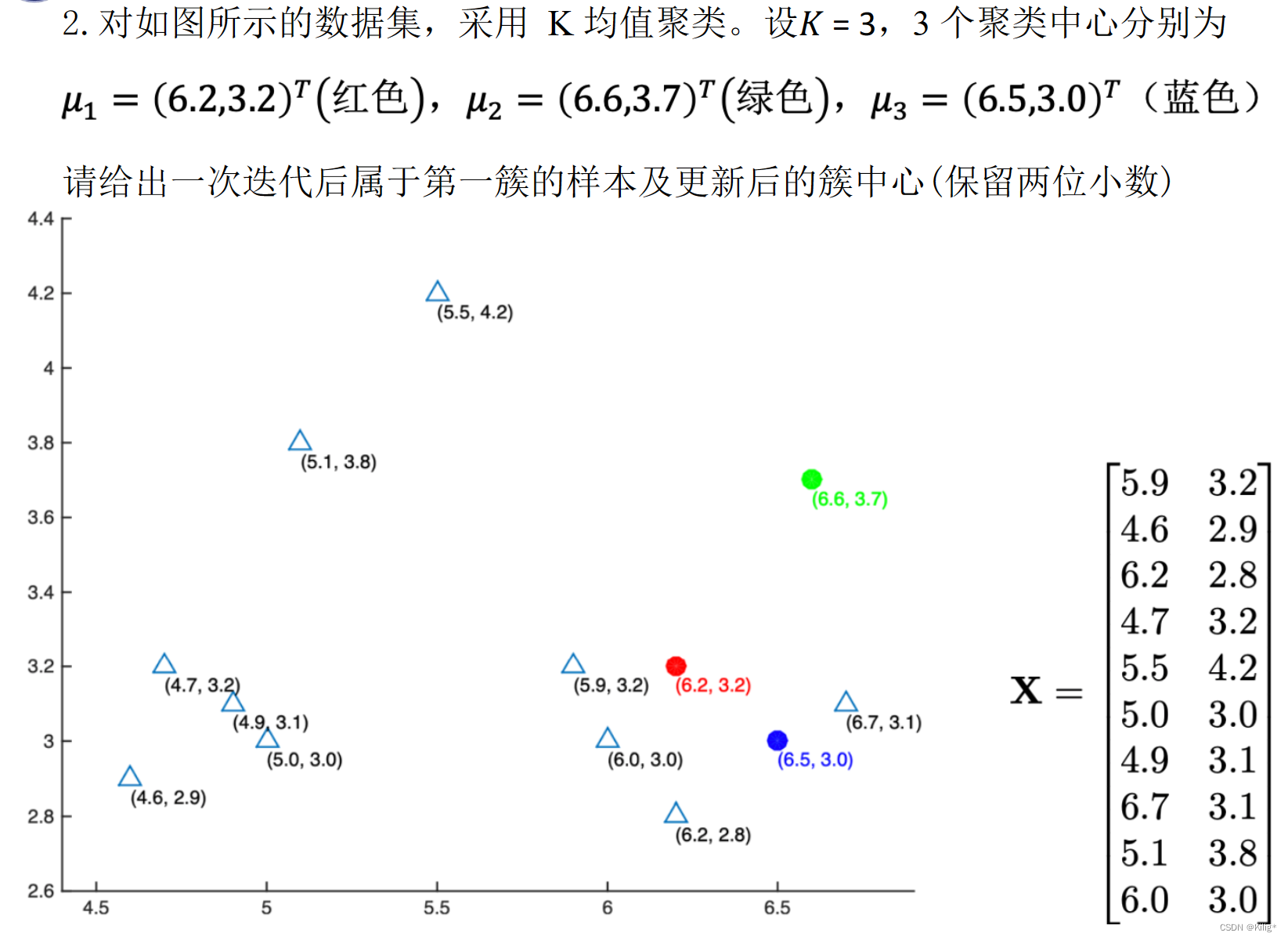
模式识别与机器学习-无监督学习-聚类
无监督学习-聚类 监督学习&无监督学习K-meansK-means聚类的优点:K-means的局限性:解决方案: 高斯混合模型(Gaussian Mixture Models,GMM)多维高斯分布的概率密度函数:高斯混合模型ÿ…

【2023年中国高校大数据挑战赛 】赛题 B DNA 存储中的序列聚类与比对 Python实现
【2023年中国高校大数据挑战赛 】赛题 B DNA 存储中的序列聚类与比对 Python实现
1 题目
赛题 B DNA 存储中的序列聚类与比对
近年来,随着新互联网设备的大量涌入和对其服务需求的指数级增长,越来越多的数据信息被产生与收集。预计到 2021 年…

【完整思路】2023 年中国高校大数据挑战赛 赛题 B DNA 存储中的序列聚类与比对
2023 年中国高校大数据挑战赛 赛题 B DNA 存储中的序列聚类与比对 任务 1.错误率和拷贝数分析:分析“train_reads.txt”和“train_reference.txt”数据集中的错误率(插入、删除、替换、链断裂)和序列拷贝数。 2.聚类模型开发:开发…
数据挖掘 K-Means聚类
未格式化之前的代码:
import pandas as pd#数据处理
from matplotlib import pyplot as plt#绘图
from sklearn.preprocessing import MinMaxScaler#归一化
from sklearn.cluster import KMeans#聚类
import os#处理文件os.environ["OMP_NUM_THREADS"] …
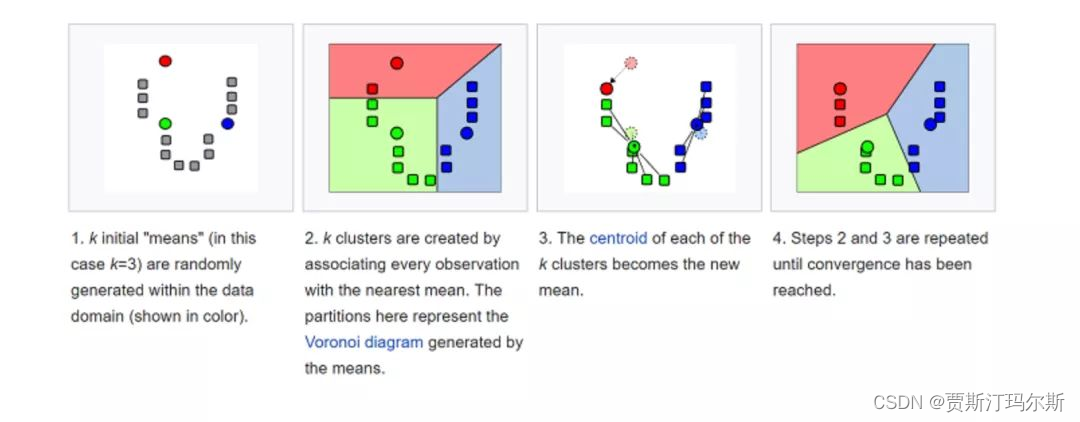
机器学习之K-means聚类
概念
K-means是一种常用的机器学习算法,用于聚类分析。聚类是一种无监督学习方法,它试图将数据集中的样本划分为具有相似特征的组(簇)。K-means算法的目标是将数据集划分为K个簇,其中每个样本属于与其最近的簇中心。
以下是K-means算法的基本步骤: 选择簇的数量(K值)…
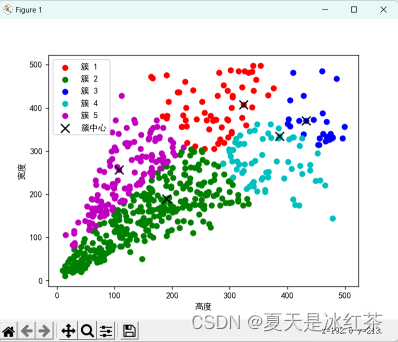
K-means 聚类算法分析
算法简述
K-means 算法原理
我们假定给定数据样本 X ,包含了 n 个对象 ,其中每一个对象都具有 m 个维度的属性。而 K-means 算法的目标就是将 n 个对象依据对象间的相似性聚集到指定的 k 个类簇中,每个对象属于且仅属于一个其到类簇中心距离…

RIPGeo代码理解(五)utils.py( 辅助函数)第二部分
代码链接:RIPGeo代码实现
├── lib # 包含模型(model)实现文件 │ |── layers.py # 注意力机制的代码。 │ |── model.py # TrustGeo的核心源代码。 │ |── sublayers.py # layer.py的支持文件。 │ |── utils.p…
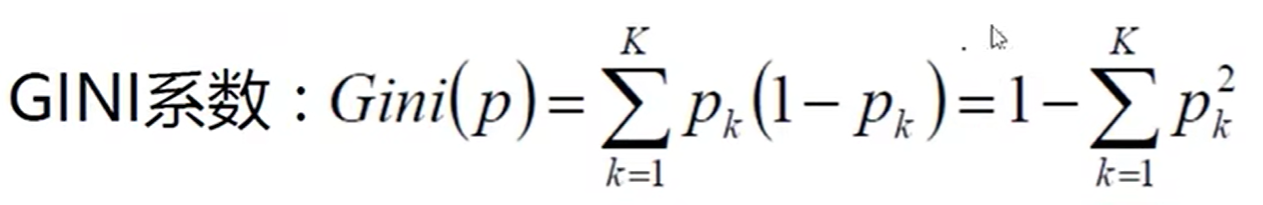
机器学习之聚类算法、随机森林
文章目录 随机森林决策树基础特征值问题? 聚类算法 随机森林
决策树
基础
概念:从根节点一步步走到叶子节点(决策); 组成:根节点第一个选择的节点;叶子节点最终的决策结果;非叶子…

Paper Digest|基于在线聚类的自监督自蒸馏序列推荐模型
论文标题: Leave No One Behind: Online Self-Supervised Self-Distillation for Sequential Recommendation
作者姓名: 韦绍玮、吴郑伟、李欣、吴沁桐、张志强、周俊、顾立宏、顾进杰
组织单位: 蚂蚁集团
录用会议: WWW 2024 …
基于kmeans的聚类微博舆情分析系统
第一章绪论
1.1研究背景
如今在我们的生活与生产的每个角落都可以见到数据与信息的身影。自从上十世纪八十年代的中后期开始,我们使用的互联网技术已经开始快速发展,近些年来云计算、大数据和物联网等与互联网有相领域的发展让互联网技术达到了史无前例…
Python可视化概率统计和聚类学习分析生物指纹
🎯要点
🎯使用Jupyter Notebook执行Dash 应用,确定Dash输入输出,设计回调函数,Dash应用中包含函数。🎯使用Plotly绘图工具:配置图对象选项,将图转换为HTML、图像。使用数据集绘图…

聚类算法的先验基础知识
聚类算法的先验基础知识 1. 瑞利商2. 谱定理3. 联合概率4. 条件概率分布5. 边缘分布6. 贝叶斯定理7. 有向图8. 拉格朗日乘子定理 下一篇将介绍整理各种聚类算法,包括k-means,GMM(Guassian Mixture Models, 高斯混合),EM(Expectation Maximiza…

【深度学习】一维数组的聚类
在学习聚类算法的过程中,学习到的聚类算法大部分都是针对n维的,针对一维数据的聚类方式较少,今天就来学习下如何给一维的数据进行聚类。
方案一:采用K-Means对一维数据聚类
Python代码如下: from sklearn.cluster im…
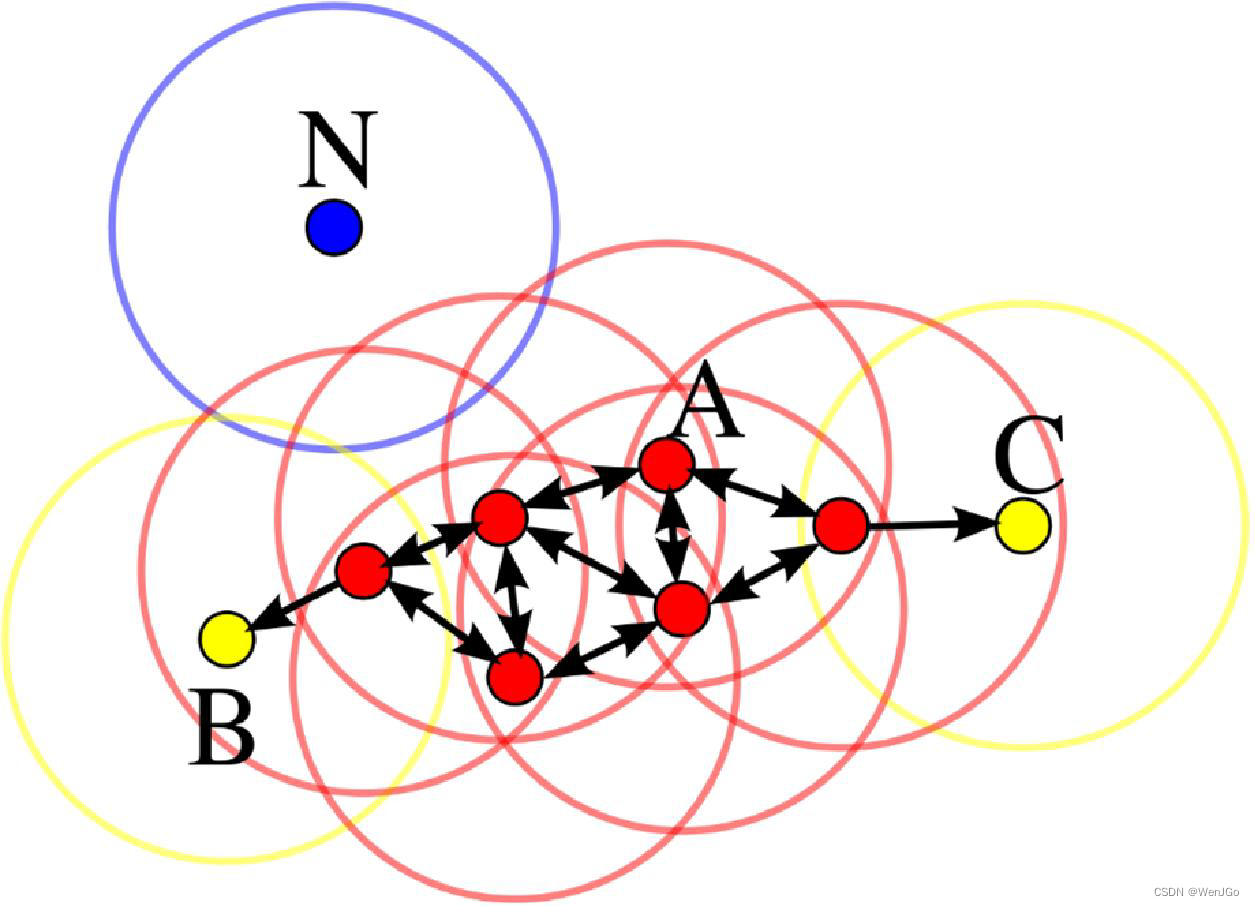
数模学习day10-聚类模型
说明,本文部分图片和内容源于数学建模交流公众号
目录
K-means聚类算法
K-means聚类的算法流程:
图解
算法流程图
评价
K-means算法
基本原则
算法过程
Spss软件操作
K-means算法的疑惑
系统(层次)聚类
算法流程
Sp…
VCG 基于连通性网格面片聚类
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 这里的思路其实与点云的欧式聚类非常类似,区别在于点云的欧式聚类是通过搜索半径对点云进行聚类,至于基于连通性网格面片聚类则是通过面片的邻近关系对面片进行聚类,大致的过程与欧式聚类是相同的: 首先,需要指…

CGAL 网格连通聚类
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 这里的思路其实与点云的欧式聚类非常类似,区别在于点云的欧式聚类是通过搜索半径对点云进行聚类,至于基于连通性网格面片聚类则是通过面片的邻近关系对面片进行聚类,大致的过程与欧式聚类是相同的: 首先,需要指…

Scikit-Learn K均值聚类
Scikit-Learn K均值聚类 1、K均值聚类1.1、K均值聚类及原理1.2、K均值聚类的优缺点1.3、聚类与分类的区别2、Scikit-Learn K均值聚类2.1、Scikit-Learn K均值聚类API2.2、K均值聚类初体验2.3、K均值聚类案例1、K均值聚类 K-均值(K-Means)是一种聚类算法,属于无监督学习。K-M…

电商-广告投放效果分析(KMeans聚类、数据分析-pyhton数据分析
电商-广告投放效果分析(KMeans聚类、数据分析) 文章目录 电商-广告投放效果分析(KMeans聚类、数据分析)项目介绍数据数据维度概况数据13个维度介绍 导入库,加载数据数据审查相关性分析数据处理建立模型聚类结果特征分析…
机器学习概念:监督学习、无监督学习、回归、聚类
监督学习(Supervised Learning): 在监督学习中,训练数据包含了输入特征,和相应的标签(目标值)。监督学习的目标是学习一个从输入到输出的映射,使得模型能够根据输入预测相应的输出。…
基于BERTopic模型的中文文本主题聚类及可视化
文章目录 BERTopic简介模型加载地址文本加载数据处理BERTopic模型构建模型结果展示主题可视化总结BERTopic简介
BERTopic论文地址:BERTopic: Neural topic modeling with a class-based TF-IDF procedure
BERTopic是一种结合了预训练模型BERT和主题建模的强大工具。它允许我…
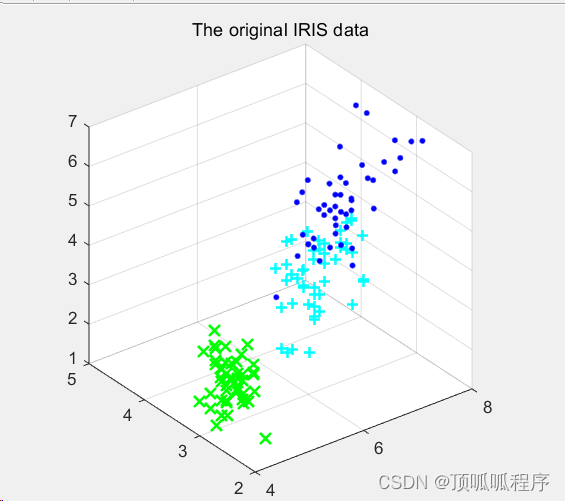
182基于matlab的半监督极限学习机进行聚类
基于matlab的半监督极限学习机进行聚类,基于流形正则化将 ELM 扩展用于半监督,三聚类结果可视化输出。程序已调通,可直接运行。 182matlab ELM 半监督学习 聚类 模式识别 (xiaohongshu.com)

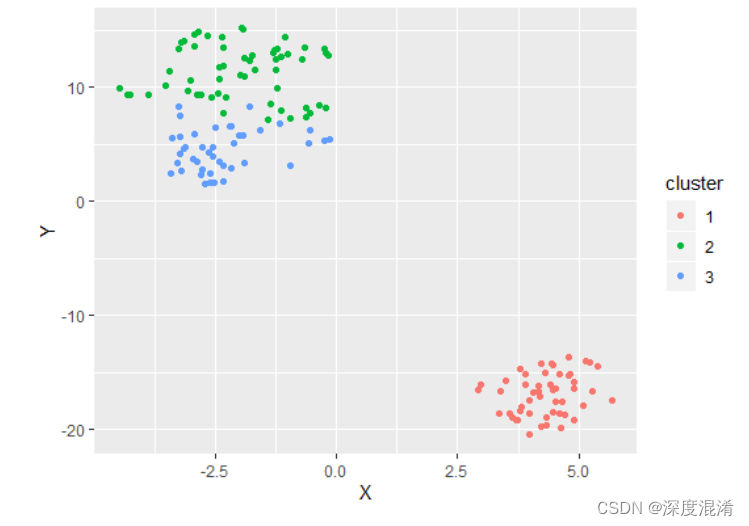
C#,无监督的K-Medoid聚类算法(K-Medoid Algorithm)与源代码
1 K-Medoid算法
K-Medoid(也称为围绕Medoid的划分)算法是由Kaufman和Rousseeuw于1987年提出的。中间点可以定义为簇中的点,其与簇中所有其他点的相似度最小。 K-medoids聚类是一种无监督的聚类算法,它对未标记数据中的对象进行聚…
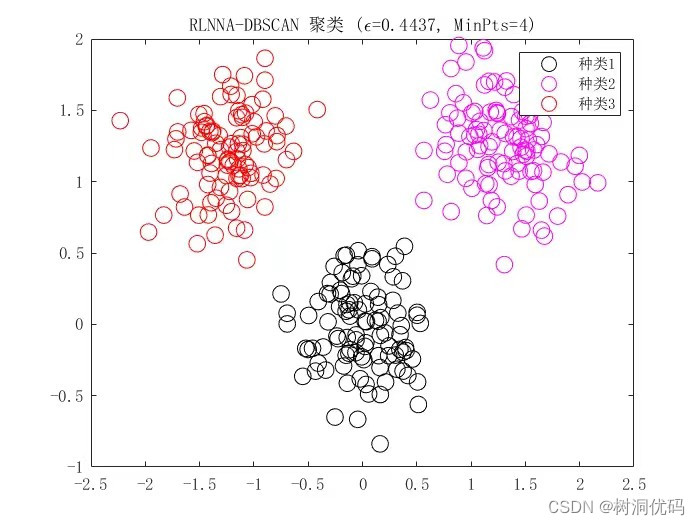
RLNNA-DBSCAN聚类
RLNNA-DBSCAN聚类
RLNNA算法(基于强化学习的神经网络优化算法)是一种性能较佳的优化算法。DBSCAN聚类算法(密度聚类算法)是一种基于密度的聚类算法,其主要思想是通过寻找样本点周围的密度可达关系来聚类数据。 使用RL…
人工智能|机器学习——Canopy聚类算法(基于密度)
1.简介 Canopy聚类算法是一个将对象分组到类的简单、快速、精确地方法。每个对象用多维特征空间里的一个点来表示。这个算法使用一个快速近似距离度量和两个距离阈值T1 > T2 处理。 Canopy聚类很少单独使用, 一般是作为k-means前不知道要指定k为何值的时候&#…
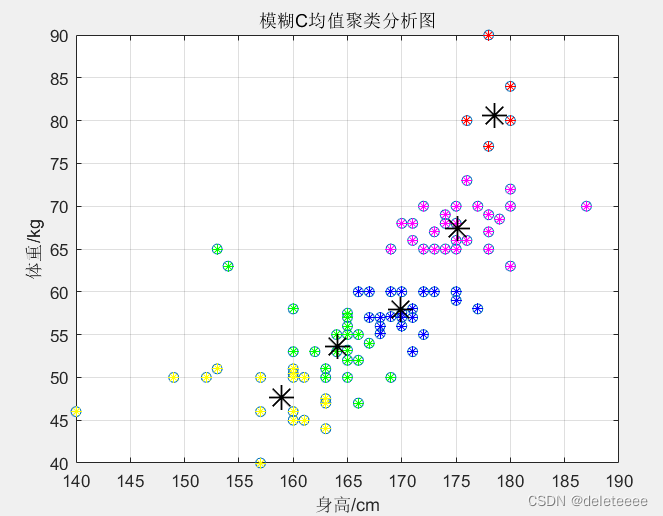
matlab 实现模糊C均值聚类
1. 原理
模糊c均值算法步骤:
1. 设定聚类数目c和加权指数b:
2. 初始化各个聚类中心m 3. 重复下面的运算,直到各个样本的隶属度值稳定:用当前的聚类中心根据下式计算隶属度函数: 用当前的隶属度函数按下式更新计算各…
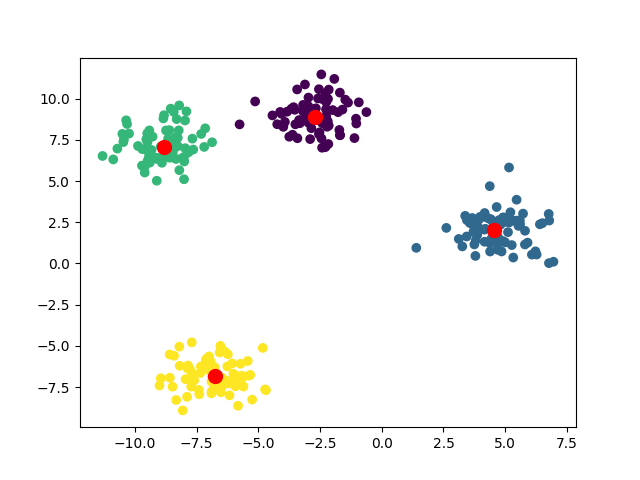
机器学习系列 - Mean Shift聚类
文章目录 前言一、原理前置知识点Mean Shift计算步骤 二、应用举例-图像分割三、聚类实战-简单实例bandwidth1bandwidth2总结 前言
Mean Shift(均值漂移)是基于密度的非参数聚类算法,其算法思想是假设不同簇类的数据集符合不同的概率密度分布…
4.3 DBSCAN聚类算法(自己写的函数python)
代码如下:
import numpy as np
import cv2
import time
import os#聚类算法
def cluster(points, radius100,nums250):"""points: pointcloudradius: max cluster range"""print("................", len(points))items …
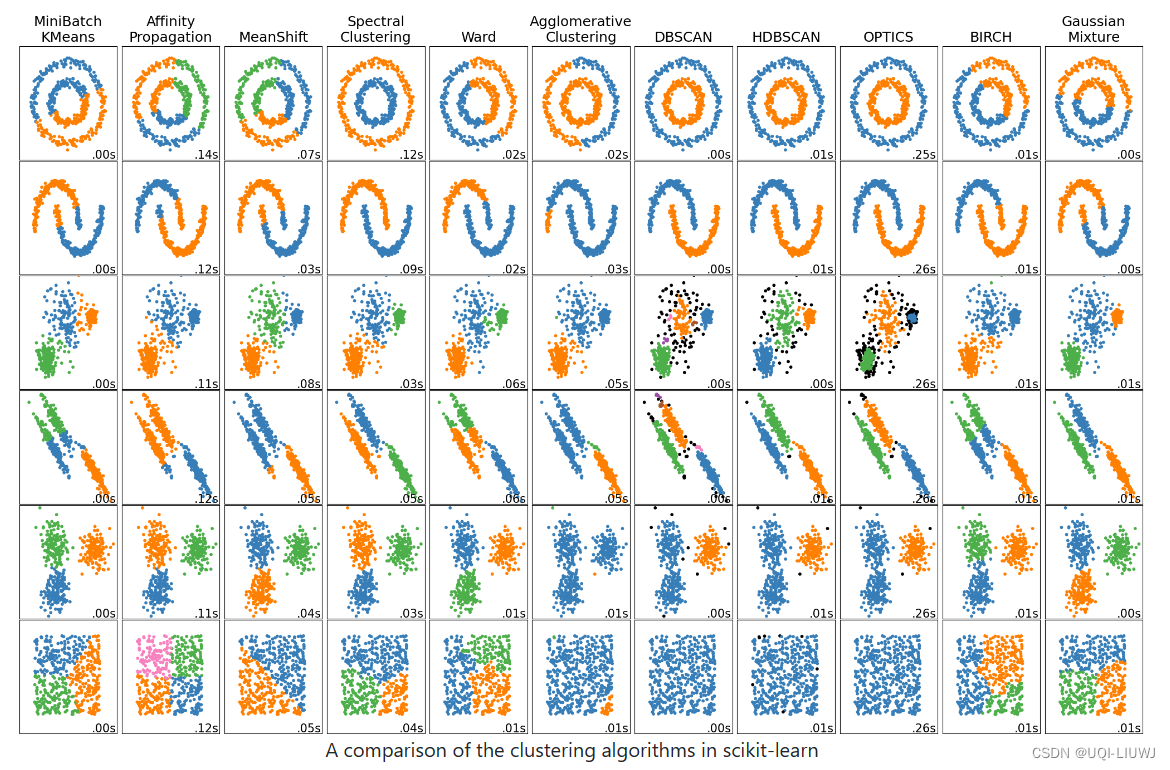
sklearn 笔记:聚类
1 sklearn各方法比较 方法名称参数使用场景K-means簇的数量 非常大的样本数 中等簇数 簇大小需要均匀 Affinity Propagation 阻尼系数 样本偏好 样本数不能多 簇大小不均 MeanShift带宽 样本数不能多 簇大小均匀 谱聚类簇的数量 中等样本数 小簇数 簇大小均匀 层次聚类簇的数量…
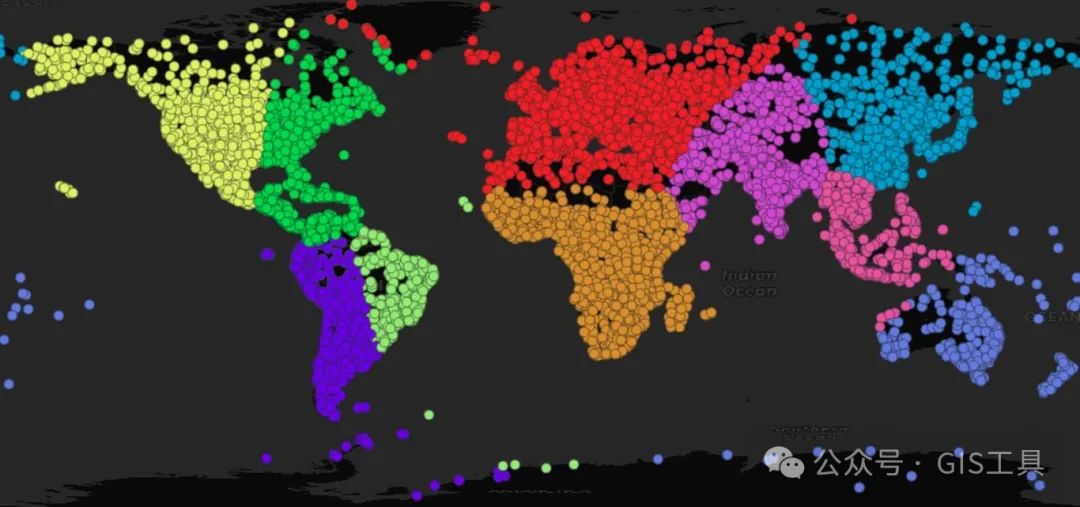
PostGIS 中的 K-Means 聚类操作及应用
K-Means算法: K-means 是数据科学和商业的基本算法。让我们深入了解一下。
1. K-means是一种流行的用于聚类的无监督机器学习算法。它是用于客户细分、库存分类、市场细分甚至异常检测的核心算法。
2. 无监督:K-means 是一种无监督算法,用于…
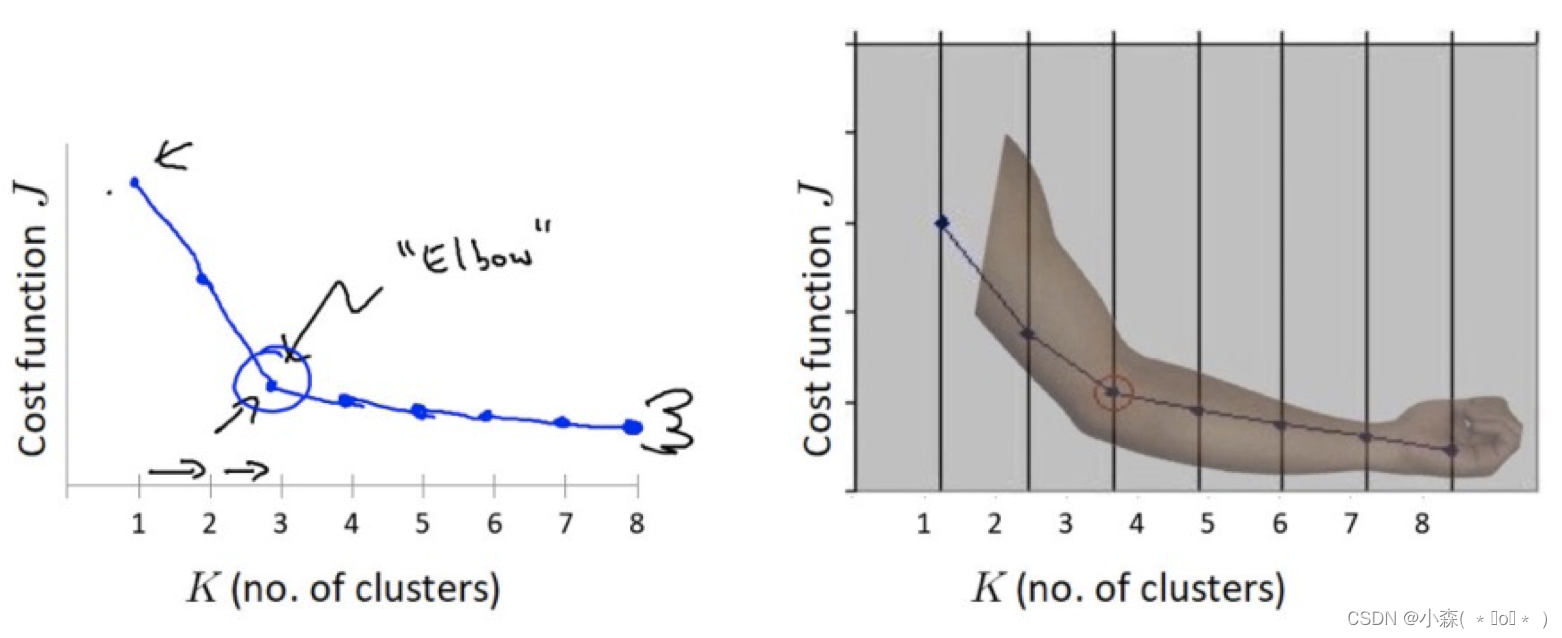
机器学习系列——(十七)聚类
引言
在当今数据驱动的时代,机器学习已经成为了解锁数据潜能的关键技术之一。其中,聚类作为机器学习领域的一个重要分支,广泛应用于数据挖掘、模式识别、图像分析等多个领域。本文旨在深入探讨聚类技术的原理、类型及其应用,为读…
机器学习系列——(十八)K-means聚类
引言
在众多机器学习技术中,K-means聚类以其简洁高效著称,成为了数据分析师和算法工程师手中的利器。无论是在市场细分、社交网络分析,还是图像处理等领域,K-means都扮演着至关重要的角色。本文旨在深入解析K-means聚类的原理、实…
【PCL】(二十八)超体素聚类分割点云
(二十九)超体素聚类分割点云
论文:Voxel Cloud Connectivity Segmentation - Supervoxels for Point Clouds
supervoxel_clustering.cpp
#include <pcl/console/parse.h>
#include <pcl/point_cloud.h>
#include <pcl/poin…
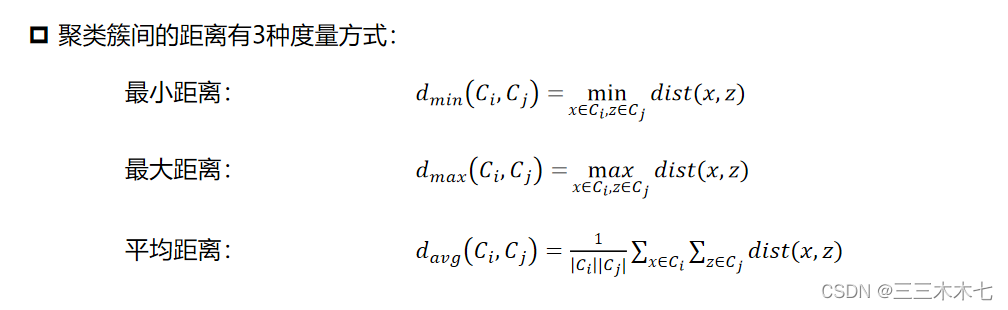
机器学习——聚类问题
📕参考:西瓜书ysu老师课件博客(3)聚类算法之DBSCAN算法 - 知乎 (zhihu.com) 目录
1.聚类任务 2.聚类算法的实现
2.1 划分式聚类方法
2.1.1 k均值算法
k均值算法基本原理:
k均值算法算法流程:
2.2 基于…

【机器学习笔记】12 聚类
无监督学习概述
监督学习 在一个典型的监督学习中,训练集有标签𝑦 ,我们的目标是找到能够区分正样本和负样本的决策边界,需要据此拟合一个假设函数。无监督学习 与此不同的是,在无监督学习中,我们的数据没…
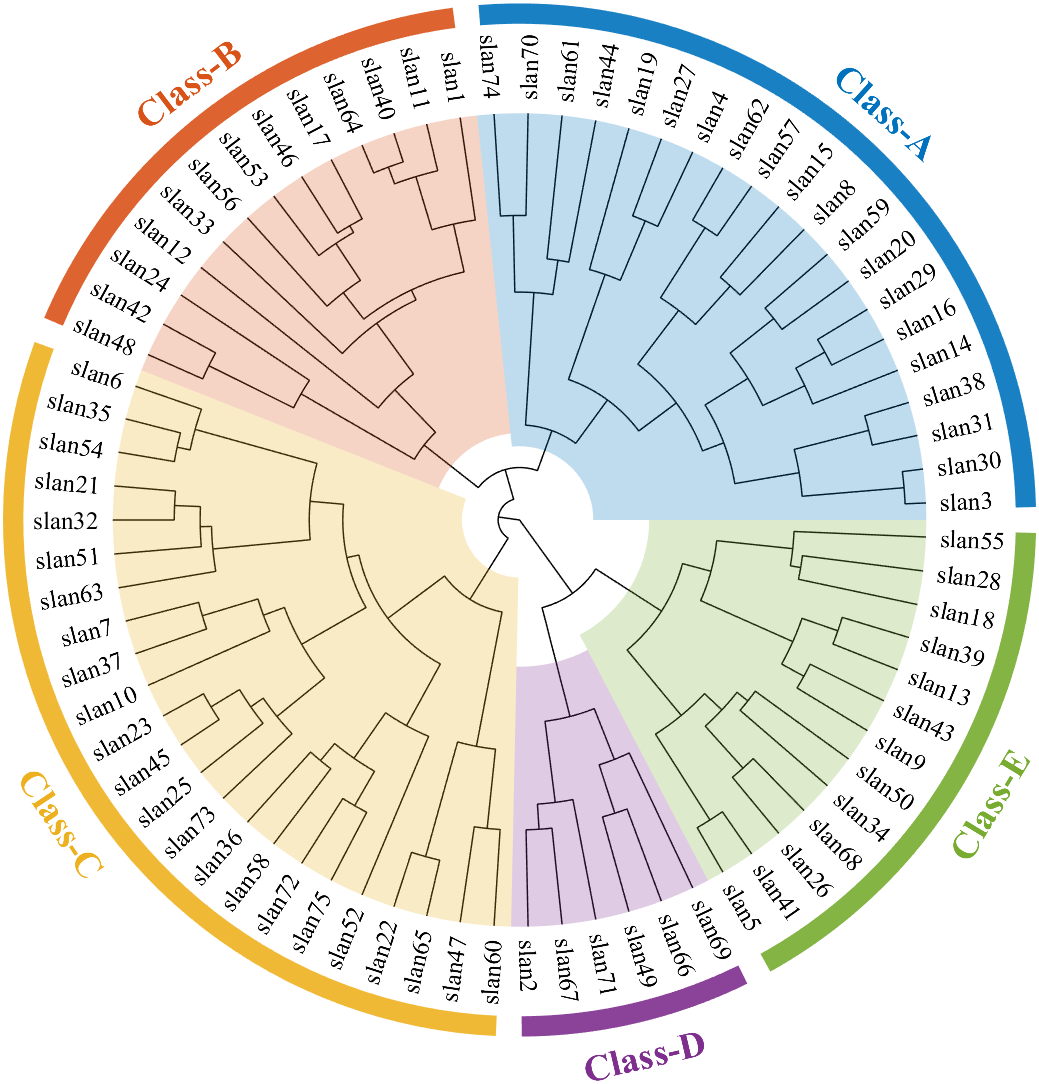
MATLAB | 绘图复刻(十五) | 环形聚类树状图
本期复刻效果: 感觉出的聚类分析树状图绘制工具也不少了,未来可能会统一整理为一个工具包?(任重道远,道阻且长): 代码讲解
0 数据设置
写了比较多的注释应该比较易懂:
clc; clear; close all% 样品起名s…
基于BERTopic模型的英文20新闻数据集主题聚类及可视化
文章目录 bertopic介绍20 newsgroups dataset20 newsgroups数据集下载数据导入nltk数据处理bertopic模型构建模型训练运行模型可视化目前主题的一致性得分语料库建模bertopic介绍
BERTopic 是基于深度学习的一种主题建模方法。BERT 是一种用于 NLP 的预训练策略,它成功地利用…

探索非监督学习:解决聚类问题
目录 1 非监督学习的概念1.1 非监督学习的定义1.2 非监督学习的重要性 2 聚类问题的定义和意义2.1 聚类问题的定义2.2 聚类问题的意义2.3 聚类问题在非监督学习中的地位 3 聚类算法介绍3.1 K均值聚类3.2 层次聚类3.3 密度聚类 4 聚类问题的评估4.1 内部评估指标4.2 外部评估指标…
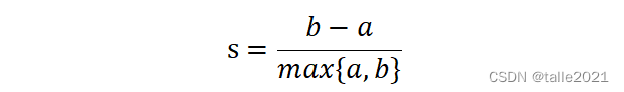
多元统计分析课程论文-聚类效果评价
数据集来源:Unsupervised Learning on Country Data (kaggle.com)
代码参考:Clustering: PCA| K-Means - DBSCAN - Hierarchical | | Kaggle
基于特征合成降维和主成分分析法降维的国家数据集聚类效果评价
目录
1.特征合成降维
2.PCA降维
3.K-Mean…

open3d k-means 聚类
k-means 聚类 一、算法原理1、介绍2、算法步骤 二、代码1、机器学习生成kmeans聚类2、点云学习生成聚类 三、结果1、原点云2、机器学习生成kmeans聚类3、点云学习生成聚类 四、相关链接 一、算法原理
1、介绍
K-means聚类算法是一种无监督学习算法,主要用于数据聚…
【经验分享】分类算法与聚类算法有什么区别?白话讲解
经常有人会提到这个问题,从我个人的观点和经验来说2者最明显的特征是:分类是有具体分类的数量,而聚类是没有固定的分类数量。
你可以想象一下,分类算法就像是给你一堆水果,然后告诉你苹果、香蕉、橙子分别应该放在哪里…
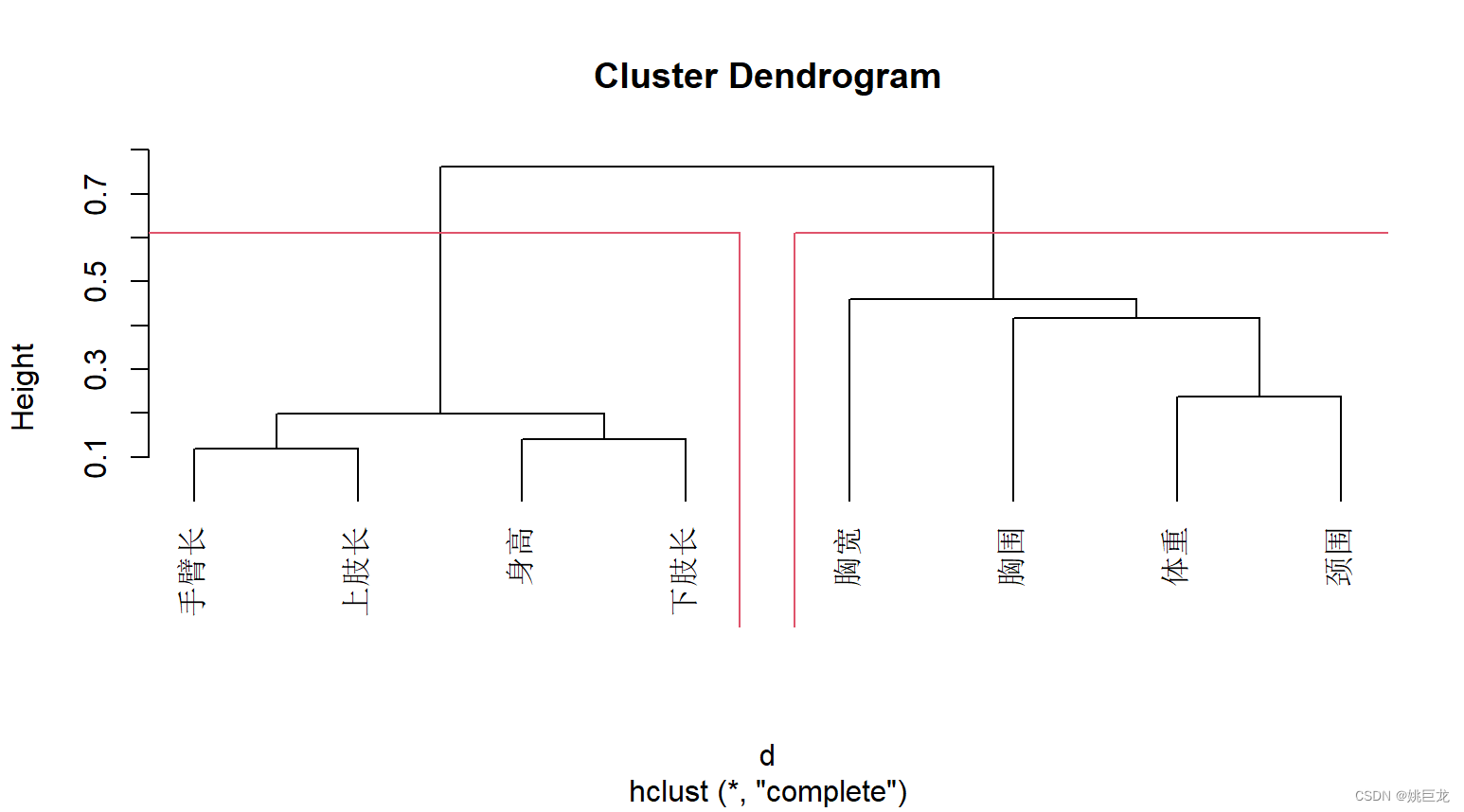
【统计分析数学模型】聚类分析
【统计分析数学模型】聚类分析 一、聚类分析1. 基本原理2. 距离的度量(1)变量的测量尺度(2)距离(3)R语言计算距离 三、聚类方法1. 系统聚类法2. K均值法 三、示例1. Q型聚类(1)问题描…

六、回归与聚类算法 - 欠拟合和过拟合
目录
1、定义
2、原因及解决方法
2.1 正则化 线性回归欠拟合与过拟合线性回归的改进 - 岭回归分类算法:逻辑回归模型保存与加载无监督学习:K-means算法
1、定义 2、原因及解决方法 2.1 正则化
Python-GIS分析之地理数据空间聚类
地理空间数据聚类是空间分析和地理信息系统(GIS)领域的一项关键技术。这种方法对于理解地理数据固有的空间模式和结构、促进城市规划、环境管理、交通和公共卫生等各个领域的决策过程至关重要。本文探讨了地理空间数据聚类的概念、方法、应用、挑战和未来方向。 当模式出现…

六、回归与聚类算法 - 岭回归
目录
1、带有L2正则化的线性回归 - 岭回归
1.1 API
2、正则化程度的变化对结果的影响
3、波士顿房价预测 线性回归欠拟合与过拟合线性回归的改进 - 岭回归分类算法:逻辑回归模型保存与加载无监督学习:K-means算法
1、带有L2正则化的线性回归 - 岭回…
【统计分析数学模型】聚类分析: 系统聚类法
【统计分析数学模型】聚类分析: 系统聚类法 一、聚类分析1. 基本原理2. 距离的度量(1)变量的测量尺度(2)距离(3)R语言计算距离 三、聚类方法1. 系统聚类法2. K均值法 三、示例1. Q型聚类&#x…
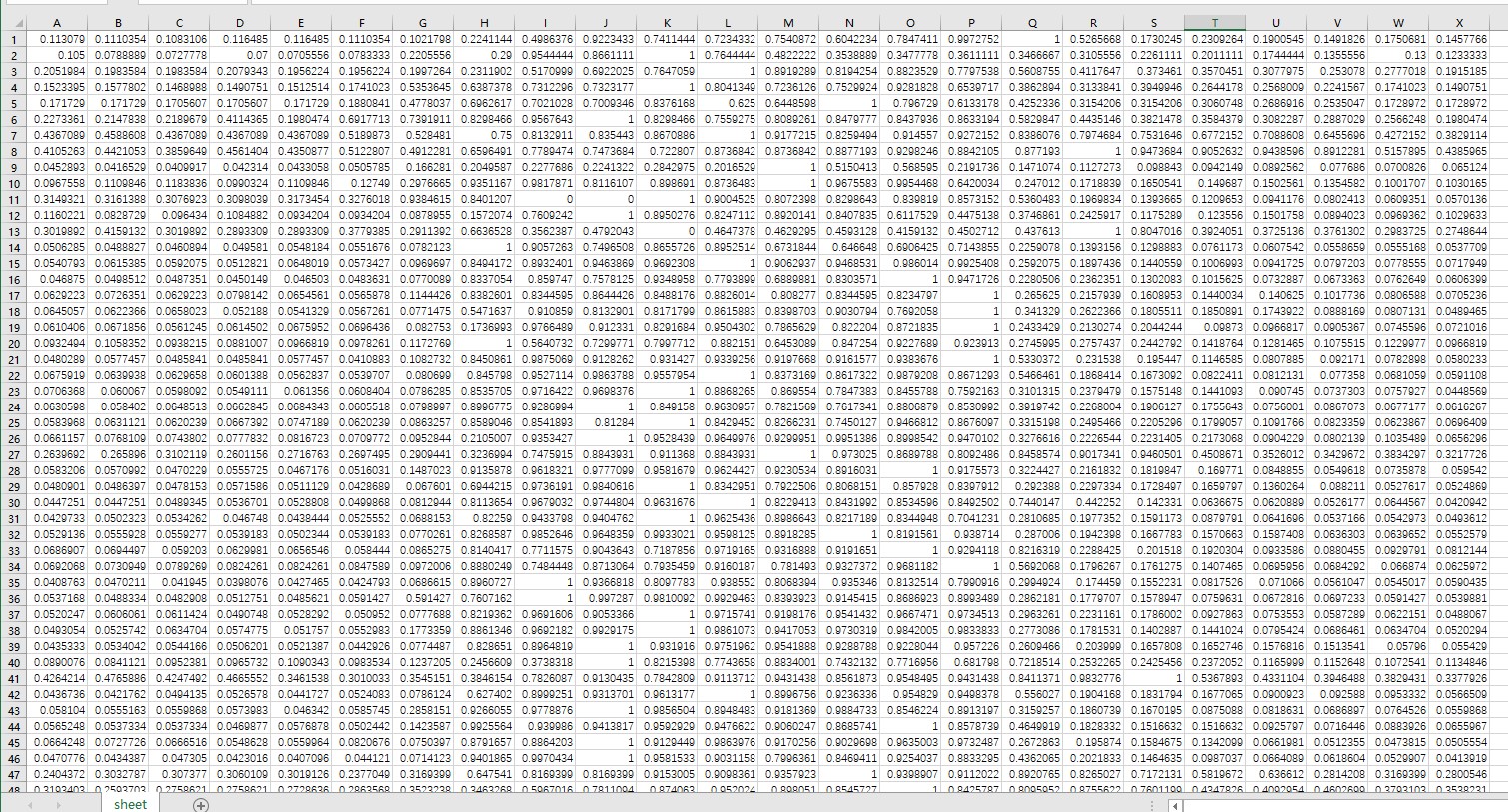
新!PCA+DBO+K-means聚类,蜣螂优化算法DBO优化K-means,适合学习,也适合发paper。
PCADBOK-means聚类,蜣螂优化算法DBO优化K-means,适合学习,也适合发paper。
一、 蜣螂优化算法
摘要:受蜣螂滚球、跳舞、觅食、偷窃和繁殖等行为的启发,提出了一种新的基于种群的优化算法(Dung Beetle Optimizer, DBO…
C#,人工智能,机器学习,聚类算法,训练数据集生成算法、软件与源代码
摘要:本文简述了人工智能的重要分支——机器学习的核心算法之一——聚类算法,并用C#实现了一套完全交互式的、可由用户自由发挥的,适用于聚类算法的训练数据集生成软件——Clustering。用户使用鼠标左键(拖动)即可生成任意形状,任意维度,任意簇数及各种数据范围的训练数…
R语言聚类分析-K均值聚类与系统聚类法
一、数据集为firm.csv,给出了22家美国公用事业公司的相关数据集,各数据集变量的名称和含义如下:X1为固定费用周转比(收入/债务),X2为资本回报率,X3为每千瓦容量成本,X4为年载荷因子&…
dbscan算法实现鸢尾花聚类(python实现)
DBscan算法原理 :
dbscan算法-CSDN博客
法一(调库) :
直接调库 :
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.cluster import DBSCAN
from sklearn.decomposition import PCA
from sklearn.discriminant_analysis …
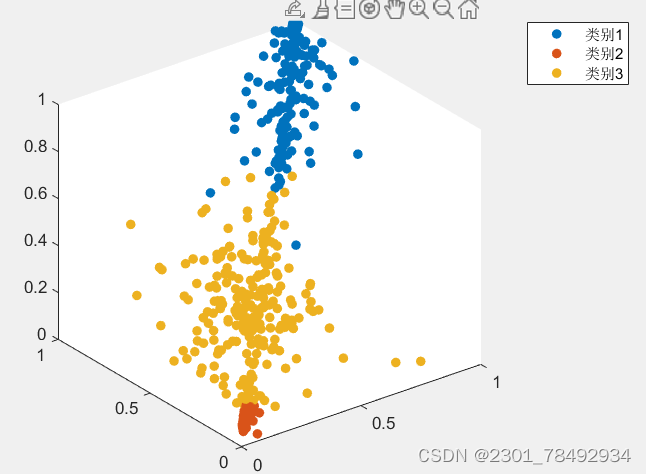
k-means聚类、GMM高斯聚类、canopy聚类、DBSCAN聚类、FCM聚类、ISODATA聚类、k-medoid聚类、层次聚类、谱聚类 对比
k-means聚类、GMM高斯聚类、canopy聚类、DBSCAN聚类、FCM聚类、ISODATA聚类、k-medoid聚类、层次聚类、谱聚类 对比 标 代码获取代码获取代码获取代码获取代码获取代码获取代码获取代码获取代码获取代码获取题 GMM(高斯混合模型)是一种聚类算法ÿ…
RIPGeo代码理解(六)main.py(运行模型进行训练和测试)
代码链接:RIPGeo代码实现 ├── preprocess.py # 预处理数据集并为模型运行执行IP聚类 ├── main.py # 运行模型进行训练和测试 ├── test.py #加载检查点,然后测试
一、导入各种模块和数据库 import torch.nnfrom lib.utils import *
import argparse
i…

机器学习——聚类算法-层次聚类算法
机器学习——聚类算法-层次聚类算法
在机器学习中,聚类是一种将数据集划分为具有相似特征的组或簇的无监督学习方法。聚类算法有许多种,其中一种常用的算法是层次聚类算法。本文将介绍聚类问题、层次聚类算法的原理、算法流程以及用Python实现层次聚类算…
探索LightGBM:监督式聚类与异常检测
导言
监督式聚类和异常检测是在监督学习框架下进行的一种特殊形式的数据分析技术。在Python中,LightGBM提供了一些功能来执行监督式聚类和异常检测任务。本教程将详细介绍如何使用LightGBM进行监督式聚类和异常检测,并提供相应的代码示例。
监督式聚类…
使用Python进行Sentinel-2 图像聚类
聚类或无监督分类是根据统计相似性将图像的像素值分组或聚合到一定数量的自然类(组)的过程。在本教程中,我们将使用rasterio进行sentinel-2图像处理,并使用功能强大的完整scikit-learn python 包在jupyter Notebook中进行聚类。
Scikit-learn是一个用于 Python 编程语言的…
【机器学习基础】层次聚类-BIRCH聚类
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!相对完整的机器学习基础教学! ⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战…
MATLAB环境下基于偏置场校正的改进模糊c-均值聚类图像分割算法
基于聚类的分割方法是以统计学为基础提出的一种分割方法。其实质是通过计算像素与每一类聚类中心的欧氏距离来判定像素与每一类聚类中心的相似性,距离近就说明像素与聚类中心相似性大,反之相似性小。基于一定标准下的相似性自动划分成若干个子集(类)&…

信息检索与数据挖掘 | (十二)聚类
文章目录 📚聚类📚KMeans📚层次聚类🐇层次聚类概述🐇dendrogram-树状图🐇linkages-衡量两个类之间的距离🐇Lance-Williams算法🐇K-means VS 层次聚类 📚DBSCAN …
全球名校AI课程库(28)| MIT麻省理工 · 基因组学机器学习课程『Machine Learning for Genomics』
🏆 课程学习中心 | 🚧 AI生物医疗课程合辑 | 🌍 课程主页 | 📺 中英字幕视频 | 🚀 项目代码解析 课程介绍
MIT 6.047/6.878是全球顶校麻省理工开设的基因组学与机器学习的交叉专业课程。课程以基因组学为主要应用领域…
Python人工智能——向量机,聚类
支持向量机(SVM)
支持向量机原理 寻求最优分类边界 正确:对大部分样本可以正确地划分类别。 泛化:最大化支持向量间距。 公平:与支持向量等距。 简单:线性,直线或平面,分割超平面。 基于核函数的升维变换…
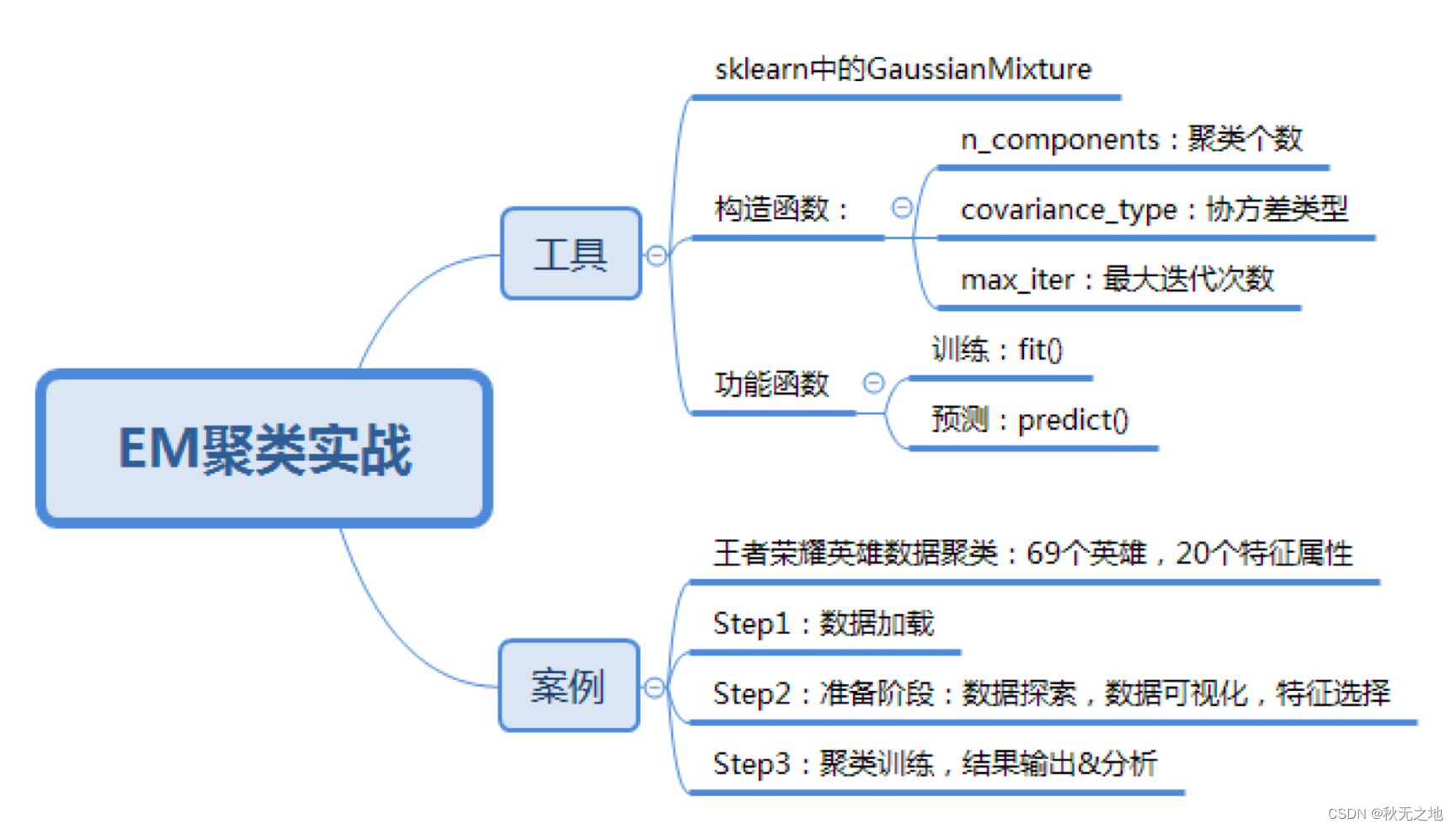
EM聚类(下):用EM算法对王者荣耀英雄进行划分
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…
【聚类 | K-means】原理及推导流程(附模板代码,库手撕实现)
🤵♂️ 个人主页: AI_magician 📡主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。 👨💻景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!&…
机器学习系列——(十九)层次聚类
引言
在机器学习和数据挖掘领域,聚类算法是一种重要的无监督学习方法,它试图将数据集中的样本分组,使得同一组内的样本相似度高,不同组间的样本相似度低。层次聚类(Hierarchical Clustering)是聚类算法中的…